# UTF-8
import os
# 复制操作 及 异常处理
import sys
from shutil import copyfile
from sys import exit
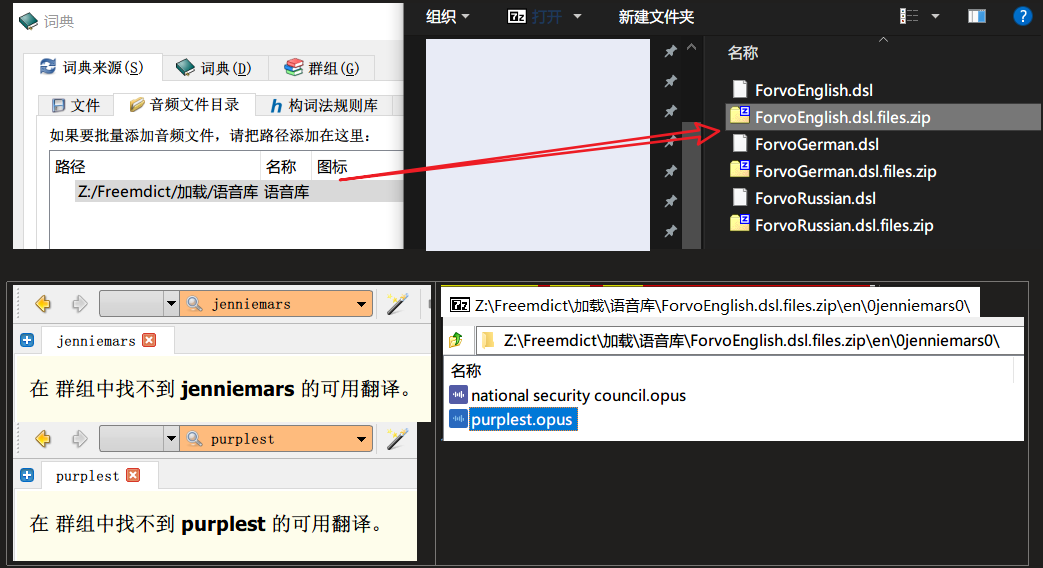
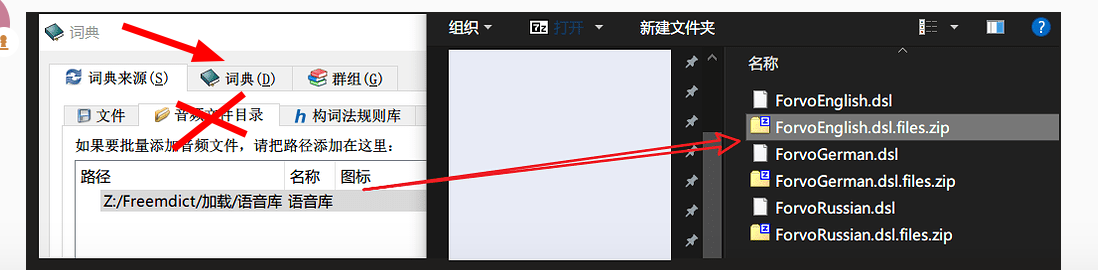
# 使用绝对路径,指定语言代码后,将 opus 目录下的文件复制到 DSL 目录下。
Language_I_want = ['ja','de']
opus_dir = r"\0 Forvo audio\opus"
ForvoDSL_dir = r"\0 Forvo audio\dsl files (by Svirepov)\ForvoDSL (May 14, 2022)\ForvoDSL\ForvoDSL-20220513"
# 常量: 语言代码 - 字典
# 与 DSL 不一定匹配,因为有空格。
result={'abq': 'Abaza', 'ab': 'Abkhazian', 'abn': 'Abua', 'ady': 'Adygean', 'aa': 'Afar', 'af': 'Afrikaans', 'agx': 'Aghul', 'ain': 'Ainu', 'ak': 'Akan', 'sq': 'Albanian', 'ale': 'Aleut', 'arq': 'Algerian Arabic', 'alq': 'Algonquin', 'ems': 'Alutiiq', 'am': 'Amharic', 'grc': 'Ancient Greek', 'ar': 'Arabic', 'an': 'Aragonese', 'arp': 'Arapaho', 'aae': 'Arbëresh', 'hy': 'Armenian', 'rup': 'Aromanian', 'as': 'Assamese', 'aii': 'Assyrian Neo-Aramaic', 'ast': 'Asturian', 'av': 'Avaric', 'ay': 'Aymara', 'az': 'Azerbaijani', 'bqi': 'Bakhtiari', 'bal': 'Balochi', 'bm': 'Bambara', 'bcj': 'Bardi', 'ba': 'Bashkir', 'eu': 'Basque', 'bar': 'Bavarian', 'be': 'Belarusian', 'bem': 'Bemba', 'bcq': 'Bench', 'bn': 'Bengali', 'bho': 'Bhojpuri', 'hbo': 'Biblical Hebrew', 'bh': 'Bihari', 'bi': 'Bislama', 'fla': 'Bitterroot Salish', 'bs': 'Bosnian', 'bph': 'Botlikh', 'pcc': 'Bouyei', 'br': 'Breton', 'bzd': 'Bribri', 'bg': 'Bulgarian', 'my': 'Burmese', 'bsk': 'Burushaski', 'bxr': 'Buryat', 'sro': 'Campidanese', 'yue': 'Cantonese', 'kea': 'Cape Verdean Creole', 'ca': 'Catalan', 'cay': 'Cayuga', 'ceb': 'Cebuano', 'tzm': 'Central Atlas Tamazight', 'bcl': 'Central Bikol', 'ch': 'Chamorro', 'plig': 'Changzhou', 'ce': 'Chechen', 'cpn': 'Cherepon', 'chr': 'Cherokee', 'ny': 'Chichewa', 'cic': 'Chickasaw', 'chn': 'Chinook Jargon', 'cho': 'Choctaw', 'cv': 'Chuvash', 'rar': 'Cook Islands Maori', 'cop': 'Coptic', 'kw': 'Cornish', 'co': 'Corsican', 'cr': 'Cree', 'mus': 'Creek', 'crh': 'Crimean Tatar', 'hr': 'Croatian', 'acy': 'Cypriot Arabic', 'cs': 'Czech', 'dag': 'Dagbani', 'ada': 'Dangme', 'da': 'Danish', 'prs': 'Dari', 'din': 'Dinka', 'dv': 'Divehi', 'siiy': 'Doumen Hua', 'dtp': 'Dusun', 'nl': 'Dutch', 'dz': 'Dzongkha', 'bin': 'Edo', 'arz': 'Egyptian Arabic', 'ekp': 'Ekpeye', 'egl': 'Emilian', 'en': 'English', 'myv': 'Erzya', 'eo': 'Esperanto', 'et': 'Estonian', 'eto': 'Eton', 'ett': 'Etruscan', 'evn': 'Evenki', 'ee': 'Ewe', 'ewo': 'Ewondo', 'fo': 'Faroese', 'hif': 'Fiji Hindi', 'fj': 'Fijian', 'fi': 'Finnish', 'vls': 'Flemish', 'frp': 'Franco-Provençal', 'fr': 'French', 'fy': 'Frisian', 'fur': 'Friulan', 'ff': 'Fulah', 'fzho': 'Fuzhou', 'gaa': 'Ga', 'gag': 'Gagauz', 'gl': 'Galician', 'gan': 'Gan Chinese', 'ka': 'Georgian', 'de': 'German', 'glk': 'Gilaki', 'gil': 'Gilbertese', 'got': 'Gothic', 'el': 'Greek', 'gn': 'Guarani', 'gu': 'Gujarati', 'afb': 'Gulf Arabic', 'guz': 'Gusii', 'ht': 'Haitian Creole', 'hak': 'Hakka', 'mey': 'Hassaniyya', 'ha': 'Hausa', 'haw': 'Hawaiian', 'he': 'Hebrew', 'hz': 'Herero', 'hil': 'Hiligaynon', 'hi': 'Hindi', 'ho': 'Hiri motu', 'hmn': 'Hmong', 'hop': 'Hopi', 'hu': 'Hungarian', 'is': 'Icelandic', 'io': 'Ido', 'ig': 'Igbo', 'ilo': 'Iloko', 'ind': 'Indonesian', 'inh': 'Ingush', 'ia': 'Interlingua', 'ie': 'Interlingue', 'iu': 'Inuktitut', 'ik': 'Inupiaq', 'ga': 'Irish', 'it': 'Italian', 'ibd': 'Iwaidja', 'jam': 'Jamaican Patois', 'ja': 'Japanese', 'jv': 'Javanese', 'jje': 'Jeju', 'jliu': 'Jiaoliao Mandarin', 'jlua': 'Jilu Mandarin', 'cjy': 'Jin Chinese', 'lad': 'Judeo-Spanish', 'kbd': 'Kabardian', 'kab': 'Kabyle', 'kl': 'Kalaallisut', 'kln': 'Kalenjin', 'xal': 'Kalmyk', 'kn': 'Kannada', 'kr': 'Kanuri', 'krc': 'Karachay-Balkar', 'kaa': 'Karakalpak', 'krl': 'Karelian', 'ks': 'Kashmiri', 'csb': 'Kashubian', 'kk': 'Kazakh', 'kca': 'Khanty', 'kha': 'Khasi', 'km': 'Khmer', 'ki': 'Kikuyu', 'kmb': 'Kimbundu', 'rw': 'Kinyarwanda', 'rn': 'Kirundi', 'tlh': 'Klingon', 'kv': 'Komi', 'koi': 'Komi-Permyak', 'kg': 'Kongo', 'gom': 'Konkani', 'ko': 'Korean', 'kpy': 'Koryak', 'avk': 'Kotava', 'kri': 'Krio', 'kj': 'Kuanyama', 'ku': 'Kurdish', 'kmr': 'Kurmanji', 'kfr': 'Kutchi', 'ky': 'Kyrgyz', 'quc': 'Kʼicheʼ', 'lld': 'Ladin', 'lbe': 'Lak', 'lki': 'Laki', 'lkt': 'Lakota', 'lo': 'Lao', 'ltg': 'Latgalian', 'la': 'Latin', 'lv': 'Latvian', 'lzz': 'Laz', 'lez': 'Lezgian', 'lij': 'Ligurian', 'li': 'Limburgish', 'ln': 'Lingala', 'lt': 'Lithuanian', 'jbo': 'Lojban', 'lmo': 'Lombard', 'lou': 'Louisiana Creole', 'nds': 'Low German', 'juai': 'Lower Yangtze Mandarin', 'loz': 'Lozi', 'lu': 'Luba-katanga', 'lg': 'Luganda', 'luo': 'Luo', 'lut': 'Lushootseed', 'lb': 'Luxembourgish', 'mk': 'Macedonian', 'mag': 'Magahi', 'bfz': 'Mahasu Pahari', 'vmf': 'Mainfränkisch', 'mak': 'Makassarese', 'mg': 'Malagasy', 'ms': 'Malay', 'ml': 'Malayalam', 'zsm': 'Malaysian', 'mt': 'Maltese', 'mnc': 'Manchu', 'zh': 'Mandarin Chinese', 'mnk': 'Mandinka', 'mns': 'Mansi', 'gv': 'Manx', 'swb': 'Maore', 'mi': 'Māori', 'arn': 'Mapudungun', 'mr': 'Marathi', 'chm': 'Mari', 'mh': 'Marshallese', 'msb': 'Masbateño', 'mfe': 'Mauritian Creole', 'myn': 'Mayan languages', 'mzn': 'Mazandarani', 'mfo': 'Mbe', 'gun': 'Mbya Guarani', 'mni': 'Meitei', 'pdt': 'Mennonite Low German', 'apm': 'Mescalero-Chiricahua', 'acm': 'Mesopotamian Arabic', 'crg': 'Michif', 'mic': 'Micmac', 'ltc': 'Middle Chinese', 'enm': 'Middle English', 'cdo': 'Min Dong', 'nan': 'Min Nan', 'min': 'Minangkabau', 'xmf': 'Mingrelian', 'lrc': 'Minjaee Luri', 'moh': 'Mohawk', 'mdf': 'Moksha', 'mo': 'Moldovan', 'mn': 'Mongolian', 'ary': 'Moroccan Arabic', 'mos': 'Mossi', 'wlc': 'Mwali', 'mwn': 'Mwanga', 'nah': 'Nahuatl', 'nsk': 'Naskapi', 'na': 'Nauru', 'nv': 'Navajo', 'ppl': 'Nawat', 'nxq': 'Naxi', 'ng': 'Ndonga', 'wni': 'Ndzwani', 'nap': 'Neapolitan', 'new': 'Nepal Bhasa', 'ne': 'Nepali', 'zdj': 'Ngazidja', 'yrl': 'Nheengatu', 'nog': 'Nogai', 'apc': 'North Levantine Arabic', 'nd': 'North Ndebele', 'sme': 'Northern Sami', 'no': 'Norwegian', 'nn': 'Norwegian Nynorsk', 'ii': 'Nuosu', 'ngh': 'Nǀuu', 'ann': 'Obolo', 'obu': 'Obulom', 'oc': 'Occitan', 'ogb': 'Ogbia', 'oj': 'Ojibwa', 'oka': 'Okanagan', 'ryu': 'Okinawan', 'ang': 'Old English', 'non': 'Old Norse', 'otk': 'Old Turkic', 'or': 'Oriya', 'om': 'Oromo', 'osa': 'Osage', 'os': 'Ossetian', 'ota': 'Ottoman Turkish', 'pbb': 'Páez', 'pau': 'Palauan', 'pln': 'Palenquero', 'pi': 'Pali', 'pam': 'Pampangan', 'pag': 'Pangasinan', 'pap': 'Papiamento', 'ps': 'Pashto', 'paw': 'Pawnee', 'pdc': 'Pennsylvania Dutch', 'fa': 'Persian', 'pcd': 'Picard', 'pms': 'Piedmontese', 'pjt': 'Pitjantjatjara', 'pl': 'Polish', 'pt': 'Portuguese', 'pot': 'Potawatomi', 'cpx': 'Pu-Xian Min', 'fuc': 'Pulaar', 'pa': 'Punjabi', 'qxq': 'Qashqai', 'fre': 'Quebec French', 'qu': 'Quechua', 'qya': 'Quenya', 'zpf': 'Quiatoni Zapotec', 'rap': 'Rapa Nui', 'rcf': 'Reunionese Creole', 'rhg': 'Rohingya', 'rgn': 'Romagnol', 'rom': 'Romani', 'ro': 'Romanian', 'rm': 'Romansh', 'cgg': 'Rukiga', 'ru': 'Russian', 'rue': 'Rusyn', 'ksw': "S'gaw Karen", 'skg': 'Sakalava', 'sm': 'Samoan', 'sg': 'Sango', 'sa': 'Sanskrit', 'skr': 'Saraiki', 'sc': 'Sardinian', 'sco': 'Scots', 'gd': 'Scottish Gaelic', 'trv': 'Seediq', 'sr': 'Serbian', 'srr': 'Serer', 'shn': 'Shan', 'jusi': 'Shanghainese', 'shi': 'Shilha', 'sn': 'Shona', 'shh': 'Shoshone', 'sty': 'Siberian Tatar', 'scn': 'Sicilian', 'szl': 'Silesian', 'sli': 'Silesian German', 'sjn': 'Sindarin', 'sd': 'Sindhi', 'si': 'Sinhalese', 'sk': 'Slovak', 'sl': 'Slovenian', 'xog': 'Soga', 'so': 'Somali', 'snk': 'Soninke', 'st': 'Sotho', 'nr': 'South Ndebele', 'luz': 'Southern Luri', 'xghu': 'Southwestern Mandarin', 'es': 'Spanish', 'srn': 'Sranan Tongo', 'su': 'Sundanese', 'swg': 'Swabian German', 'sw': 'Swahili', 'ss': 'Swati', 'sv': 'Swedish', 'gsw': 'Swiss German', 'syl': 'Sylheti', 'syc': 'Syriac', 'tl': 'Tagalog', 'ty': 'Tahitian', 'taiu': 'Taihu Wu', 'tvx': 'Taivoan', 'tg': 'Tajik', 'tzl': 'Talossan', 'tly': 'Talysh', 'ta': 'Tamil', 'tt': 'Tatar', 'te': 'Telugu', 'tet': 'Tetum', 'tcz': 'Thadou', 'th': 'Thai', 'tjin': 'Tianjin', 'bo': 'Tibetan', 'ti': 'Tigrinya', 'tli': 'Tlingit', 'tisa': 'Toisanese Cantonese', 'tpi': 'Tok Pisin', 'tok': 'Toki Pona', 'tdn': 'Tondano', 'toi': 'Tonga', 'to': 'Tongan', 'ts': 'Tsonga', 'tn': 'Tswana', 'tmh': 'Tuareg', 'yrk': 'Tundra Nenets', 'aeb': 'Tunisian Arabic', 'tr': 'Turkish', 'tk': 'Turkmen', 'tus': 'Tuscarora', 'tyv': 'Tuvan', 'tw': 'Twi', 'uby': 'Ubykh', 'udm': 'Udmurt', 'uk': 'Ukrainian', 'sxu': 'Upper Saxon', 'hsb': 'Upper Sorbian', 'ur': 'Urdu', 'ug': 'Uyghur', 'uz': 'Uzbek', 've': 'Venda', 'vec': 'Venetian', 'vep': 'Veps', 'vi': 'Vietnamese', 'vo': 'Volapük', 'vro': 'Võro', 'wa': 'Walloon', 'cy': 'Welsh', 'qjio': 'Wenzhounese', 'apw': 'Western Apache', 'wo': 'Wolof', 'wuu': 'Wu Chinese', 'xh': 'Xhosa', 'hsn': 'Xiang Chinese', 'sah': 'Yakut', 'yey': 'Yeyi', 'yi': 'Yiddish', 'yo': 'Yoruba', 'yua': 'Yucatec Maya', 'esu': 'Yupik', 'zza': 'Zazaki', 'za': 'Zhuang', 'zu': 'Zulu'}
fileList = os.listdir(opus_dir)
for file in fileList:
file_suffix = os.path.splitext(file)[-1]
origin_name = os.path.splitext(file)[0]
if (file_suffix == '.zip') & (origin_name in Language_I_want):
target_name = 'Forvo' + result[origin_name] + '.dsl.files.zip'
# os.rename(file, target_name)
print("copy ", target_name)
source = os.path.join(opus_dir, file)
target = os.path.join(ForvoDSL_dir, target_name)
try:
copyfile(source, target)
except IOError as e:
print("Unable to copy file. %s" % e)
exit(1)
except:
print("Unexpected error:", sys.exc_info())
exit(1)
print("\nFile copy done!\n")