谢谢指谬,小问题肯定还有不少,等积累到一定程度统一处理吧。
2 个赞
上面提到把 “牛津现代英汉双解词典”(COD 9)转成html或者txt,html有格式,可读性佳,但这个文件体量稍大,转成html使用起来也不方便,text文本会好一些,起码能全文搜索,勉强也能读。
提取COD9的文本很简单,用正则即可,我用的底本来自 牛津现代英汉双解V1 正式发布 (全中英切换版, 复查错误; 2020-05-28更新 END : ) ,谢谢原作者的辛苦制作,现把提取出来的plain文本贴到这里。
cod9-plain.txt (16.8 MB)
其实我想问问,使用 TXT 格式的原因是什么,只是为了全文搜索吗?
《21世纪英汉词典》也可以提取为plain文本(其实正是我制作此mdx的主要目的之一),由于尚未完善,最终结果暂时就不上传了,贴一下自己写的script吧,供感兴趣的人自行提取。
#! /usr/bin/env python
# -*- coding: utf-8 -*-
""" 《21世纪英汉词典》纯文本文件提取 """
import re
file_src = r'C:\Users\vivo\Desktop\21世纪英汉词典.txt'
file_dst = r'C:\Users\vivo\Desktop\21世纪英汉词典-Plain.txt'
def main():
with open(file_src, 'r', encoding='UTF-8') as f:
full_text = f.read()
modified_text = re.sub(r'</>\n.*?\n<link href=', '</>\n<link href=', full_text) #删除索引词头
entry_list = modified_text.split('</>')
temp_list = []
for entry in entry_list:
clean_txt = re.sub(r'<[^>]*>', '', entry) #删除所有html标签
del_blank_txt = ' '.join([s for s in clean_txt.splitlines() if s]) #去除空行
temp_list.append(del_blank_txt)
whole_text = '\n'.join(temp_list)
with open(file_dst, 'w', encoding='UTF-8') as f_out:
f_out.write(whole_text + '\n')
if __name__ == '__main__':
main()

1 个赞
全文搜索是一个原因,也是用来读的,5万左右及以下词汇表(或简单释义的双解文本)是可以通读的,熟悉的词汇快速放过,生僻的词汇留意或者做标记/笔记,下次再读,只看做过标记或笔记的词汇即可。
还有一个用途是程序处理,比如用cod9给某个生词列表自动生成注音、释义等,网络上已有的那些所谓英汉词典数据库太不靠谱。
1 个赞
哈哈,不过通读词汇表或者词典要找适合自己当前词汇水平的,比自己的词汇量稍大一些比较恰当,一个高中生通读cod是自寻苦头了,英语母语者可以试试,就像中文母语者通读《现代汉语词典》,其实不是什么mission impossible。
1 个赞
谢谢你的源码,很好的学习英语的方法。
1 个赞
如果能把短语完整提取出来就更好啦。新年快乐


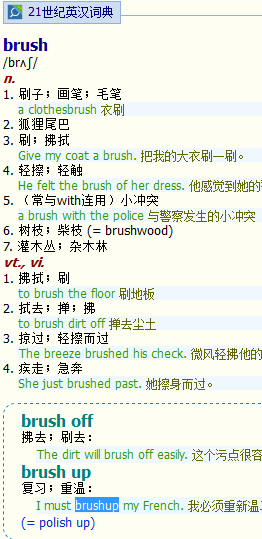


建议每个例句前面加一个标志以示区分
1 个赞
你难道不会查just?brushup粘连的问题前面已经有人说了。
1 个赞
短语归属于headword,见到短语、词组,应该去查其主词,如果连这种最基本的分析能力都不具备,学习英语的前景堪忧。
我比较厌烦什么提取词组版mdx,特别那些注水大量用衍生词扩充索引词头的,这种mdx一般不用,实在非用不可,我第一件要做的事就是解开把 @@@LINK = 的词条全部删除。提取词组、@@@LINK = 词条问题主要有四:1)貌似方便了用户,其实侮辱了使用者的智商;2)它错误地假设了别人好像只有一部词典,这里查不到,未必其他大型词典也查不到;3)扰乱了真实的收录词条统计,这在我看来有重要意义;4)不符合软件业“dry”的原则,底层数据重复冗余,特别我个人常常是把mdx清洗成plain文本用的,底层数据脏,清除起来麻烦。
如果实在有提取词组这种特别需求,呵呵,建议自己动手,丰衣足食。
1 个赞
又更新了。
2022-01-02日改正版
1)修复30余处词组错位等;
2)释义中不匹配的半角括号改为全角;
3)改正mdictfan提出的单词粘连问题。
修复单词列表:
better bugger chat choke clean climb clock concrete contract count crank crop curl dream drum eat exchange exclusive eyeball feed flake free fuck hole howl hush light map muck nail next pluck thank that
4 个赞
此文档毛病比我设想得要多,以下词汇继续需要修正,主要是gram内容和前导解释(比如“〈法〉”)误窜入definition,导致释义的顺序编号不对。看看有没有别的问题,一起修改后再打包。
ablution / attribute / avert / bail / billet / blues / brick / conformable / conk / consign / contribute / contrast / cork / credential / crossroad / deprive / depute / destine / detract / disagree / doldrums / eke / elect / electronics / expatriate / exposure / fain / fawn / firstfruit / fob / -form / furbish / glimpse / glory / grapple / his / impervious / incidental / indicate / inflict / insensitive / insight / insist / insomuch / intrude / jack / junior / knee-deep / lam / last word / lineament / liven / Lords / luxuriate / mechanics / Met / miscellany / mooring / need / pander / peel / perk / plaudit / pore / prowl / rebel / refer / relapse / remedy / resort / rite of passage / scrunch / seem / semantics / silver screen / siphon / skirt / slow / smarten / somebody / soup / spat / substitute / sum / suss / taint / teem / tinge / truckle / vouch / well-advised /
/ acacia / a deux / aldehyde / assignee / bandicoot / baryta / Cainozoic / Case / cell division / cervical / cystic / diapason / Dog Star / gallinaceous / gillyflower / ilex / inductance / ixia / litany / local train / Methodism / midfield / ouzel / ritardando / scumbag / sec / secant / soffit / tit / twat / tympanum / wog
5 个赞
词典再次更新。
2022-01-06日校正版
1)在MDict中再次通读词典,修复数百处细节错误;
2)中文例句翻译中的半角字符修正为全角;
3)删除中英文例句中赘余的引号
此次更新之后,可以保证mdx词典内已经没有major problems,因为各种毛病层出不穷,我不得不再次通读词典,用的方法是在MDict中一个个词条翻,而不是上次采用的在chrome浏览器中速览,又发现了不下百余处错误。合并上帖中新发现的错误,总共手工修正的地方达数百之多,这还不包括通改的标点符号等。
不断校改,搞得我很烦躁,也比较累,又因为剩余的谬误应该比较少,我打算改用新的方式修正,即贴在github( GitHub - mahavivo/english-dictionary: english dictionary database )追踪修改过程,别人感兴趣的话,也可以参与。
6 个赞
这么一本小破词典,在电子辞书的世界里可以说没什么立足之地,收词量不足,没有地道的英文解释,例句也匮乏,不过,它也算渊源有自,师出名门了,其前身其实是外研社1990年第1版的《现代英汉词典》,《21世纪英汉词典》的主编梁德润、郑建德正是《现代英汉词典》的编者之一,在这里贴几张图:





《21世纪英汉词典》已经绝版,而外研社《现代英汉词典》新版本也改得面目全非,修正制作此电子版,算是给其续命,或者起死回生了,在另一层面,我觉得它可以是制作一个中等程度简明英汉词典数据库的优良基础,我们接过手来继续改进和完善(版权问题再议,或者可以将其限定为个人非商业使用)。
6 个赞
初步谈一下上面所述中型英汉词典数据库的构想:
1、它的基本版收词量大概在6-7万之间。此一数据不算空穴来风,去观察一下,牛津简明英语词典(COD),《现代汉语词典》,日本的《三省堂国语辞典》、《明解国语辞典》和《岩波国语辞典》,法国的《Le Petit Robert》,《朗氏德汉双解大词典》,收词量全部落在6-8万这个区间,说明无论你的母语是什么,这一量级的词汇量对普通人应付学习、工作、生活来说是足够了,或者绰绰有余。
2、数据库编修的基础选定为《21世纪英汉词典》,原因有好几个:a)它是绝版的词典,不与那些现售的词典发生利益冲突;b)文本数据是现成的,相对准确,只需要略微整理校改;c)其释义风格简明精炼,适合快速参考;d)收词量中等程度,便于扩充,我个人认为编词典增词容易删词难。
3、有了基础文本,下一步的任务是改进完善,主要有下列工作可做:
i)补充失收“备考”词条。把那些中考词汇、高考词汇、四六级词汇表、研究生入学词汇、专业英语四八级词汇、托福/GRE词汇都找来,程序扫一遍,凡遗漏了的都予以添加。
ii)适当补充BNC、COCA这些大规模语料库中词频排名在20000以上的词汇。
iii)《牛津高阶英汉双解词典》某一版本中的全部词头(headword)予以收录,还可以考虑《朗文当代》、“柯林斯”这些学习词典的词头数据。
iv)是否继续把词条收录扩展到COD(牛津简明)待议,也看前面的工作进行得如何,比如已经有60000词头了,再扩大可能会超标超纲。
v)补充词条时的注音、释义力求准确有据,注明出处,像从《牛津高阶》补充收录的词条直接用原始的中文释义即可。
vi)从不同来源增补词汇,难免有体例不一致的地方,比如有的词典分vi.、vt.,有的只标verb。先收录进来,再集中校改,统一体例。
vii)某些其他词典来源词条释义过详过繁,在注明来源的基础上参考另外的辞书予以删改。
viii)数据库词目基本完备之后,可以开始对词条释义予以校订,这是一个长期的工作,力求最终有独立、开放的版权。同时也可以适度删除、增补某些词条,但必须有足够理据。
4、在“基本版”英汉词典数据库的基础上,继续搞扩大版,10万词版,15万词版,20万词版。扩大版的词头依据应该是某一著名词典,注音、释义来源择良而从,因为自6万以上增收的词汇基本都是生僻单词或者专业词汇,其中文释义基本是固定的,也谈不上太多谁抄袭谁。octogen总是翻译为奥克托今,pachycephalosaur总是“肿头龙”而不是“胖头龙”。
5、数据库扩大的原则是宁缺毋滥,例如编修者如果不能把从6万扩充到10万所增加的4万个词条通读校阅一遍,那就不应该搞这个所谓的扩大版。
7 个赞
“在MDict中再次通读词典”?
楼主的意思是把整本书一字不漏的看一遍?
