顺便报告一下mdx修正的进度,把多余的会重复出现的headword类删除了。计划对丢失phrase类的词头予以补充,却发现原始词典的问题很多,释义重复,词组呈现位置错误,独立词头误合并等,基本无法通过编程解决,于是只好在Mdict里一个个单词快速通读,比较慢也很枯燥乏味。
目前找到有问题的词条有(1/10的总量):
zoom
ye
X-ray
wrong
wrap
with
wind
warn
accidental
adapt
adulterate
advertise
affect
after one’s own heart
AM
anaerobic
angry
art
artistic
as
audio-visual
back
bale
ball
bang
bankrupt
beat
Beaufort scale
Beaujolais
become
better
bill of fare
bill of health
bind
blink
blow
boil
Boston
bow
break
bring
buck
build
bump
bung
burn
butt
butter
buy
buzz
by halves
Byzantine
CAAC
camp
canon
cast
11 个赞
MDict中一个个单词翻效率太低,决定分批转换成html在chrome里用鼠标滚轮浏览。
2 个赞
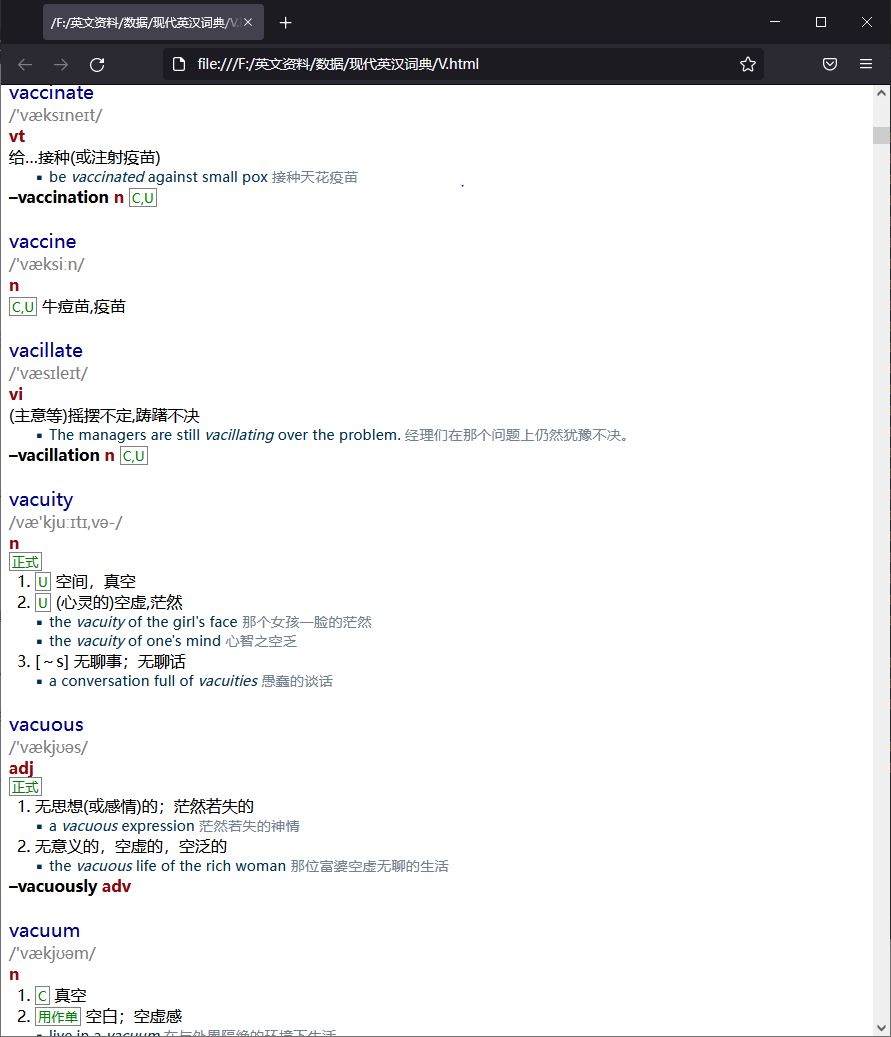
提供另一种或许也可以读的词典,外研社《现代英汉词典》,语法、例句稍多,共有词头38000个,数据质量相对较高。提取自 外研社《现代汉英词典·现代英汉词典》 https://downloads.freemdict.com/尚未整理/共享2020.5.11/content/2_汉英英汉/外研社现代英汉汉英/ ,删除了其汉英部分。共两个文档,一个是词典可用的mdx,一个是分解出来的html,CSS文件略有调整,注意两个文档的css不能互用,其一名称为xdhy,另一个为xdyh。
外研社-现代英汉词典mdx.zip (4.6 MB)
现代英汉词典html.zip (8.4 MB)
3 个赞
把整个词典一个个词条速览了一遍,找出来了300个错误,这些错误主要是“phrase”或“idiom”的排列位置不对,及由此导致的混乱,其他错误也有,相对比较低频。把这些需要修正的词条列一下。
《21世纪英汉词典》mdx需修订单词记录.txt (2.0 KB)
6 个赞
原始html数据上挂的一些标签比较怪异,像基本定义,词性变体,它们应该算一个class,还有区分了idiom和phrase,说实话,这两个类别有时难以区分,所以在纸版书上不加分辨。我不想大修这个词典,overhaul,只要数据对了,不是很在乎html文件本身干净整饬,因此一切照旧。原来没细看用的“usage” class不合理,计划改成idiom,把这个名称派给被遗漏了的“用法”标签(数量很少,或者用guide)。
1 个赞
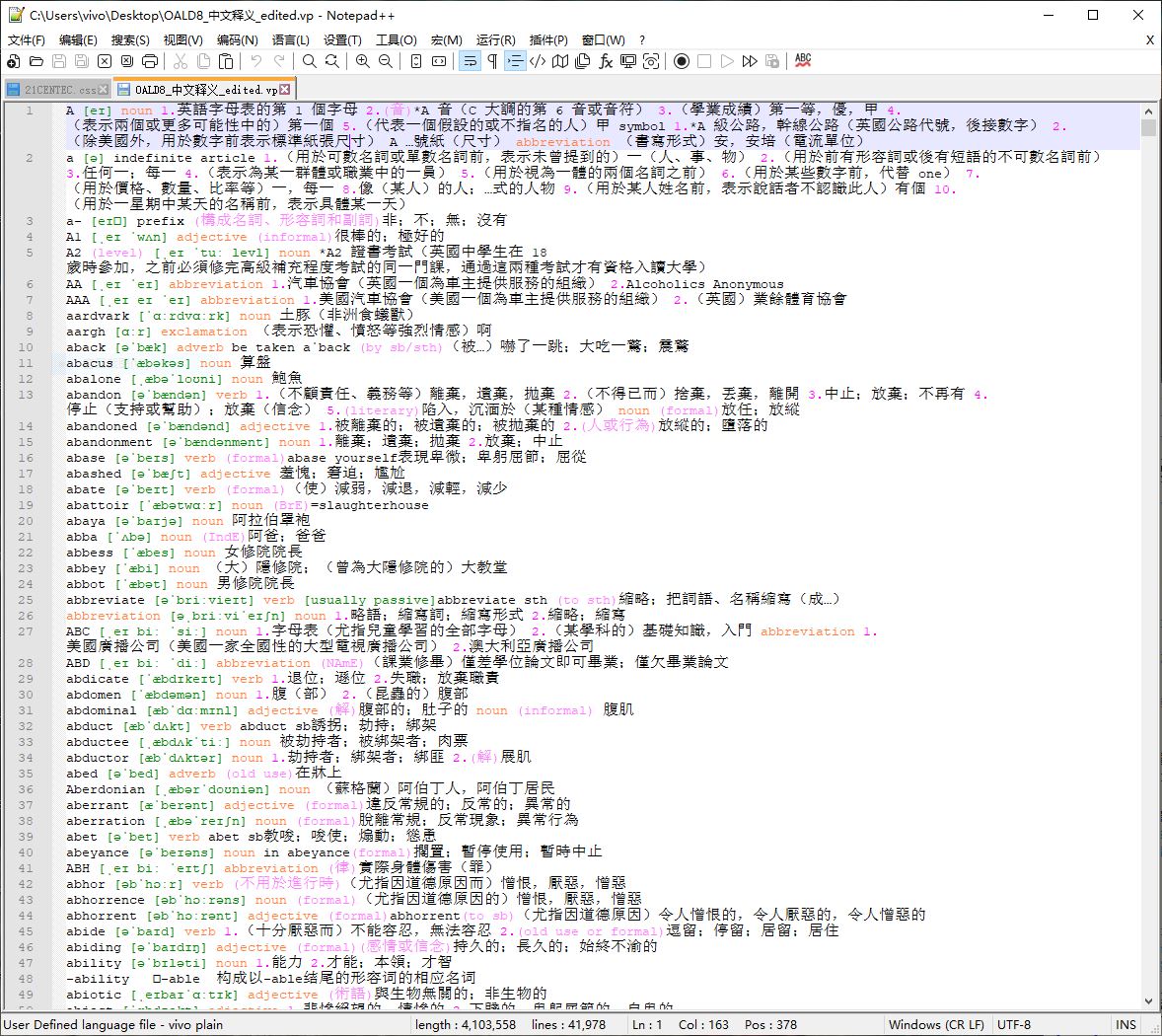
完整的《牛津高阶英汉双解词典》通常情况下没法通读,然而也不是没有办法,我曾想到的一个方案是从牛津高阶8 (底本 Index of /100G_Super_Big_Collection/英语/系列词典/牛津/[英-汉] 【2016.2.13】牛津高阶双解8 -- 繁简切换优化版/Oxford Advanced Learner's En-Ch Dictionary/ )中提取中文释义,买椟还珠,把那些英文解释、中英文例句、衍生词等统统都删了。不过牛高8用的标签很复杂,或许还包括某些潜在的错误,导致程序提取的结果不是很完善,但马马虎虎应该算能用了,剩下的是人工通读校正,还在进行当中。献丑把代码和提取结果贴在这里,希望能得到编程达人指教,使提取结果更完美一些。程序和词汇表在github上也贴过,见 english-dictionary/OALD8_中文释义 at master · mahavivo/english-dictionary · GitHub
《牛津高阶英汉双解词典》第8版 词汇表(曾人工校改过一部分内容)
OALD8_中文释义_edited.txt (3.9 MB)
提取牛高8词汇表所用python代码:
oald8_extractor.py (6.2 KB)
1 个赞
通读的话,OALD作者霍恩比曾建议学习者使用COD(第9版之前的)。单词释义 brief but comprenhensive in expression。
两点疑问:
- js能实现双解切换不知能否隐藏指定字段,比如隐藏那些英文解释、中英文例句、衍生词(如果有的话)?
- 如果仅保留中文释义,那么以OALD8为底本不如以OALD4为底本?
2 个赞
牛津商务英语词典
牛津学术英语词典
适不适合用来通读?(没那么厚可能读得完)
早期版本的COD(《牛津简明》)确实释义简短精炼,不过其收词量实际上和OALD区别不大。收词量统计这东西水分很多,常有夸大成分,可能只计算顶格加黑的headword比较合适,还有一个简单办法,就是阅读目测各自的XYZ词条。我的感觉是COD和OALD收词量相当(也许COD稍大),而偏重不同,COD是给初、中级母语读者用的,OALD则会收录一些国际化/区域化的词条,比如南非英语、印度英语、澳新英语、穆斯林用语,汉语、日语词汇更不消说,有空写程序比较一下二者的词汇表。
COD既然号称简明,那么无论英文版还是英汉双解版,直接去读好了,没必要做更进一步的提取压缩。可能需要把mdx转成txt或html。
OALD 8跟其他mdx词典一样,可以用css隐藏各种做过标签的正文,但我个人喜欢干净紧凑的纯文本文件,能做成sqlite数据库更好,方便修改,自由运用于其他无数场景,mdx毕竟是平台有限、相对封闭的文件格式。
提取OALD4中文释义曾经考虑过,可惜它的原始数据屡经修改,很多版本,难以判断是否可靠,而且,OALD4的英文解释、例句,中文例句翻译也颇出彩,删了会大大减少其价值,设法直接利用文本全文就行了——比如vs code、chrome打开txt文本搜索。
《牛津商务英语词典》、《牛津学术英语词典》这些是偏门武功了,不是我的趣味,没怎么关注过。
4 个赞
对主楼的词典做了更新,主要变动如下:
1)快速通读整个词典,找到并更改了300处左右的错误;
2)usage标签改为idiom;
3)补充缺失的phrase、idiom标签;
4)添加 guide 标签;
5)删除重复多余的headword标签;
6)借鉴supplement提供的css,版面略作调整
请已下载词典文件的网友重新下载。
另:@supplement 您的css文件也需要更新,变动不大。我保留了原有版式,是因为版面相对紧凑,占用空间小,我个人其实并不主要是在mdx词典里用它的,觉得浏览器里读、查html或txt更方便。
8 个赞
楼主,《21世纪英汉词典》有没有“英文”底本?哪怕是大致的英文底本?
如果有就更好了!可以放在一起对照着看。
例如:李华驹《大英汉词典》和Webster’s New World College Dictionary
感谢 mixivivo 辛苦付出
附上新的css
21CENTEC.css (2.7 KB)
4 个赞
谢谢,在variant里重复出现的“headword”我尽量删除了,先前忘了说明,似乎不再需要div.variant span.headword {display: none; }这一句,当然加上更保险。 
谢谢制作分享~
对文科生来说,掌握 HTML/CSS 和 简单正则 以及基础的一些编码知识,处理文本可以说得心应手了,制作epub电子书更是不在话下。
楼主还掌握python编程,那就更进一步掌握雷电了。不过,很少写代码的我还是觉得用excel 直观不费脑哈
1 个赞
《21世纪英汉词典》编辑使用的参考书,作者在前言里有说明:
当时市面上最火的英汉词典是牛津高阶4,作为收词量相当的词典书,《21世纪英汉词典》似乎不应该不参考,我在翻阅的过程中发现某些奇怪的词牛津高阶收了,21世纪也会收录;真正的词典参考底本,英汉词典编纂者往往讳莫如深,本来这行当,容易遭受抄袭剽窃的嫌疑,“书名恕不一一开列”这句话其实大有学问。
不过,《21世纪英汉词典》属于中小型词典,可参考的词典选择很多,搬运的书多了,深度搅拌一下,就是原创,李华驹们的《大英汉词典》规模稍大,处境就不一样,能“借鉴”的英文词典就那么有限若干种,人人都知道的。
5 个赞