此书1200多页,可谓生物学的小百科全书,内容广泛丰富,且插图精美准确,一册在手,把它研究吃透,基本算是生物学的半个达人了。
很久以来我想把它文本化,文字识别难度不高,但如何保留格式,把图像、图表等准确插入,做出来图文并茂是个难题。
此前我尝试过OCR成word文件,再转为markdown,效果不佳,a)小标题、粗体等格式丢失,显得眉目不清,b)识别软件切出来的图片零碎散乱,且不少是错误的,全书可能有数千图片,把它们后续处理正确,殊非易事,c)文字排版也有讹误,多处需要校正。
这里给出一个样本,第12篇的内容。
12.zip (6.7 MB)
最近我尝试了一种新的方法,成效似乎不错,即用Gemini 3 Pro把图像pdf识别输出为html,图片部分只需占位,不识别,但要给出图像坐标bbox。识别完成后,用程序根据bbox在原始pdf里截图插入html的图像占位处,这样文字和图像部分就组合起来了。
不过上面的办法也存在弊端,一次只能识别一章(全书共60章),多次OCR在格式上很难保持一致,最后把各章整合成完整的一本书时就有问题。有没有更好的策略让模型输出html的 style 前后一致,还在继续测试研究中。
在此也给出一个样本,第60章。
第60章 脊椎动物的发育.zip (14.1 MB)
《生物学 第6版》(Peter H. Raven 著)的图像PDF可以在 生物学 第6版 - Anna’s Archive 下载,近 700m 大小。
我最近在尝试一个新的方法来做图文对照词典,也可以用在这个上面,就是用paddleocr得到文档结构,然后再用gemini得到文字,最后再进行合并。
图文混排的书,数理化这些太复杂难搞了(像James Stewart《微积分》、哈里德《物理学》、布朗《化学:中心科学》等),天文地质版面杂乱插图太多(埃里克·蔡森《今日天文 》、Edward J. Tarbuck《Earth Science》等),生物、计算机(《深入理解计算机系统》,github上有人在做)、美术(比如《詹森艺术史》)倒是适中,努力一下,可以把它们文本化。
生物学入门教材,我推荐 Campbell Biology, 12th edition 2020
大陆于2002,2024 两次翻译出版过节选本 Campbell Essential Biology,至今没有翻译出版过全本。
全本对岸有:生物學上下冊第十版-編譯:鍾楊聰等 出版日期:2019/09- 偉明圖書有限公司,但没看到有电子PDF。
此外,如果聚焦细胞、基因方面,用这本入门更好:
Essential Cell Biology, 6th International Edition_(Bruce Alberts)_2023
Zlib上最近才出现此最新版本的 true PDF,之前都是些排版很差的、源于epub的PDF。推荐。
PDF的编辑插入确实是个难题,尤其是如何让程序自动处理,如果手工一页一页处理一个人干不来。
Campbell Biology我已经借助 ai 翻译了,但没校对,没插图,没法直接读,Peter Raven的书中文版则是现成的,进一步提取pdf文字和图像即可。
美国的这些基础类教科书,价格昂贵,利润丰厚,也能给作者带来名望,通常会有多个团队在制作和竞争,内容其实大同小异,但最终会形成几个流行品牌,屡次再版,寡头垄断。
此类教科书虽有1000多页,实际就生物学作为学科而言只是入门,生物化学、分子生物学、细胞、遗传、发育、进化、微生物、植物、动物、生态、生理学、神经科学等都有专门且权威的教科书,真入行了自己也能辨别优劣。
我把Campbell Biology的中文译本上传于此,目前它仅能作为辅助参考,可与英文版双语对照阅读。
坎贝尔生物学(第12版) - Neil A. Campbell 等著 - v0.1.txt (4.9 MB)
现在人工翻译不是特别好,坎贝尔生物学,还有数学GTM系列书籍之类的经典作品可能最后还是要用AI来解决
haoshu
7
各位,AI现在翻译术语怎么样?我感觉《英汉大词典》不行。如果中国行业内没吸收的概念,更没戏。
对于比较基础性的知识和术语,ai处理通常没啥问题,毕竟谁也没大模型读书多,过于专业和生疏的,能阅读的人自身也是专业人士了,可以直接读外文,翻不翻译区别不大,也可以译文中注解附录原文。
amob
9
翻译术语,有术语在线、知网、乐词网,不会用这些词典吧。
确实如此,专业教授们译笔未必好,不借助AI的话,翻译质量很多时候不一定比得上全AI翻译的。
这也是我建议探讨STEM英文经典专业书的AI翻译相关技术的原因:在校生自己去动手,既学习了本专业知识,又能锻炼python和AI应用的基本能力。
但要注意:不能营利,以科研学习为目的,在网上最好一章一章的搞(片段利用)、不要合并全本。
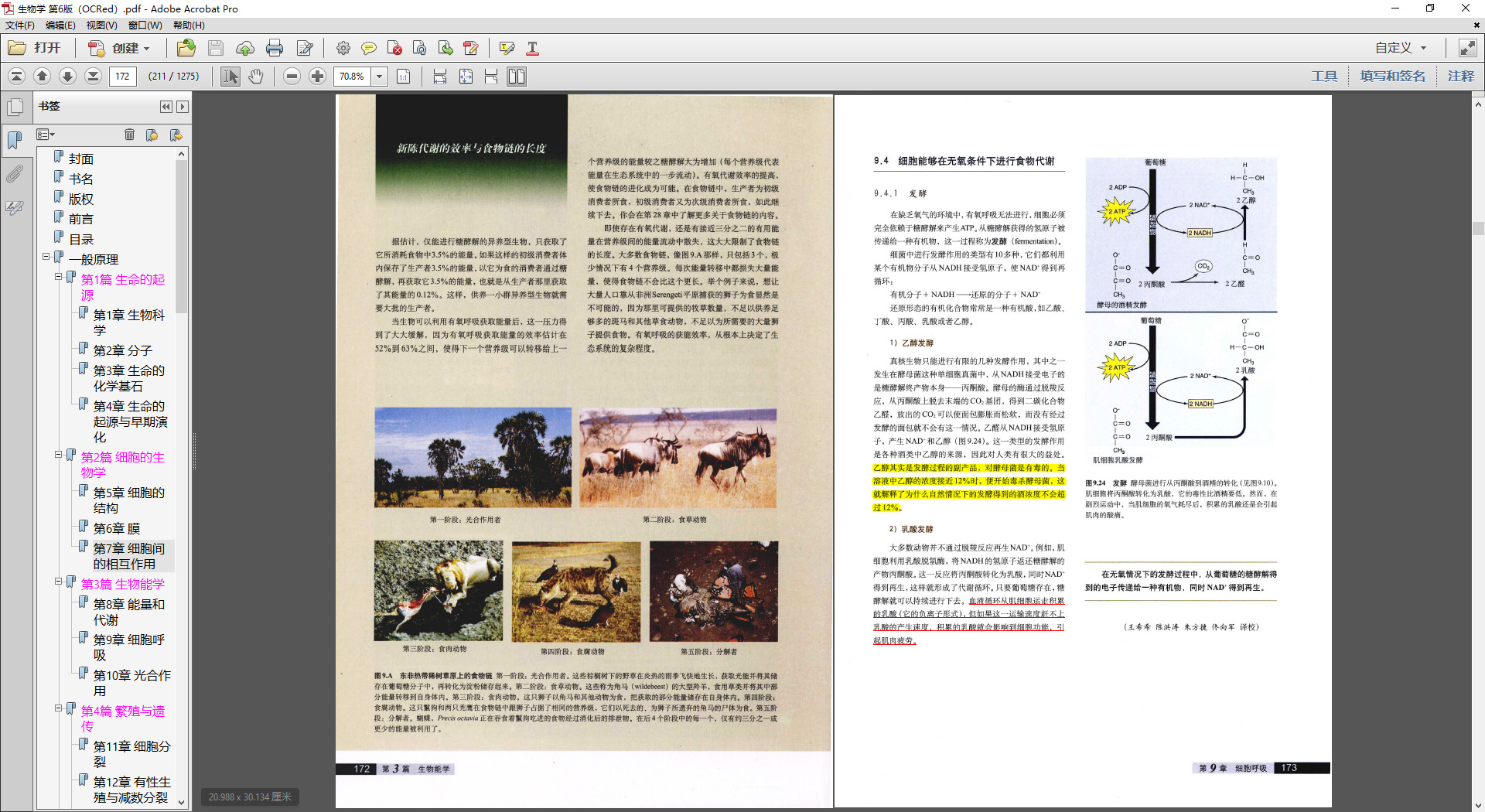
文字用 Gemini 识别完成了,准确率比较高,但发现给出的bbox有时对,有时很多错误,不靠谱。最终可能还是需要手工截图,bbox即使正确了,程序截出的图经常有多余空白,还因为原书版面的关系歪斜,都需要进一步裁剪和修正。
手工截图工作量太大,后面想了想可以重新单独提取插图的bbox,然后批量替换,效果依然不算很理想,但也勉强可用。
《詹森艺术史》我用更清晰的底本又OCR一次,文字、版面还原度还不错,需要进一步清理,这里给出一个样张。
22_第二十二章 洛可可艺术.docx (3.1 MB)
如果只是想粗略了解西方艺术史,贡布里希的《艺术的故事》是很优秀的入门书。这里是一个ePub版,网络下载的,我稍微编辑过,调整了目录,也重新索引编号了图片。
艺术的故事 - 贡布里希 (Sir E.H.Gombrich).part1.rar (20 MB)
艺术的故事 - 贡布里希 (Sir E.H.Gombrich).part2.rar (2.4 MB)
《詹森艺术史》已经识别提取了文本和图像,不过后续还需要很多编辑校正工作。比如ocr引擎切图,并不是很准确,有时截取了部分图片,有时多出不少空白,即使相对准确了,原始图像还存在稍微歪斜的问题,会导致白边,比较难一一调整。
我用 Gemini 3 Pro 又提取了一次bbox,用它来截图,位置比较准确,但也无法根除歪斜导致白边的毛病。用算法纠正,也不是很灵。
又做了两本书,Stanley Brue, R. G. Grant 著《经济思想史》(第8版)和Eric Chaisson, S. McMillan 著 《今日天文》(第8版) 。
《今日天文》的OCR、制作难度比较大,除了图像底本不清晰、版面复杂外,中文版对原作擅自做了很多改动,比如一本书拆成三本,调整了章节编排,有两章文字在诸册中重复等。我计划在文本版里恢复原作原貌。
原始文件还是贴在github。
spoony
15
mixivivo大侠,您gh上大量txt格式作品,发现简直是个金矿。请问哪里可以找到英文原版的类似作品,当然如果是markdown格式,保留有图片链接的话,也是很好的。您有这么多作品,能否指点一下哪里可以获取这类基于文本的文件。我目前主要靠project gutenberg获取,除txt文件外,整部作品放入单一html文件也很值得推荐,简单而又完整的保留了所有信息。如果您还有另外的渠道,请一并指点。
这些文件大多是我亲自OCR、提取,编辑整理的,没有什么方便的渠道可以获取。网上的信息如今是透明的,搜得到就是有,各种办法找不到就是没有,只能自己从图像pdf里OCR获取文本,然后再整理校核等。
gutenberg上的书,我有时也用,但很多可以说没啥太大价值,陈旧过时了。
spoony
17
gutenberg只是参考经典所用,而且书也不多。