好的,谢谢回复!
ai 加标签的285个未解析词汇。我把加了标签的xml去掉标签,跟原文校对过一遍,并没有幻觉,但存在少量因为格式理解不同而导致的错误,这些错误已经修正了。
285_xml.txt (582.8 KB)
然后根据现有的xml做了一个格式化过的mdx,加了很多色彩,它并不是最终的视觉设计,而是弄得花里胡哨便于查错。
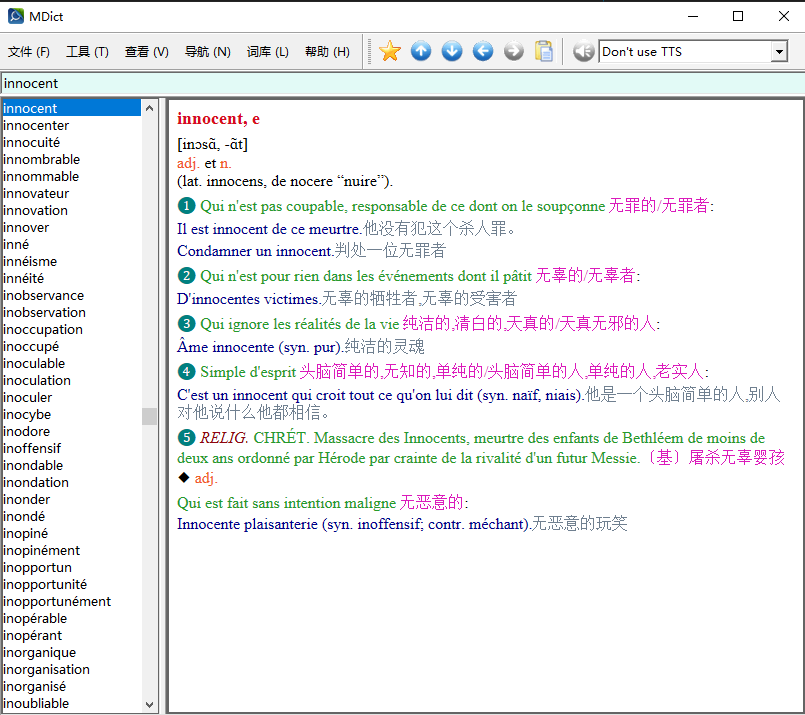
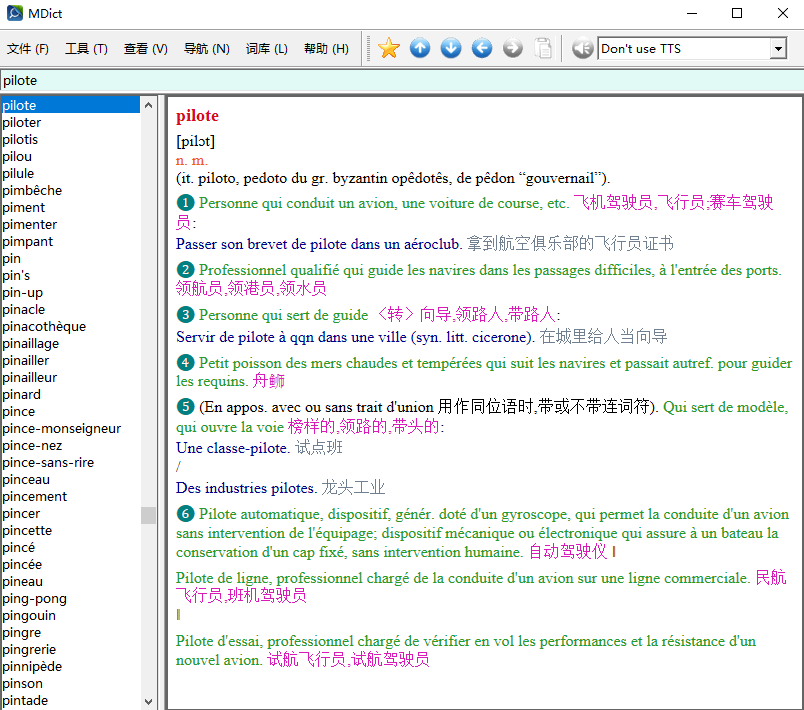
拉鲁斯法汉词典测试.mdx (6.3 MB)(尚有不少格式错误,仅供查错测试之用)
larousse.css (794 字节)
目前发现的主要问题有:
1),/ ◆ ‖这些符号和引领的文字需要加标签围住,便于隐藏或者格式化。
2),pos 需要更上层标签把n. m.圈在一起,以便在一个block里独立设定。
3),cat_fr 标签文字的位置比较随意,难以统一。
拉鲁斯法汉双解词典_xml.zip (8.3 MB)
整合了一下标签,增加了一个tag_stats字段,如果是ai_gen表示是ai生成的,如果状态时error表示这个标签是已知有错的。
从上面的截图来看,好像法文原版的切图也是能够通过程序制作的。因为双解版的切图不便于现在分享,可以请一份法文原版的切图不?
也是一个可以参照对比的印刷版,能够图文对比用起来也能更放心。
这个比较麻烦,因为现在的图片是按双解版的页码来索引的,法文版页码完全不一样要重新建一套,然后切图参数也要重新调。

接近结束,反而没太大动力修改了,搁置了一段时间。
今天修正了一些明显的问题,比如/、‖、◆符号,都加标签隐藏了。给百科部分加了<encyclo>标签,<cat_fr>的位置则做了调整。
XML标签里还存在不少细微的错误,可能需要一个个手工校正。
修改时使用的正则如下,贴出来供检查有没有什么明显失误:
</example>/<example>
</example><slash>/</slash><example>
</example> /<example>
</example><slash> /</slash><example>
‖<phrase>
<double_line>‖</double_line><phrase>
‖ <phrase>
<double_line>‖</double_line> <phrase>
</def>◆(.*?)<pos>
</def><b_diamond>◆</b_diamond><word>\1</word><pos>
</def> ◆(.*?)<pos>
</def><b_diamond> ◆</b_diamond><word>\1</word><pos>
</zh>◇(.*?)</def>
</zh><encyclo>◇\1</encyclo></def>
</zh> ◇(.*?)</def>
</zh><encyclo> ◇\1</encyclo></def>
</head> <cat_fr>(.*?)</cat_fr><def> <fr>
</head> <def><fr><cat_fr>\1 </cat_fr>
</head><cat_fr>(.*?)</cat_fr><def> <fr>
</head> <def><fr><cat_fr>\1 </cat_fr>
在如上修正的基础上再做了一个供查错的mdx版本。
拉鲁斯法汉双解词典(彩色查错版).mdx (6.5 MB)
larousse.css (992 字节)
有些地方中文中有法语的可能断开位置不正确,然后还有之前说的多个词头怎么显示的问题。然后可以用beautifulsoup解析,把中文标签里面的标点符号都替换成中文的。另外也可以正则替换黑色圆圈符号为普通数字编号。“tag_stats”: "has_error"是解析有问题的,也有几十处。
搜<def> <fr>n. m.至少能找到800个标签错误,示例如下,不过这种有规律性,可以写一个正则批量修改。
"xml": "<entry><head><word>sari</word> <pron>[saʀi]</pron></head><def> <fr>n. m. (mot hindi).</fr> <zh>《印地语》</zh></def><def><fr>En Inde, costume féminin composé d'une pièce de coton ou de soie, drapée et ajustée sans coutures ni épingles.</fr><zh>纱丽[印度妇女服装]</zh></def></entry>"
黑色圆圈符号不替换,把颜色改一改其实看上去还可以。
这个应该是我后来解决解析失败问题的时候改语法改错了,现在重新改了一遍,然后发现有3000多处问题,不过上面正则可能要重新运行下,百科部分我处理了。
拉鲁斯法汉双解词典_xml.zip (9.8 MB)

用正则再次修正过的版本,也做了一个相应的mdx,错误明显少了一些。
拉鲁斯法汉双解词典_xml.zip (8.5 MB)
拉鲁斯法汉双解词典(XML).mdx (6.5 MB)
larousse.css (992 字节)
再进一步改大概只有人工了吧?
是的,4万个单词一个个目视检查和修正。
原来xml里面有几十个解析是确定有问题的,都打了标记。
检查了一下前五页的词条,挑出来认为可能有问题的:
à -I. Indique 前未换行,应无-符?
a- 词头后逗号不必占一行
abaissant 音标不同
abattis 原书错误:欧斗当为殴斗
abc 跳转错误 b. a. -ba 是一个词
abdomen 跳转错误 usuel ventre 中当只有 ventre 跳转
aberrance 音标不同
aberrant 音标不同
aberration 音标不同,21e的e应为右上角标
ablette 欧鲌
abondance 1. des 原书作 de
abordable 3. 第二个例句换行错误
原始识别文本的音标错误很多,用多种手段修正过,但如果法文版等也识别有误,是检查不出来的。
这里是双解版错了,按照法文版改的。
我知道,我只是标记。和法文版校对是另外的事。
要更上层楼,可以用高清图像版再OCR一遍,对比校对,不过工作量不小。我个人主要对纯文本版有兴趣,像html格式化,把它做得眉目清楚、美轮美奂,比较麻烦,也没有太大动力投入很多精力去干。
拉鲁斯双解词典有一种义项分类方式是:-I. -II. -III.因此这里是正确的,没有错误。跟双解版有差异又是中文版编辑粗疏马虎的结果。