词典的图像底本不大清晰,不过Gemini 2.5 Pro依然可以达到比较高的识别正确率。我粗略检查过,做成词典的话应该算基本可用。
因为额度限制问题,正在陆续OCR当中,先放出前750页(正文共2057页)的文本数据,供大家批评指正,看下有什么可以改进的余地。
词典已经OCR完毕,大概有400-500万字,尚需要进一步整理校核,比如像前后页接续的地方容易出问题,遗漏少量文本,音标错误,文字讹误等。
为了方便多人协作改进文本质量,在github建了一个repo,它的更新比较及时: GitHub - mahavivo/larousse: 拉鲁斯法汉双解词典
拉鲁斯法汉双解词典 文本.txt (11.6 MB)(2025-10-20版)
这本词典我记得论坛有mdx版啊,然后也有外研社和商务印书馆两个版本,外研社是01年的,商务印书馆的是14年,不知道有什么区别。
论坛上已有的是图片版mdx词典。
外研社和商务印书馆的都叫拉鲁斯法汉词典,但依据的原始底本不同:
1)商务印书馆:
本词典是一本深入学习法语语言的工具书,收录了35000个单词及词汇,按照字母表顺序
排列,每个词条里注有丰富的词义、短语及表达法,为语言的正确使用提供了完整丰富的信息。
体例说明
《拉鲁斯法汉词典》(法法·法汉双解)的法文蓝本是拉鲁斯出版社1994年出版的《法语词典》
( Dictionnaire de français)。
2)外研社:
前言
经过四年多的努力,《拉鲁斯法汉双解词典》终于与读者见面了。该词典的法文原版是拉鲁斯出版社于1995年出版的《法语词典》(DICTIONNAIRE DE LA LANGUE FRANÇAISE)。这是一部中型词典,共38000 词条,含50000个同义词及20000条短语。
哦我找了下论坛那个好像是基于在线版的:
这个版本缺很多词条。
然后商务印书馆版本和外研社版本我下载了比较发现解释和例句都不一致,外研社版的词条更多那看来还是有做的价值的。
我正好写了个多个来源的文本校对工具,可以拿这个试试。
词典已经OCR完了,大概有400-500万字,不过我尚需要对它进一步整理粗校,像页码衔接的地方特别容易出问题,遗漏少量文本等。
先把未整理的原始OCR文本稿全部传上来,慎用,主要供批判。
更新见主帖。
音标里的“-”没有错,是承前省略重复音标内容的意思。
400-500万字的文本,我个人一一校对是不可能的了,只要大致可用,没有太明显的错误即可。
偶尔这种错误没什么,主要是图像里的污点干扰导致的,不是很常见。大模型比较智能,一般来说有很强的黑边、污损等抗干扰能力。
都是很minor的问题了,主要是因为图像底本的清晰度不佳。所以识别的技术条件去年就差不多了,但我一直搁置没干。
但不勉强干也不行,没人从天上给掉馅饼,重新扫描一个清晰图像版,或者出版社干脆把印前文本给放出来。
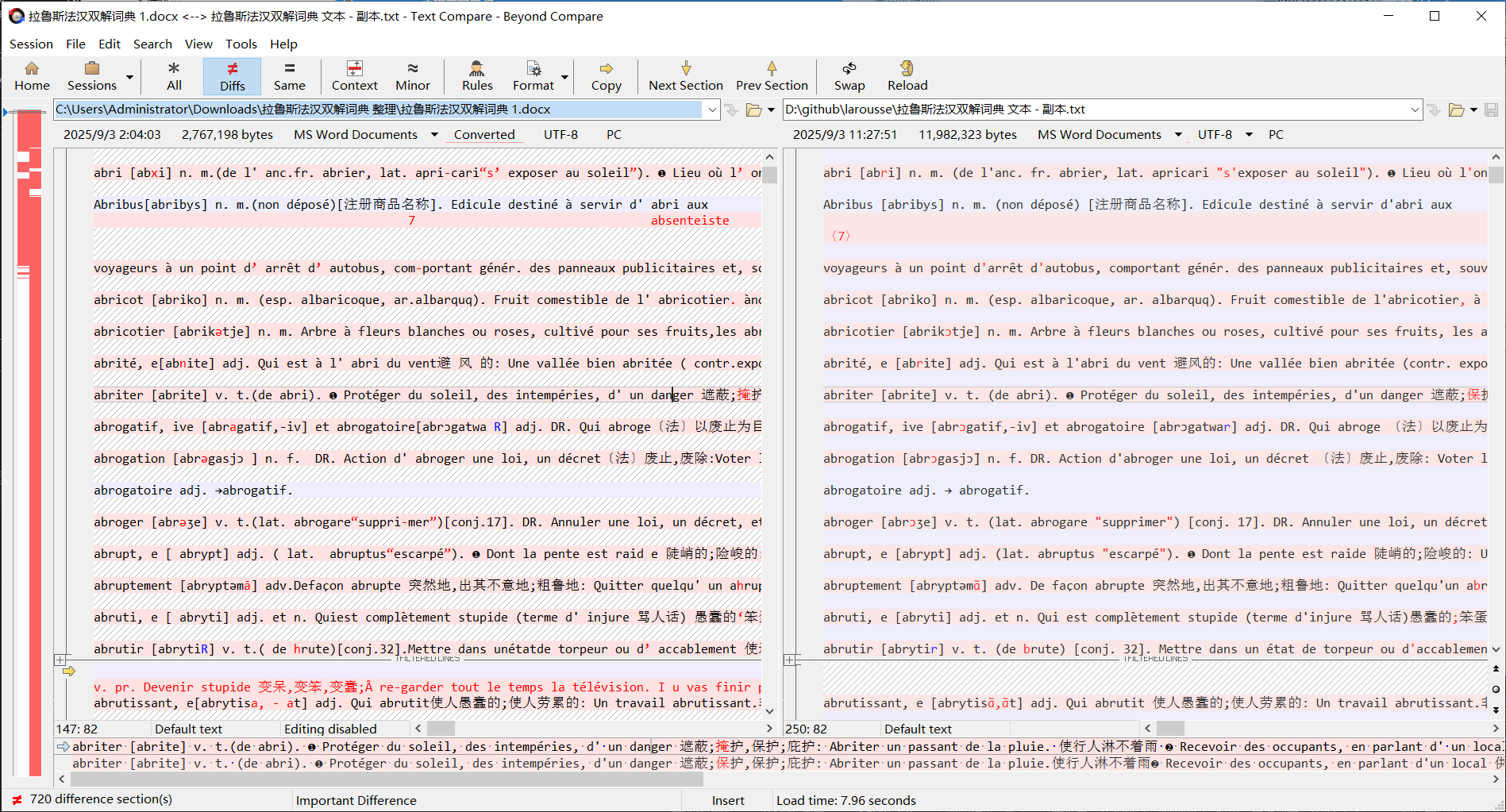
我看了下注音错误很多,而且也有大模型幻觉自己编的情况。 整理了一下格式,主要修复了注音方括号的问题,还有转义缺少箭头的问题。然后写了个python脚本解决跨页问题,把这个切分成了json文件,实际条目不够38000条。另外再提供一个夸克识别的版本,质量也还行,是docx,分割500页处理的,docx是带格式的,也需要写程序处理。
我感觉弄2-3个版本的文本然后分块对比校对比较好。
拉鲁斯法汉双解词典 整理.zip (19.3 MB)
谢谢,辛苦了。不过在把文本捋顺之前,其他操作不着急。初始OCR稿的毛病不少,我在简单核对起始页遗漏文字问题时,发现有两批文本(P1051、P1326起各25页)存在重大缺陷,把黑点序号遗失了,或者统一识别为●,于是重新OCR更换了文本。因为在主帖内尚未更新,您修复注音方括号、箭头等劳作等于用到了空处。
在论坛上更新文本不方便,我考虑把它放在github开一个专门的repo,这样可以多人协作异步操作。
我先把主帖的文本更新一下,主要的差异是替换了重新OCR的50页文本,初步检查了每一批pdf(25P)起始页有没有文本遗漏。
用其他OCR引擎的识别结果文本对校很有效,我经常干,但恐怕不太适用《拉鲁斯法汉双解词典》这类多语种复杂文本,输出格式的差异很多,把人眼睛都看花了,且文字量很大。
主帖暂时不让编辑了,把更新过的文本放在这里。
[拉鲁斯法汉双解词典 文本(初步整理原始OCR稿,慎用)](废稿已删)
其实完全可以对比校对的,目前感觉整体gemini更准,但也有不少两个版本都错误的情况。
音标问题我感觉因为法语发音比较有规律,可以直接根据拼写或者tts之类生成一个再比较
放一个我自己ocr的词典文件,随便看看,错误很多,估计漏词也很多。不忍看,所以一直也没放出来。
拉鲁斯法汉双解词典ocr.rar (5.6 MB)
音标部分错误不是什么难题,可以批量技术性处理,比如把“单词 [音标]”这部分内容用正则全部提取出来,让ai处理,校对,或者再找一个完善的法文单词音标库(最好同属拉鲁斯系列词典),抽取相关内容互校。
我当下比较关心的问题是前后页面接续部分、同一页面两栏衔接部分可能存在文字遗漏、错位,目前还未全部检查处理。
我一般用vs code、winmerge比较文件,都看上去很花,还没用过beyond compare,你的对比效果不错,我也找来试试这个软件。