谢谢。你有没有mdx生成前的txt文件,它的词头排序和原文通常是对应的,至于mdx词典解包后得到的txt,怎么排序就很难说了。
拉鲁斯法汉双解的底本有电子版吗?如果有的话可以拿文本数据来校对,朗氏德汉双解是有的,不需要校对,直接 OCR 中文插入到原文里就可以了。
这些错误,在大模型中实际可以通过事先测试、完善prompt而改进,让它注意音标的加注方式,声明用了[ɛ̃][œ̃][ɑ̃][ɔ̃]等这些符号,双重检查页面衔接处的文字遗漏状况等,我在这里偷了一下懒,并没有全面测试系统prompt。
目前只找到图像版的 Dictionnaire de la langue française - LAROUSSE, 樂如思法語辭典 = Dictionnaire De La Langue Franaise. Le ru si fa yu ci dian = Dictionnaire De La Langue Franaise - Anna’s Archive
最新版好像是24年的,我看网上都没有。校对的话我之前写过一个工具可以对照显示不同文本和图片,但需要导出pdf中每个词的坐标。
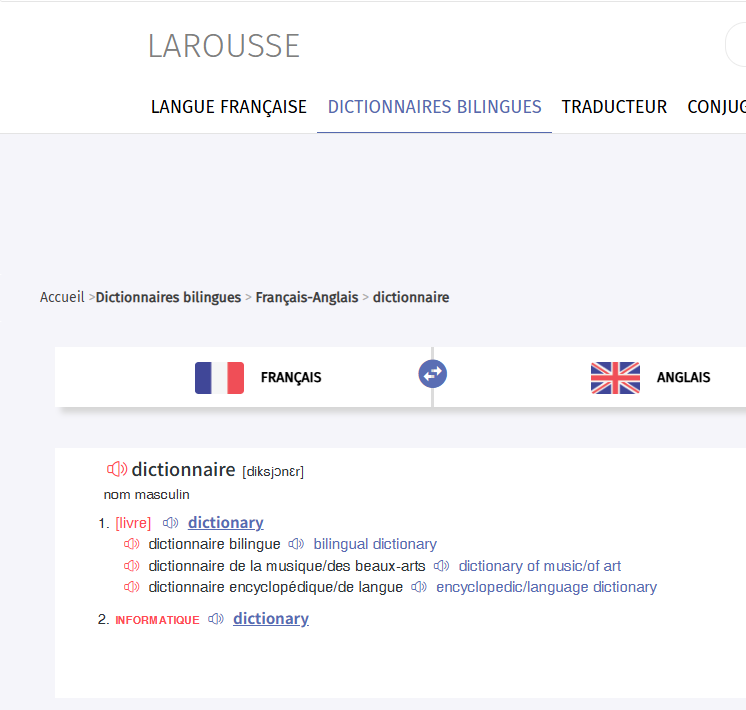
用^.{1,20} \[提取,做了一个简单粗暴版的拉鲁斯词头索引,可以用它去 Dictionnaire Français-Anglais en ligne - Larousse 撞库取音标。
拉鲁斯 词头索引.txt (358.2 KB)
爬虫也让ai协助写好了,测试运行没有问题,不过速度比较慢,我暂时没让它继续跑。
import requests
from bs4 import BeautifulSoup
import time
import os
# --- 配置 ---
# 包含单词列表的输入文件名
INPUT_FILENAME = r'C:\Users\xxx\Desktop\拉鲁斯 词头索引.txt'
# 保存结果的输出文件名
OUTPUT_FILENAME = r'C:\Users\xxx\Desktop\resultats.txt'
# 基础URL,单词将附加到末尾
BASE_URL = 'https://www.larousse.fr/dictionnaires/francais-anglais/'
# 设置请求头,模拟浏览器访问
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def get_phonetic(word):
"""
为单个单词获取其所有音标,并正确拼接。
"""
word = word.strip()
if not word:
return "单词为空"
url = BASE_URL + word
try:
response = requests.get(url, headers=HEADERS, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
phonetique_spans = soup.find_all('span', class_='Phonetique')
if phonetique_spans:
# 提取所有文本片段
all_phonetics_text = [span.get_text(strip=True) for span in phonetique_spans]
return ''.join(all_phonetics_text)
else:
return "音标未找到"
else:
return f"页面加载失败 (状态码: {response.status_code})"
except requests.exceptions.RequestException as e:
return f"请求错误: {e}"
def load_processed_words():
"""
读取输出文件,返回一个包含所有已处理单词的集合(set)。
"""
processed = set()
if not os.path.exists(OUTPUT_FILENAME):
return processed
with open(OUTPUT_FILENAME, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split(': ', 1)
if len(parts) > 0 and parts[0]:
processed.add(parts[0])
return processed
def main():
"""
主函数,负责读取文件、循环处理和追加保存结果。
"""
if not os.path.exists(INPUT_FILENAME):
print(f"错误:输入文件 '{INPUT_FILENAME}' 未找到。")
return
processed_words = load_processed_words()
if processed_words:
print(f"已在 '{OUTPUT_FILENAME}' 中找到 {len(processed_words)} 个已处理的单词,将跳过它们。")
with open(INPUT_FILENAME, 'r', encoding='utf-8') as f_in:
words_to_process = [line.strip() for line in f_in if line.strip()]
words = [word for word in words_to_process if word not in processed_words]
if not words:
print("所有单词均已处理完毕,无需操作。")
return
print(f"共 {len(words_to_process)} 个单词,还需处理 {len(words)} 个。开始爬取...")
with open(OUTPUT_FILENAME, 'a', encoding='utf-8') as f_out:
for i, word in enumerate(words):
print(f"[{i+1}/{len(words)}] 正在查询: {word} ...")
phonetic_text = get_phonetic(word)
result_line = f"{word}: {phonetic_text}"
print(f" -> 结果: {phonetic_text}")
f_out.write(result_line + '\n')
f_out.flush()
time.sleep(0.5)
print(f"\n本次任务处理完毕!结果已追加到 '{OUTPUT_FILENAME}' 文件中。")
if __name__ == '__main__':
main()
每页的起首文字校对到625页,发现p213、302、537、609都有严重的幻觉错误,已经替换。同时也和夸克OCR得到的文本互校了部分文字,获得了一个可喜的消息——《拉鲁斯法汉双解词典》用Gemini识别出来的文本无论中法文文字本身的错误率很低,或许跟正式的出版物也没什么区别。差错主要集中在音标,❶❷❸❹❺❻❼❽❾、◆◇→‖ 这些符号,以及标点上,也不算特别难修正。
2 个赞
几百万的文本,不是这么校核修正的,有多少人可以把它通读一遍?用一条正则 <. ,可以查出上千条符号错误。书的前言部分有“缩略语表”和“专业学科类目”表,结合它们用通配符搜一遍,大部分类似错误可以消灭,个别字符差错并不重要,关键是找到模式。
批量修改结束后的另一种办法则是跟其他识别引擎得到的文本结果对比差异,又可以发现几千上万条错误。
不过还是谢谢你找到这些文字差谬,到后期我会统一整合改正。
我打算用合合OCR把全文再识别一遍,这样至少有三四种不同来源的文本可以对比。
图像底本的清晰度如果足够高,实际上上述的音标、❶◆◇→‖特殊符号、标点错误都会出现得比较少 ,但目前只能多费时间功夫检查纠正了。
我觉得可以先写程序parse词条结构转json,然后再进行格式检查,括号不匹配,序号问题这些都能查出来,另外弄不同版本的其他文本,都进行格式正规化处理,再用图像处理方法获取pdf中每个词条图像坐标,然后用程序自动比较不一致的地方,把有问题的地方同时显示原图,几个版本的差异来进行比较修改。最后都完成后可以json转html就可以加入样式了。我之前文本化就是这个流程,不过是手动调用deepseek和gemini,自动化没调好。不过后续的程序是有写的,我可以改一下用到这个词典上。
你这个思路不错,但先提条件是要有词条在pdf图像里的坐标位置数据,或者有人做过切词版的图片mdx,或者ocr的文本是通过api调用来的,有json格式的坐标,而这里的各个文本,都没有这方面的数据。
我用Gemini OCR时,特别让它加上放在〈〉符号内的页码,就是为了校核时和原页面图像对照,对照结束后,不需要也方便批量删除。如果不是为了这个目的,可以让它直接把页眉内容都删了,只要正文,错误会更少,文字更连贯,可这样要校对时就麻烦了,文字里发现了错误,无法简单确定图像在哪一页,会更费时间。
如果按照你的处理思路和流程,让大模型直接生成词条列表的json数据都行,parse的过程都免了,不过这些可能一开始就要通盘设计好,中途变更会比较麻烦。
我个人其实对mdx词典没什么好感,编辑更改不便,需要专门软件,chatgpt等也没法阅读等,我一般只做最基础的文本txt,在vs code里搜索用,喂给ai,别人想怎么继续加工,随便好了。
如果最终目的是做mdx词典,中小型的简单词典甚至可以直接从Gemini、chatgpt中生成,阅读pdf文件,生成</>分隔的列表,给词头、音标、释义、例句加上指定的html标签,一步完成,不过我个人对这些没太大兴趣。
文本底本搞定了,做简单的mdx是很容易的事,不以制作mdx为目的,并不是说不能做成mdx。
文字版除非是出版社放出来的文档,通常并不可靠,词条排序等都是为了方便进一步核校原书图像。
是的,可以直接输出json,我就是这么做日语语法书的。

单词坐标的话可以直接写个python脚本切分。我之前是用的另一个流程,用chrome自带googlelens做ocr,然后得到位置和其中一个ocr版本,然后用pymupdf解析得到文本和坐标输出csv。
加标签是个简单的parsing问题,直接用lark写个规则就能得到结构化语法树,然后想要什么样式就加标签输出html就行。
我搞了一个用合合ocr出来的文件,它不能正确识别❶❷❸❹❺,统统给改成①②③④⑤。
拉鲁斯法汉双解词典 Textin版.txt (11.9 MB)
我最讨厌扩充词头了,它是词典软件层面解决的问题,goldendict就干得不错。在原始数据文件里扩充词头,造成大量数据重复和污染。
词典软件层面感觉很难解决这个问题,因为这相当于形态学分析,每个语言规则是是不一样的。
这些想扩的人自己动手,我主要关注的是纯净的文本数据本身。跟原书一致,也方便疑时复核。