八字还能没一撇呢,文本上的讹误还很多,想用mdx词典,#35 楼就有现成的。
你是想所有时态的变位都做吗,那可不容易,名词加个复数阴性什么的还可以。
enchaîner [ɑ̃ʃene] v. t. ❶ Attacher avec une chaîne, une corde ou un lien 拴,缚,锁住: Enchaîner un prisonnier (syn. lier). 拴住一个囚犯 / Enchaîner un chien (syn. attacher). 拴住一条狗 ❷ Immobiliser, priver de sa liberté de mouvement 〈转〉使不能动,束缚: La maladie l’enchaîne à son lit. 疾病把他缠在床上。❸ Lier par un rapport de cause à effet, de succession 使连接,使连贯,使联系: Enchaîner des idées (syn. relier). 使思想连贯 / Enchaîner les phrases l’une à l’autre (syn. articuler). 使句子衔接起来 ❹ Enchaîner sur, continuer sans interruption, après avoir fait qqch (后跟介词sur)紧接着,接下去: Après le journal télévisé, on enchaîne sur le film. 电视新闻之后,紧接着放电影。◆ s’enchaîner v. pr. Se suivre logiquement, être lié 连接,连贯: Les faits s’enchaînent. 事件是相互关联的。
上面就是一条gemini模型幻觉出来的数据,在P675和P676接界处,挺有趣。如果不是因为这本书多语种、格式复杂,用纯粹的OCR工具比如合合、夸克等会更可靠一些,起码不会一大片幻觉输出。
你的这些说法怎么讲呢,不谦虚地说,叫代大匠斫。我OCR过几千万字了,很多都放在网上,比如本站和github,什么叫错误率高,什么可接受,外文的连字符等问题,不知道想过遇到过多少次了,真轮不到你来指手画脚。
你看来连基本的ai常识都不大懂,大模型的输出全部有一定的随机性,它是概率确定下一个token的,平白无故跳出来的错误,如果用得多,总会遇见的,用它ocr也不例外。
1 个赞
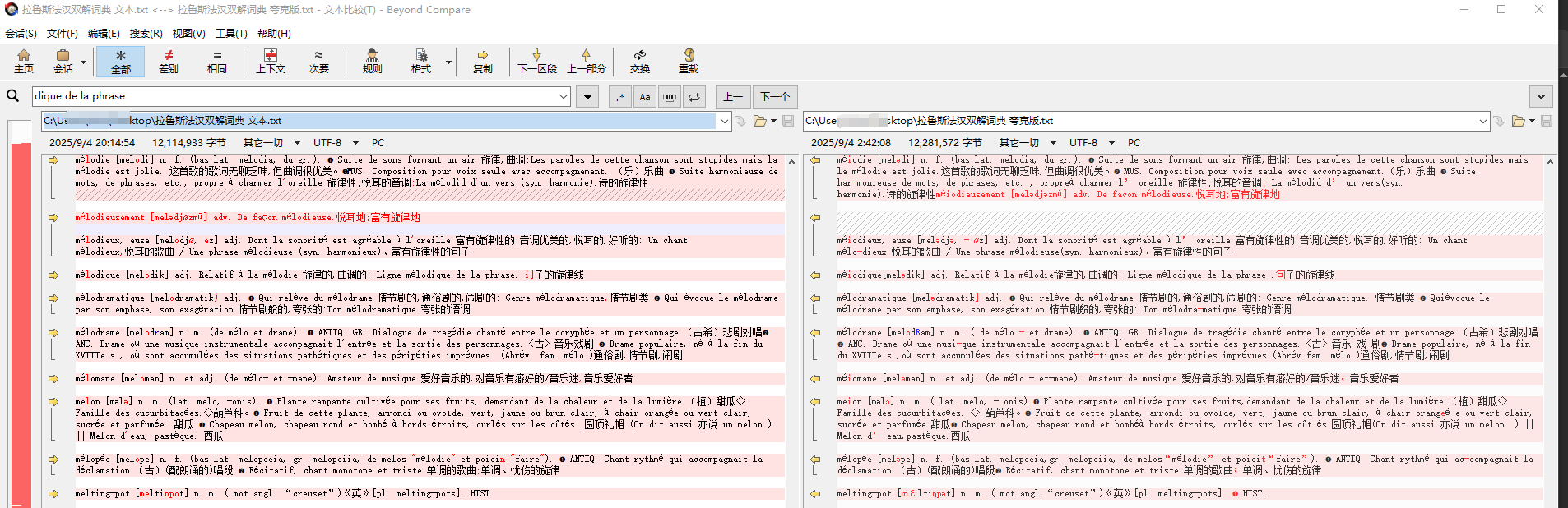
没有一个工具是100%正确的,这就是需要多份文本对比和人工校对的原因。
至于可靠到什么程度,那是随心所欲了,我有自己心目中的核心文本,以及不大重要的的外围文本,看重的,就多花功夫,多用工具核对,不在意的,看得过眼随便搞搞就行了。这些主要都是自用的,顺便网上共享,爱心发电,别人又没给我付钱,爱用不用,吃免费餐的通常还没有资格来点菜,不满意的话自己动手,丰衣足食。
2 个赞
不客气地说,你已干的这些都是无用功,因为软件/机器干得更好、更快、更全,批量是几十几百几千几万,效率更高。我有一个倒是真需要人肉挑错的文本, 《中国古代史教程》 朱绍侯、龚留柱 主编 (TXT、双层PDF版) ,机器干的部分结束了,需要读通,可惜没人愿意做这个工作。
有三份不同来源的文本行做对比就可以了,来源越多越准确,都不一致的情况下再人工校对。
我觉得 mixivivo说的没错,括号不匹配问题我随便写了个程序就查出来1594处,然后再根据特点批量替换就行,人工校对应该是这些都处理完最后再来做。
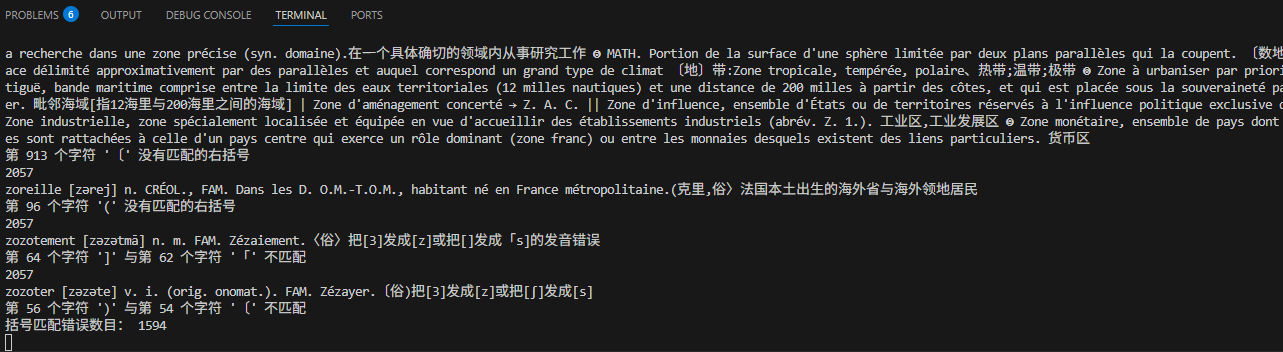
我初步拟定一个设想的校订规划吧,这里面需要先后步骤,次序错了有的工作也许就等于白做。
1)对比图像(也可以双文本对校)核定每页起始文字是否正确,是否有文本丢失问题,大致确定是否页面出现了模型幻觉。这一条保证词头、释义文本的完整性,无遗漏,无错位。目前我检查了800多页。
2)批量修改括号错误、不匹配等问题。
3)校订❶❷❸❹❺◆◇→这些特殊符号。
4)通过对比网上扒来的拉鲁斯数据校正音标。
5)全面双文本、三文本互校。
6)人工检查扫尾。
7)格式化数据,加html标签,为制作mdx词典做准备。
8)其他未尽事宜。
你看看有没有什么需要改进或者补充的地方?
这个流程和我想的差不多,我已经改了一部分括号匹配问题,下面主要工作是找图片坐标,但我感觉最好统一一下pdf版本,我这里下的版本是没有前面的说明的,第三页就是正文。
这是个不错的思路:
用另外一个有OCR功能的大模型再从头到尾OCR一遍,然后用程序逐字节比较两个OCR结果,高亮出不同部分、以便校对。
不同LLM针对不同语种的OCR能力有差别。OCR中文古籍这一块,我觉得豆包不错。
一个比较大的更新,把下面页面都替换成了重新识别的文本:P 1029,1100,1111,1117,1148,1155,1168,1175,1207,1217,1231,1251,1355,1364; P 1551-1575(1552,1562,1567,1568,1570,1574); P 1621,1647,1677,1873,1907,1958 。
不知道具体原因为何,发现1000页以后模型的幻觉更多,由于是不同批次、时间识别的,可能是因为换了api key,也可能是因为拥堵、模型超载,结果调用到了劣质的模型。总之感到在图像底本不佳的情况下OCR数百万字的复杂文本问题比较多,不是想象的那么顺畅,我以前用Gemini 2.5 Pro从没碰到过比例这么高的幻觉错误。
但是OCR这本拉鲁斯法汉双解词典,还是得依赖Gemini模型为主力,它识别外文更准确,中文也不错,图像看不清,以其“智力”也能猜对;如果法文部分错误也很多(比如夸克ocr的结果),后续会更难处理。
有人有自行高清扫描版本的,3个G的版本,我不慎找不到了。用那个版本ocr是不是会好些
1 个赞
楼主用的哪个底本?我有 1.3G 的单栏版。不知道是不是同一来源,你看看行不行,要行我就发上来。
m-larousse-0049.png.zip (1.0 MB)
什么年代的版本,我看了网上基本都是初版,后来12年和24年都出了新版,不知道改了什么。
谢谢了,这个清晰度也不行,而且实际上是商务印书馆出的另一个版本,法文底本不同。
有高清图像自然是最佳之选,我在ocr前到处搜索过,没找到比我手头上更清晰的版本。我用的pdf是从早年下载的300 dpi PDG转化来的,不是自anna’s这些网站下载,所以跟 @wynick27 找到的底本不同,有完整的前言凡例等内容。