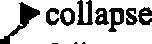adwong
2021 年11 月 25 日 13:50
1
笔者按:因本帖与一项初次发布本帖时仍在进行中的活动 相关,但因时间限制,详细内容恐无法立时写完,故为保证时效性,本帖一楼先简要说明发帖用意及中心思想,之后会以回帖形式把处理详细过程补充完善。读者诸君若想继续看下去,可以暂时不回复(也可以考虑先点个爱心;P);不过若看完本帖一楼后对本帖内容有意见建议或批评,还请不吝赐教。
先说结论
利用PDF分割工具可避免OCR结果跨列串行;
利用ABBYY以HTML格式输出OCR结果,并利用文本编辑器的正则表达式批量搜索并替换,即可利用HTML标签及样式属性初步快速筛选出需要人工校对的部分,从而大大减少人工校对的工作量;
OCR之前可以先寻找更好的图源;
众包人工校对的方式可能并不总是适用;
本帖使用的工具仅限Windows,但处理思路不局限于操作系统。
笔者背景 aka. 本帖可能的局限性
笔者近年来较少使用MDX,故本帖集中讨论OCR及提高其准确性的技术方法,至于OCR索引之后如何与MDX结合,则不在本帖讨论范围内;
笔者可能忽视了下文列举的已有的校对方式中人工的价值;
笔者对正则表达式的理解基于vscode中手工制作超星图书目录的经历,对正则的理解可能不够深刻;
按照笔者列出的方法输出的最终文件,可能仍需要再行人工校对。
发帖背景
笔者给一本书补了档,源头是超星扫描本图书,SS号为14653339,画质一般:
后有人(下称「召集人」)有意制作MDX,并招募人员校对索引(下称「众包人工校对」),源数据使用的是他人基于上方OCR处理的、召集人认可的OCR后的PDF:
看到此帖后,笔者提出更好的OCR数据源头,但客观条件所限,未作OCR,仅给出了图包:
可能因众包人工校对已经开始,且召集人已给出了其推荐的校对流程,故上方图像文件并未吸引太多眼球。
期间有人提出了利用ABBYY+表格识别的方式:
但笔者根据自己使用ABBYY的经历,对上述做法的效率表示怀疑:
除非是地毯式人工校对,否则不建议、也没必要用表格,理由如下:
无论是ABBYY划分表格,还是像之前召集人推荐的OCR PDF复制校对,都需要全程人工逐条校对。基于笔者之前手工制作超星图书目录的经历,经过笔者初步试验,利用本帖描述的纯文本检索法 可以减少逐条校对工作量,大大提升本次索引OCR工作的效率。
正文开始
OCR数据源 :索引-pdawiki-nov’21-14653339 英语同义词辨析大词典 容新芳 2018.zip (5.3 MB)
使用到的工具
步骤概述
利用老马的 Pdg2Pic/FreePic2Pdf 或其他工具将源图像打包为PDF;
利用Briss将PDF分为4部分,同时能避开「索引」页眉,效果如下:
(详细步骤之后详述)下载Briss,打开 Briss-2.0.bat ,将弹出两个窗口。将生成的PDF拖入图形界面窗口,
点击上图窗口下方 Preview 按钮,将在默认PDF阅读器中打开切割后的PDF。将该PDF下载到本地。
将切割后的PDF导入ABBYY OCR编辑器,在OCR语言设置中,基于英语添加一个自定义字符►,并命名该新OCR语言。
以刚刚新建的语言作为OCR时使用的语言,并作全文OCR;
删除第一页中非必要OCR的区域;
以HTML格式导出OCR结果到文件,发现有两处图片:
用Visual Studio Code (下称vscode)在导出的文件中搜索HTML标签找到这两处图片所在位置,并结合上下文找到原图像所在词条,将图片元素 <img.*?> (正则表达式,制作过文字MDX的读者对此可能并不陌生)替换为正确的字符:
替换后得到的纯文本HTML:容新芳索引-HTML文件.txt (1.2 MB)
细心的读者可能已经发现,HTML标签已经帮我们标注出了各种元素。时间关系,这里先说部分结论,还望各位验证:
class="font4" 为主词条class="font7" 为同义词条(►)正则<h[\d]>.*<\h[\d]>(a a|b b|c c|d d|e e|f f|g g|h h|i i|j j|k k|l l|m m|n n|o o|p p|q q|r r|s s|t t|u u|v v|w w|x x|y y|z z)
据此,可将主词条和同义词条分离,且由于HTML标签及►符号的引入,正则表达式的作用也会比「处理换行错误」大得多。
9 个赞
Vim
2021 年11 月 25 日 14:29
2
很好的教程,学习了。
只是难度也是有的,难以大面积推广:
adwong
2021 年11 月 25 日 14:32
3
Vim:
正则表达式,文本编辑器使用VSCode又增加难度
有空完善下详细步骤,其实没有涉及很高深的正则。至于ABBYY,可以换用其他软件,我也希望有效果可能一般但免费正版的替代品。
Vim
2021 年11 月 25 日 15:26
5
试用了 Briss-2.0
采纳这种技术新思路,这本词典离文本化是不是又近了一步?
Does any one here have an mdx version of
Word Finder by J.I. Rodale
or Phrase finder by J.I. Rodale.
I’d be much grateful and indebted if you could upload it here.
thanks in advance.
两个疑问:
关键的是需要怎么做才能避免反复手工划定区域?特别是每一栏的距离很近的时候,其实是很容易误操作,在划线的时候把前一栏的区域给移动了。
尝试过复制,但居然只能复制一次?尽管paste这个选项不是灰白。
You can copy and paste a rectangle between different page clusters. Therefore you must select some crop rectangles. Afterwards press ctrl+c, then click into the page cluster where you want to paste the selected crop rectangles and paste them by pressing ctrl+v.
2 导入abbyy之后发现识别效果不太理想:
照理说不该如此,如此清晰的图像。
请教如何优化这一步。
adwong
2021 年11 月 26 日 04:53
8
hkreporter:
Briss的操作逻辑
导入PDF之后,Briss会智能判断出一个选区。可以删除这个选区,左键拖拽可以新建选区,所以拖拽四次就有四个栏目了。
hkreporter:
不太理想:
目前手头没电脑。我能想到的是把文字和页码再多分一栏,识别之后再把页码行改以append到文字行后面(比如vscode的多光标编辑)。
如果只有一页,拖拽四次没事,五六页都得这么拖拽怎么办呢?
adwong
2021 年11 月 26 日 07:05
10
Briss是识别单双页的,只要图片尺寸齐整不需要拖那么多遍。你试一下就知道了。
adwong
2021 年11 月 26 日 07:05
11
选框之后导出PDF就好,不需要复制的,选框也不需要那么规矩,前后大小也不需要完全一致。
adwong
2021 年11 月 26 日 07:06
12
最好详细讲下你使用的源文件及操作步骤,可能你的用法不对。
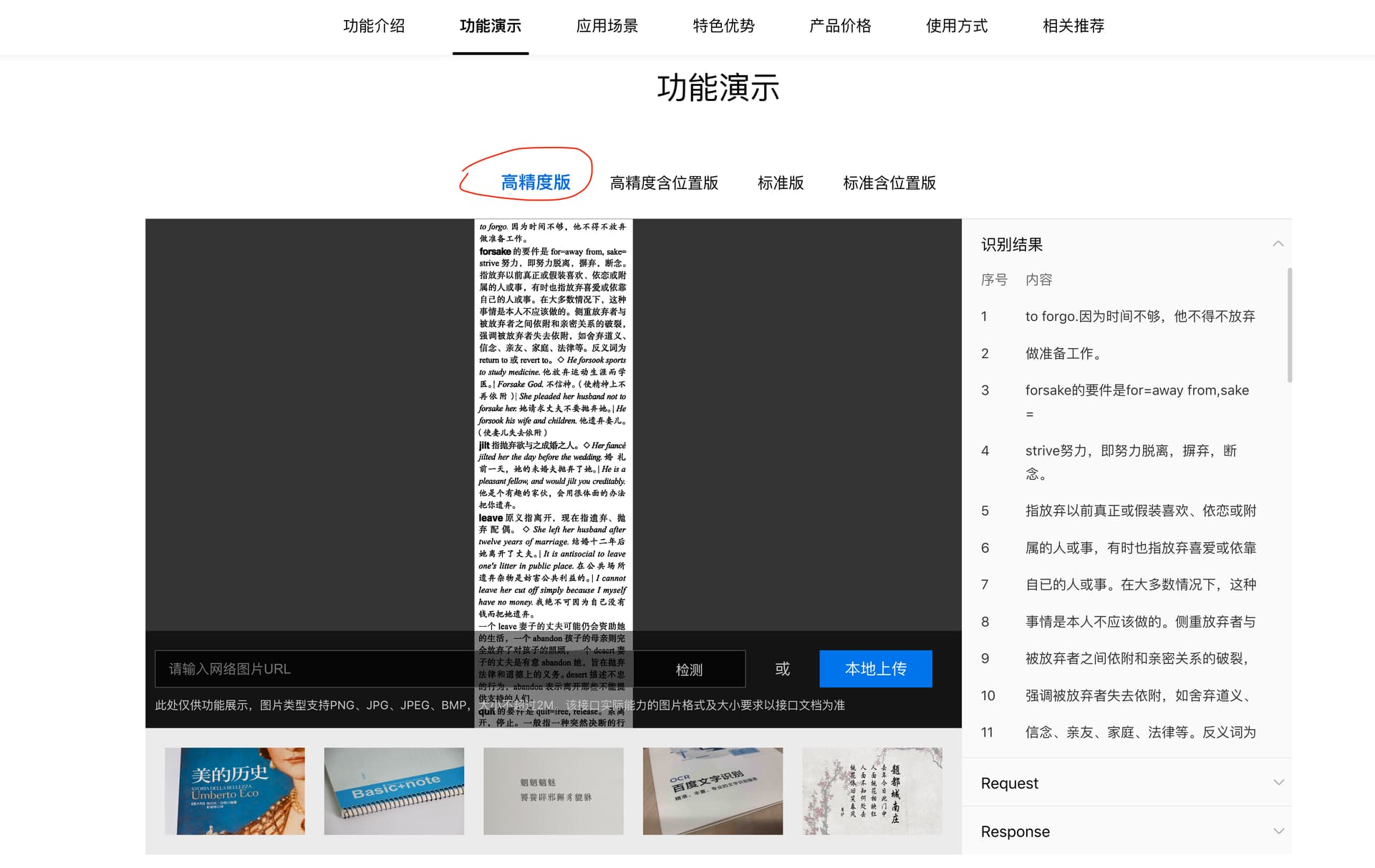
对中文尤其是中英文混合的 OCR 识别, 目前我所用到的最准确的不是 abbyy, 而是百度 AI 开放平台的文字识别
并不是我使用他这个 API 去做了开发才有这样的感受的
如果利用起来的话, 想必能提高不少效率
主要是一直没学会用api做ocr,抱歉请问有没有现成的代码案例?
1 个赞
其实在首页就有功能演示, 可以直观的试一下识别准确度
百度文字识别,基于业界领先的深度学习技术,多项ICDAR指标世界第一,能力全面,准确率高,提供多场景、多语种、高精度的文字识别服务,支持云端调用、私有化部署、离线SDK,注册即可免费试用
random
2021 年11 月 27 日 11:38
18
这个识别结果可以导出为带标签的html代码吗?(保留加粗的信息)
random
2021 年11 月 27 日 13:40
19
刚试了下,结论如下:
结论:最好可以配合abbyy的识别结果,进行智能校对,方能达到最优效果。
多谢评测