我可以考虑空闲时间帮忙校对
1 个赞
多谢,我也建个微信群吧,便于协作。
刚才我试着校对了几个,发现由于ocr的原因导致任务量增加不少,我再考虑看是否可以和我前面的筛选再结合一下,也许会减少不少任务。
1 个赞
我之前OCR扫规范词典的时候,为了方便写声调,在搜狗输入法的“自定义短语”功能上给aeiou绑定了四个声调,打出来直接选 ![]() OCR识别准不准还挺玄学的,同一张图,识别三遍可能有一遍能识别出声调,另外两遍不行
OCR识别准不准还挺玄学的,同一张图,识别三遍可能有一遍能识别出声调,另外两遍不行 ![]()
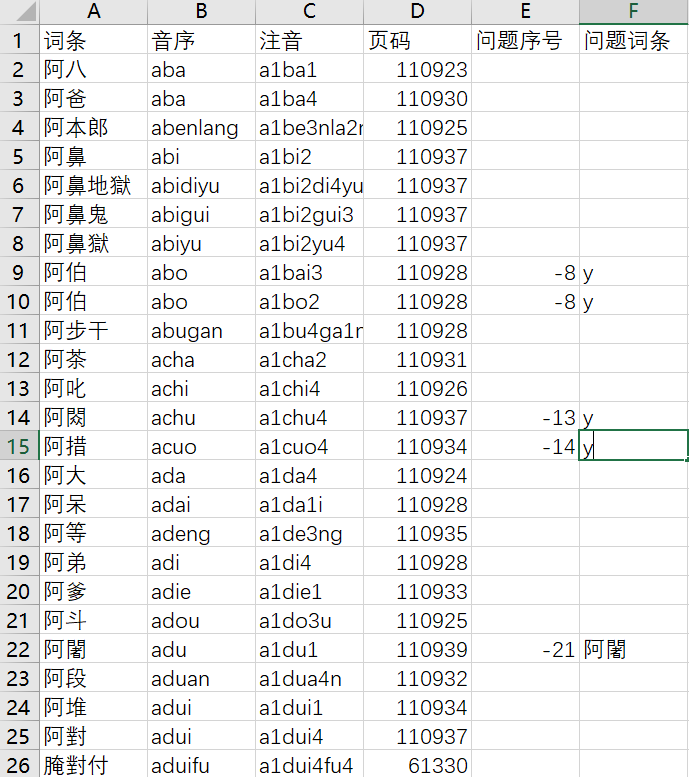
对筛选出的9000词条再筛除首字外不是多音字的,只剩3000多条了(前面功夫没白费)。
但校正读音真不是一件容易事:
就上面那个“阿闍”,先查“闍”,《汉语大词典》有两个读音

再查文字版“阿闍”
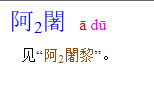
再查文字版“阿闍黎”

再查图像版“阿闍黎”

图像版对“闍”的注音是she1,放在整个词条偏后的位置,不合常规,并且与对单字的注音(du1与she2)不合。
到底如何选择。查《词目意序索引》

依稀可见是she2。再与《汉语大字典》《辞源》等对照,确实读she2。
过程虽艰辛,但也挺有意思的。
以后遇到特殊的情况都在这里备上:
挨挨軋軋
緝 直接注音ji1 qi1 应为(今读qi1)缝衣边
愛手反裘 愛毛反裘
2 个赞
查“畚梮”,解释同“畚挶”。但“挶”注音ju1,“梮”却注为ju2。因为怀疑,所以又查了几部辞书,却反而更糊涂了。梮,《汉语大字典》《辞源》《现代汉语词典》都注为ju1,《辞海》却注为ju2,和《汉语大词典》一致。看《廣韻》两个字都是居玉切,入燭,見。这种分歧可能与入声字有关。本着少数服从的原则,就暂定为ju1吧。
普通話聲調是陽平,聲母是b, d, g, j, zh, z,都原來是入聲。這個原則,我給自己造了個助記句子:“博得格局,輒足”。 ![]()
關於“梮、挶”,若是逼我選ju1或ju2,我會按照聲符“局”,歸陽平。
我的辭源拼音索引把入聲字都標出來(“-k, -p, -t”韻尾):
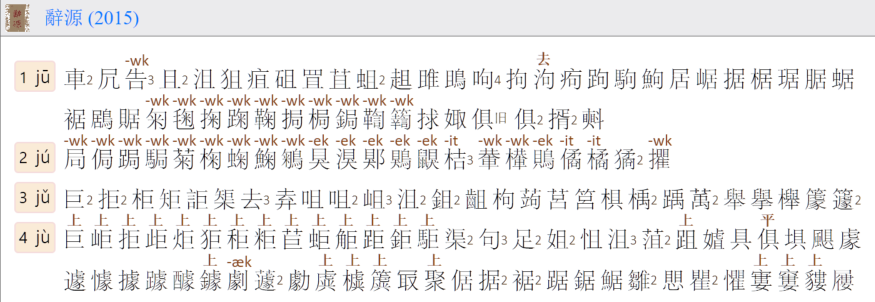
去掉“挶、梮”兩例,有這樣分配:
ju1:鋦
ju2:局侷跼駶
其實“鋦”也是多音字,又j讀ju2。
一般來說,入聲派於陰平是少數,陽平更常見。我曾經做過統計哈哈:辭源收的入聲字,只有13% 現在派於陰平。(相對於32% 陽平;4% 上聲;52% 去聲)
1 个赞
高人,佩服,真渊博呀!不过根据声部类推读音,或根据同声部的字去类推,还不够严谨。一个字读什么音恐怕还是取决它在生活中怎么读,历代辞书怎么注。
嗯,廣泛趨向不能決定某個案子的具體答案。我只提出廣泛的 pattern 來參考。
1 个赞
我现在也在改《汉语大词典》的自动注音。
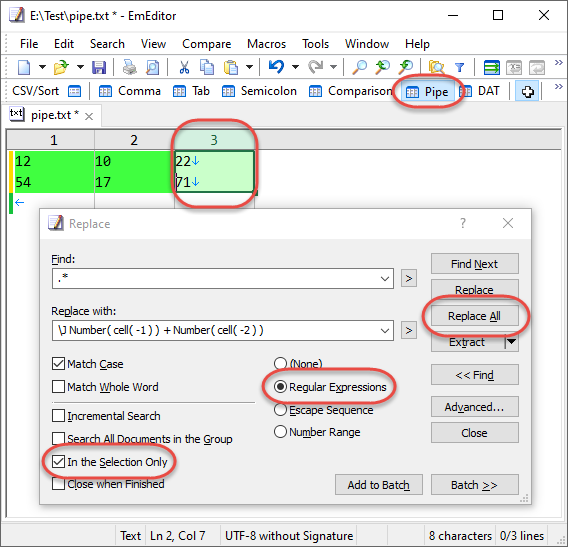
还好用Emeditor上手了,能够批量替换。
1.find extract “chánɡ”, save as data.txt.
2.find extract “場” in data.txt
3.建立一个emeditor.xls
格式:
on dat1 dat2 R
4.复制用 "場"抽出来的资料,贴到dat1栏。
5.更改emeditor中用 "場"抽出来的资料,复制后贴到dat2栏。
6.用on填满第一栏,用R填满第四栏。
7.将Excel文档save as unicode txt,文件名:emeditor.tsv
8.在Emeditor中,Search — Replace in files — 右下角 Import
导入tsv文件。
9.在左边In folder选择文件夹。File types选择*.txt。
(在该文件夹中放进所需处理的文本。注意不会选择“look in subfolder”,以免误伤子文件夹中的文件。最好新开一个temp文件夹处理这种需要批量替换的文件。)
(多文件,选择Save Backup,只有一个文件,选择Keep Modified files open。)
10.点按右上角的Batch Replace All。
The faster method
第6步骤以后,不必转存为text。
接入下面的步骤:
1.选择Excel中所有数据,复制。
2.在Emeditor中,Search — Replace in files,假如替换表中有数据,先选择一切数据,删除。
3.直接把Excel中的数据,通过剪贴板粘贴到Emeditor的复制表中,直接就能用了。
本来以为第一字的自动注音不会错,只有后面的多音字可能错。
刚刚发现:“器”的注音全错了,应该是去声,变成阴平,不知怎么搞的。
再如这个注音:
一十八般兵器yīshíbāpánbīnɡqì
把“般”注成pán,真是离奇、离谱的错误啊!可以用“灾难性”来形容!
你没有用过emeditor的CSV模式?
你要是用了这个,就不用跑去开excel。
没弄懂这个csvmode,Excel我熟练,混合操作对我还是比较方便。
我知道你是Emeditor专家,但是贵人语少,只贴个图,没法领悟啊。
1 个赞
这CSV模式说透了就是一个简单化了的表格,功能也比较简单,但挺好用的。
比如列操作:增加/删除整列、复制/粘贴列
试着用一下,就知道。除了没有函数功能外,可以当成表格用。
这个群还在吗?在的话求个二维码。
不好意思,校对已半途而废
1997年,汉语大词典出版社和香港商务印书馆联合推出了《汉语大词典》光盘版1.0,2003年又升级到2.0。
http://www.guoxue.com/?p=4453
《汉语大词典》(第一版)于1994年出齐,第二版的编纂工作于2012年正式启动。《汉语大词典》(第二版)第一册征求意见本于2018年底面世。预计2023年完成《汉语大词典》(第二版)25册征求意见本,此后由上海辞书出版社正式出齐。