坛友所发之所谓《汉语大词典》光盘2版,来路古怪,让人惊喜不断。虽则问题也有,但除注音外几乎可以忽略,或随见随改即可。而对于注音敝人却认为不可草率视之,知其义而不知音如同断了一肢,知其音而误则如同装了假肢。此版加了注音确实方便太多,但注音错误之处却也太多,断然不可忽也。否则,以假为真,必将贻笑大方。
词目中的首字读音不是问题(当然此版也存在个别问题),因为《汉语大词典》对于首字是多音字的都结合字条给出了序号;首字之后的多音字在纸书中一般都在词目后加方括号说明。因此,我一开始想对纸书全文ocr,然后用正则提取词目加方括号,这样,虽有遗漏,当可快速纠此版注音之误。
但ocr过程太慢,错误也会很多,即使容许遗漏,手工校对量也不小。于是我再辟蹊径:先从此版提出字条加读音,再分为单音和多音。然后提取词目,大概30多万条,然后排除首字,只留下其它字有在前面分出的多音字表中的词条,大概余下了一半,但数目还太庞大。又排除在《现代汉语大词典》中的词条,但《现代汉语大词典》与《汉语大词典》比实在太小,排除掉的条目少得可怜,几乎可以忽略,待人工校对条目还有13万条左右。
一计不成,又生一计。前几天承蒙坛友惠赐《汉语大词典词目音序索引》,但一时不知如何利用。

【此书包括读音、词条、纸书页码及AB面】
此索引虽以读音为序,但和我们习惯的音序不同。习惯的排序是先以字为单位,再按音排序,这个索引是把一个词中所有的拼音字母合在一起排序。如“阿辉”“阿兰”“哀哀”三词,前面就是习惯音序排法,而这个索引则是“阿辉”“哀哀”“阿兰”,因为aiai合起来比alan靠前。我把此版中所有条目(字+词)的读音以及页码都提取出来,然后把声调用1234替换,再按字母排序,就整理出一个与此音序索引顺序一致的待勘误表(包括单字)。
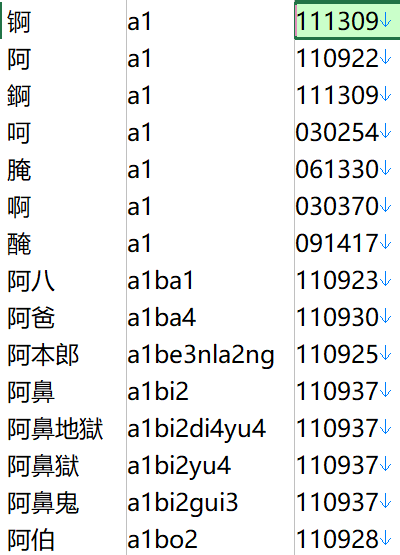
与上表对比,很容易发现“阿伯”“阿傍”“阿旁”的注音都是错的。
目前觉得这个方案还是可行的,虽然条目众多,但:
一、音序索引一书只有1500页左右,一天校对5页,一年可望完工;
二、校对时不少词条一看就知道注音对错,不确定的再和音序索引对照或根据页码查找纸版;
三、如果实在觉得太多,可以拿利用第二个思路排除后的词条进行音序排序后校对,当减少一半工作量。
何况校对读音时也可顺带发现一些其它问题,比如词条有无缺漏,有无错字等。如果能根据音序索引把此版的页码也分出AB面,就能为图像版的进一步切割打下基础。
不知道我的想法可行吗?不知道有同好愿意一起校对吗?不知道大神有更好的办法吗?