这本书是目前唯一一本意汉双解词典,不过原版是双色印刷,黑白扫描的pdf很难区分词条,而且有缺页,缺少792,793页,1414,1415页。1738-1741页。现在用gemini和quark识别了文本版,缺页问题暂时没办法处理,如果有人能提供缺失的页面我会补上这几页。
Dizionario moderno Italiano_quark.docx (11.6 MB)
Gemini识别文本(缺页已补11.26更新):
Dizionario moderno Italiano_gemini.txt (14.0 MB)
这些词典现在识别容易,但后处理麻烦,需要相关专业的若干人员认真对比校核一遍文本,把明显的错误改了。但好像网络总的风气是等喂饭到嘴里的伸手党多,而真正愿动手干活的人寥寥无几。
我现在识别后已经运行了缺页检查,其实可以进一步和夸克文本逐页对比,然后相似度低于某个值报错,这样可以自动化发现大部分幻觉错误。然后还需要一个粗校工具来对比页面和可视化提取词头,可以对pdf运行切图然后和图片直接对比词条数,两边都能调整比较好,我之前让ai实现了一部分功能,但实际要用的话要改不少细节。
如今对比查错不难,很多工具可以用,但错误检出需要人来具体判定和修正,机器还干不了这个活。如果是专业学习意大利语或者在意大利读书的,《现代意大利语词典》这种算是要依赖一辈子的工具,花一两个月时间把它校对一遍其实是很划算的事情。
此类大规模的词典都是不同OCR引擎来源的文本对校。Gemini OCR的质量是相当高的,只有少量错误,对比 quark 识别的结果、参照图像把这些差异处发现的错误改了就行了,并不需要一一对比原始图像校对。根据我校对《拉鲁斯法汉词典》的经验,一两个月时间足够了,拉鲁斯的底本图像质量还更差,讹误更多。
多文本对比校对可以把错误率降到相当低,日常使用足够了。直接对比图像校对的方法不见得更优,人眼检视会疲劳、失误等,但机器对比文本真是字符级的,一个差异不漏。
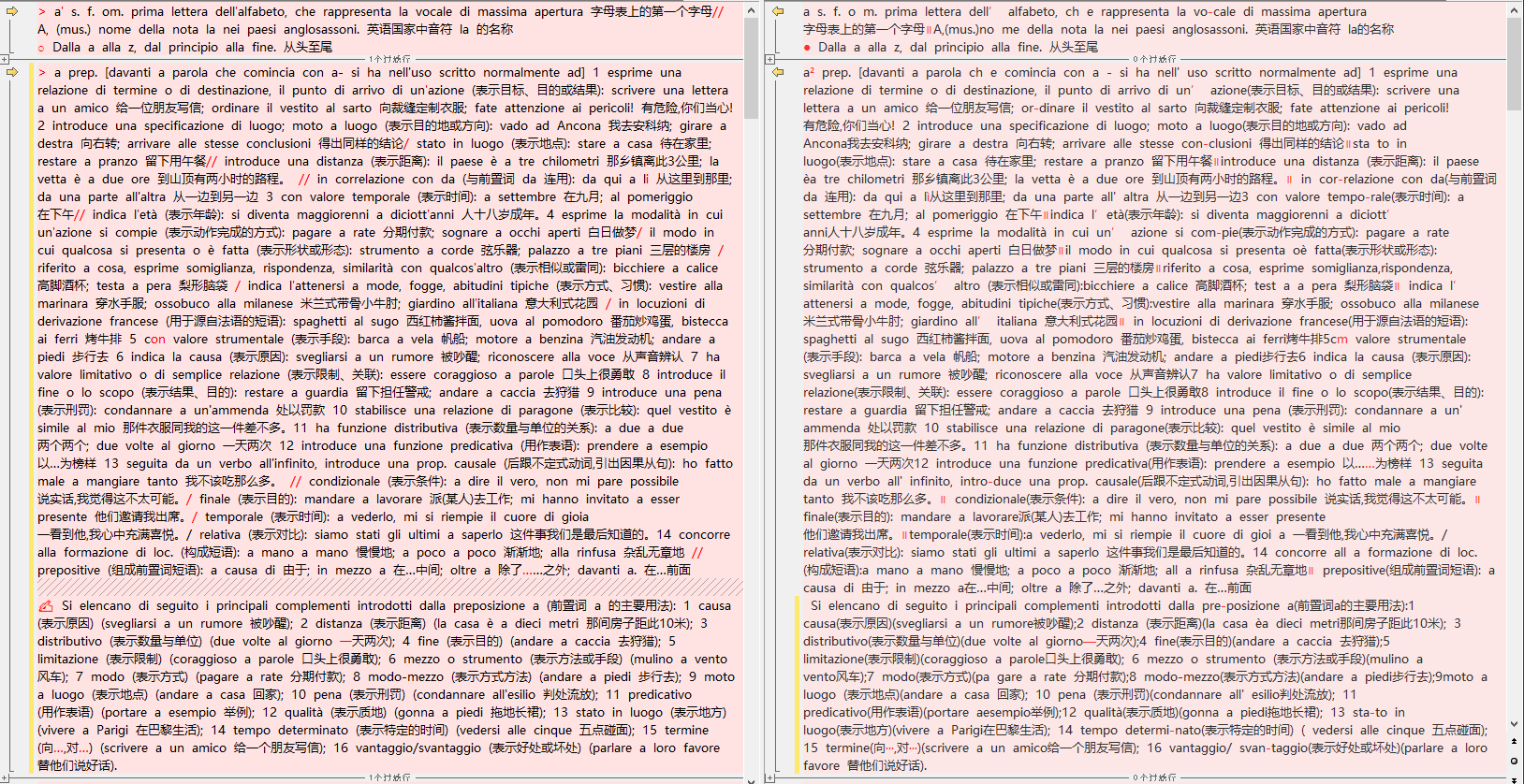
像这里的第一页,我大概对比了Gemini和quark的识别结果,Gemini实际只错了一个地方,abat-jour [/aba’zur/] ↔ [/aba’ʒur/],其他都是格式差异,比如用/还是//,都属于可以批量修正的问题。
感谢坛友 weshor 帮忙拍照。 我用夸克处理了一下,其中有一页左侧变形很严重没想到gemini识别效果居然还不错。
夸克处理结果:
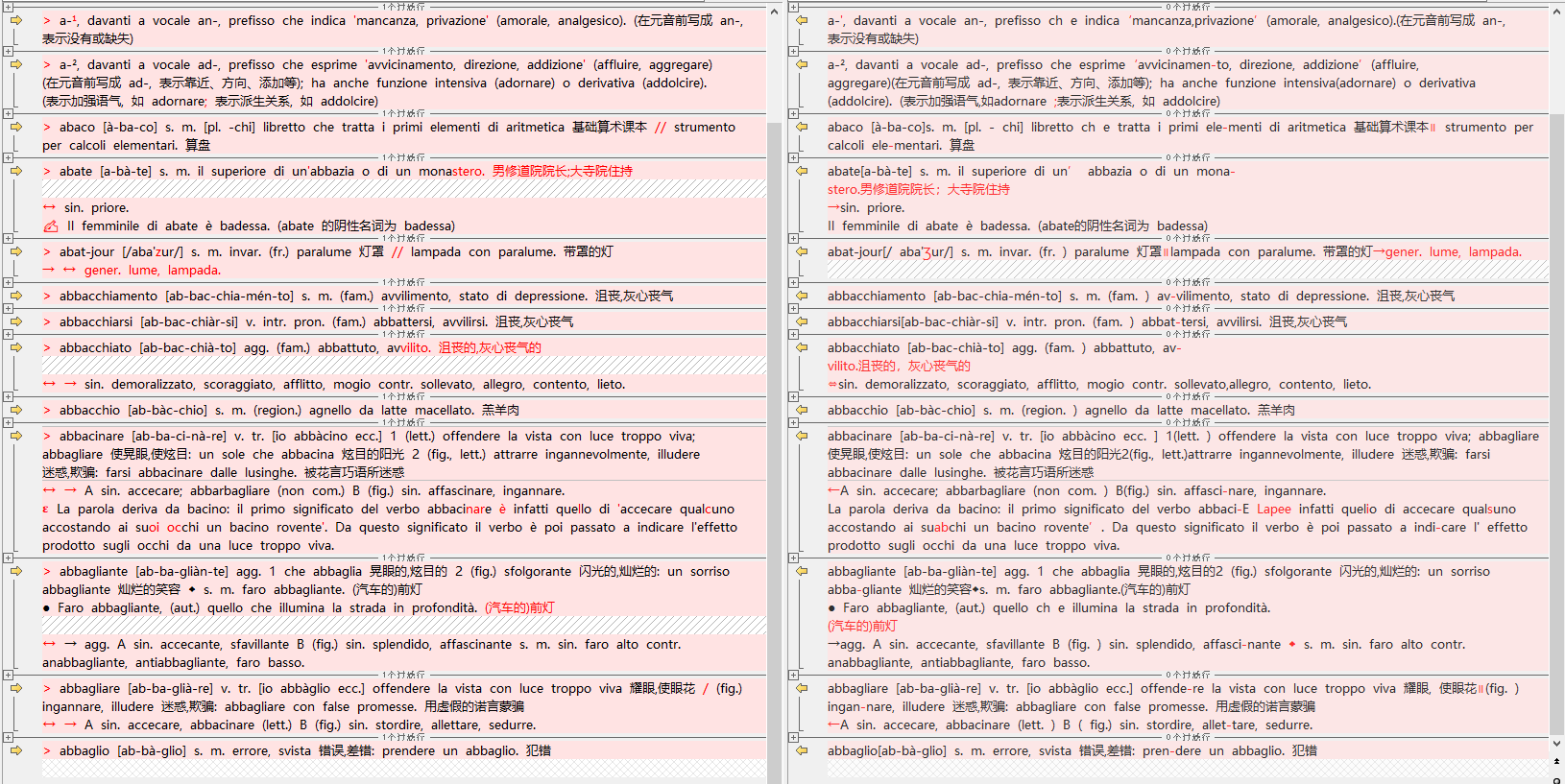
实际这部分识别只有大小写错了,词条本身没错误:
Dizionario moderno Italiano_补.txt (35.9 KB)
现在粗体是markdown表示的,运行正则表达式把
\*\*(.+?)\*\*
替换为
<b>\1</b>
的话就会好很多。
请教下大佬调用api的参数是怎么设置的,我batch_size=15就非常慢了,而且经常出错。
设置的timeout是3分钟。用的是gemini 2.5 pro跟gemini 3.0 pro preview。
我是调用的流式输出,就是google官方api的client.models.generate_content_stream(),实际识别25页文本一般要7-10分钟。
之前上传的文本少了最后一部分1701-1720页,现在已经补上了。
就是调用google的api,工具本身也是让ai写的,之前发过最初的版本,后来就是把generate_content改成stream_generate_content防止超时。
但是api key有额度限制,要自己申请,每本书要根据内容量做预处理,先找出要ocr的部分然后要切分成不同长度,这个每本书都不一样,还有就是提示词也是每本书也是不一样的,不是通用的。
和这本是不是一样的,要是一样的话这本有电子版,可以直接用电子版制作,不用ocr。
啊。对 ,正是这本。你这么一说,我对这电子版有印象了。