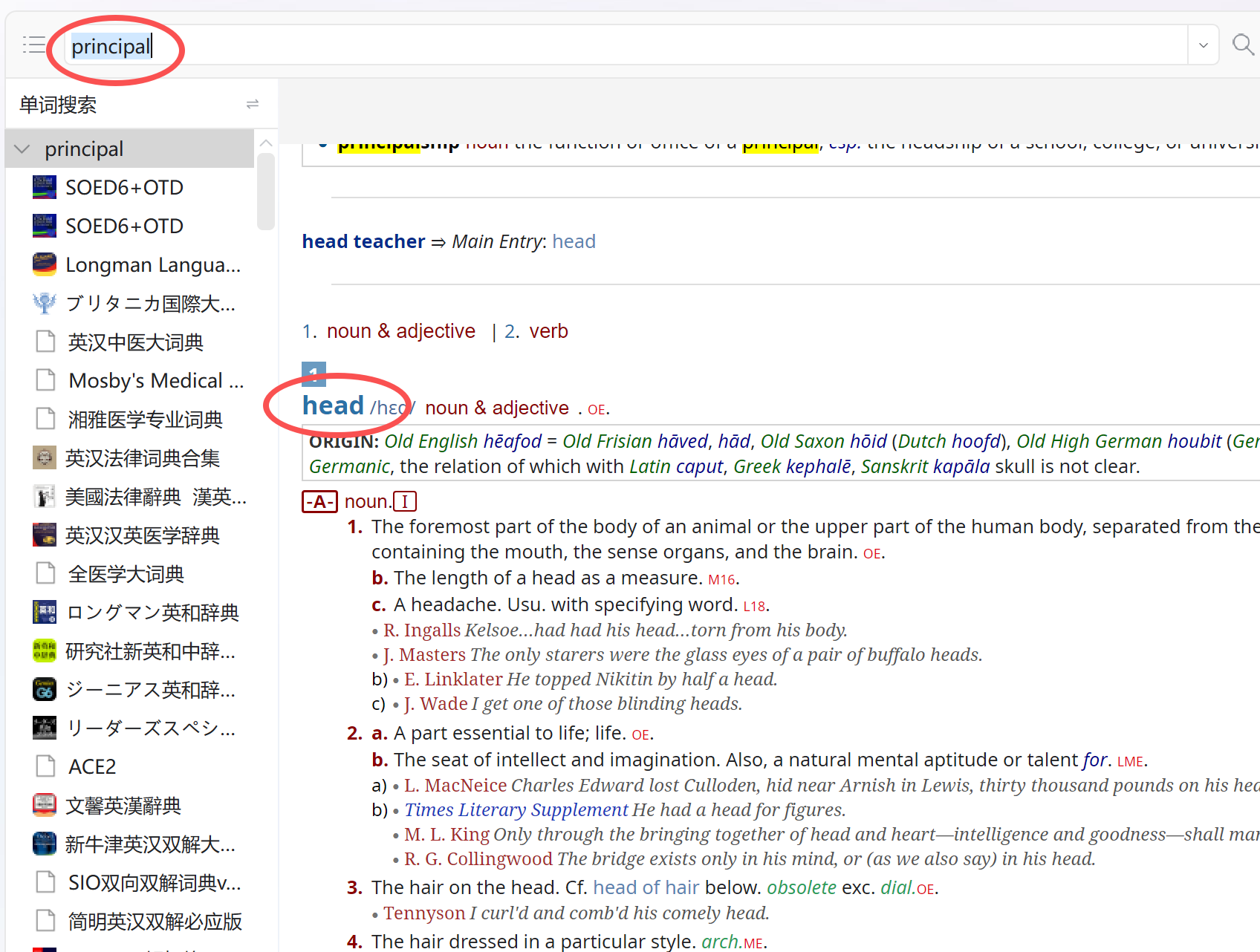
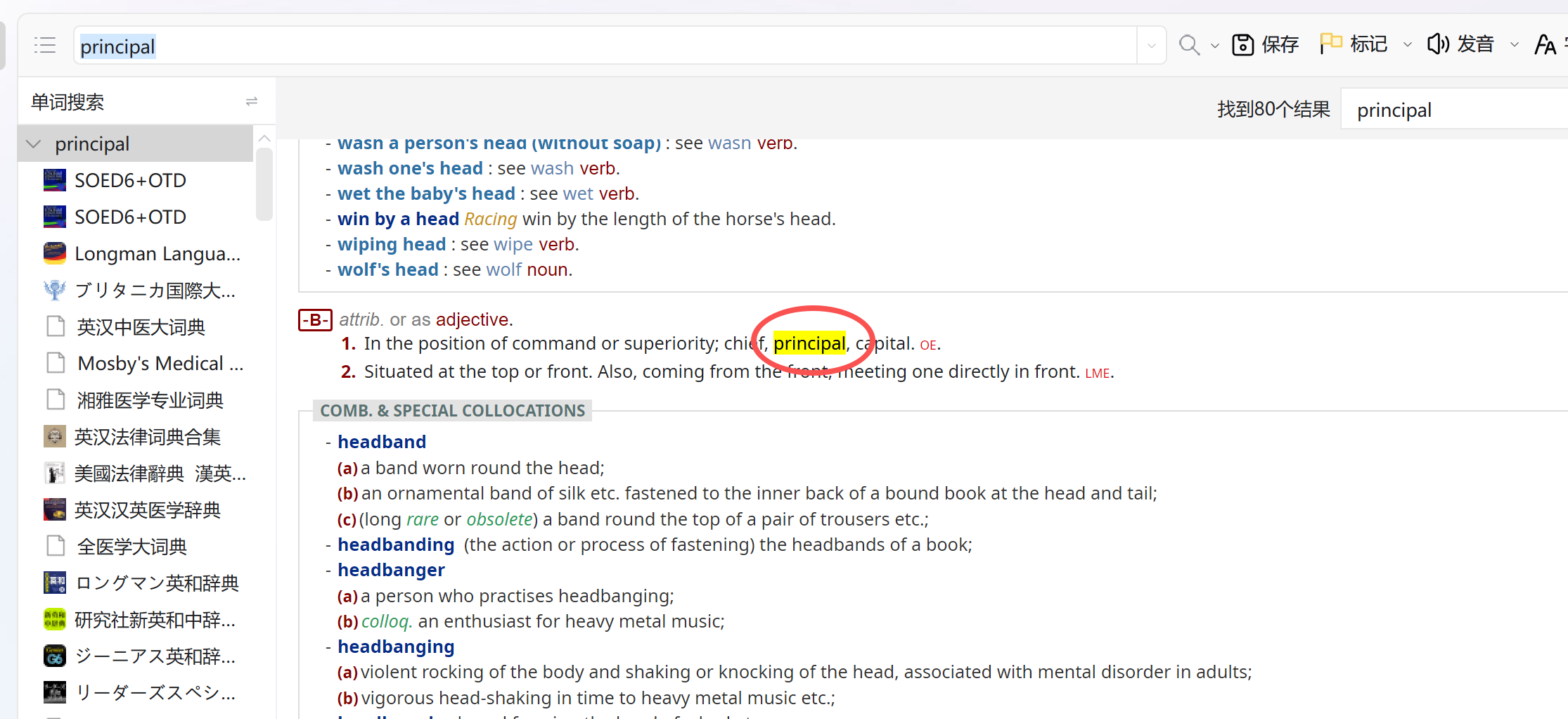
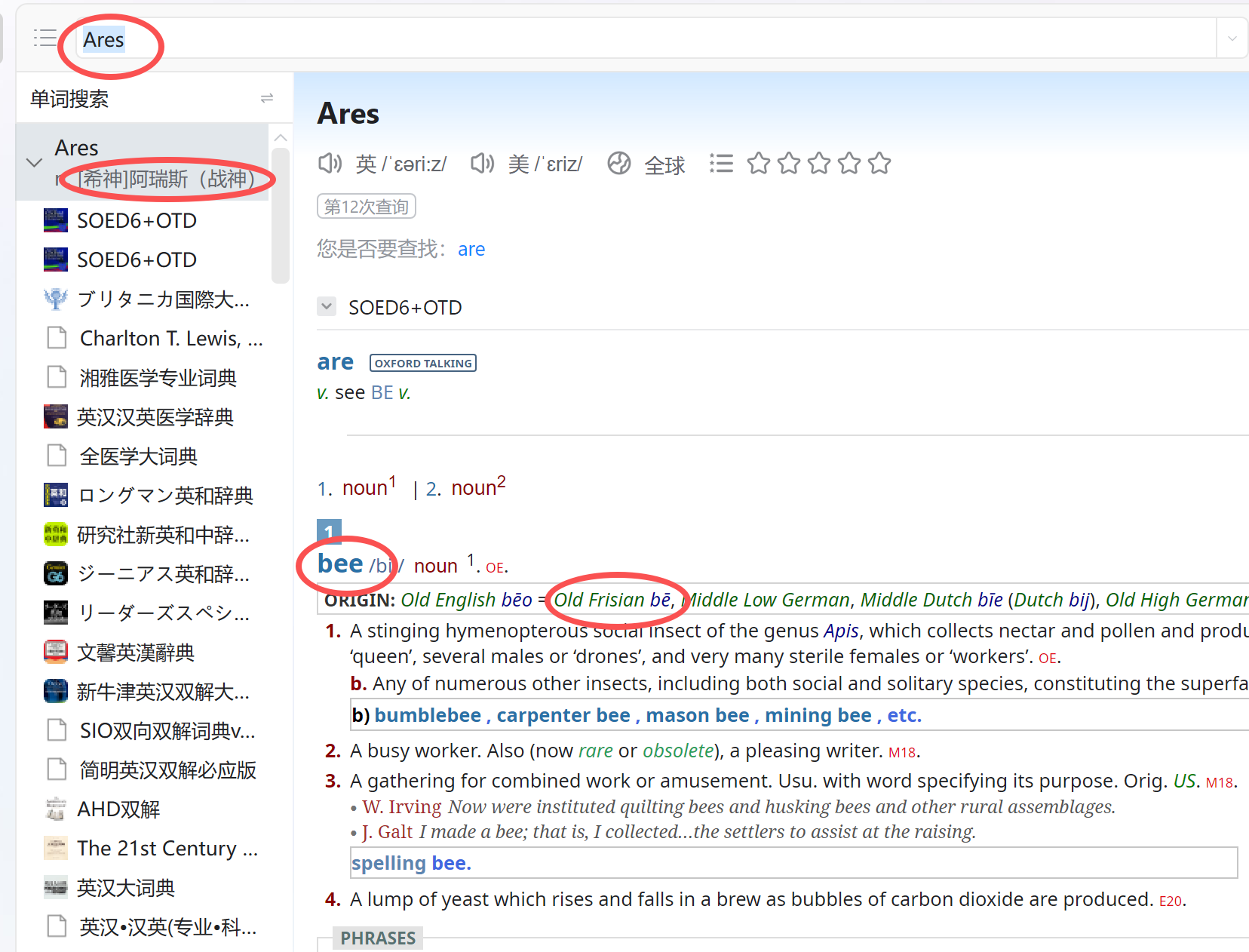
因为pdawiki几乎关站,看见有少数网友发帖求资源,遂备份此贴至freemdict,并继续做少量更新。(由于基于原贴,可能会有一些链接失效。)
简单介绍一下0xford Talking Dictionary。这是1998年,正值互联网泡沫的顶峰,在一片“形势大好”的浪潮中,为“适应新时代”,牛津倾尽资源打造了一款数字化光盘词典——0xford Talking,堪称那个时代造就的绝唱。完整内置了S0ED第4版 (和C0D8,后者容后再述),收录数千条百科词条与2700余张图片。在多媒体刚刚兴起、Windows 95主导桌面的数字启蒙时期,这样一款集声音、图像与文本于一身的作品,无疑是一项技术跃进的象征,堪称当时极为奢华的数字产品。
我在这里把S0ED4替换为最新版的S0ED6 (未包含C0D);并保留所有百科词条和插图。
此外,词典还通过引入W3曲折形态库与talking词典内置变形规则库,并结合内部词组的提取,将词头数量大幅扩展至70万条,很大程度上提升了词典的可查得性。
Oxford Talking Dictionary was originally published in 1998 and designed for windows 95. It fully integrates S0ED4, while over 2,700 vivid photographs and maps added spice to its rigor. Several thousand encyclopedic entries further consummated the platter.
We have now seamlessly replaced the previous SOED4 with SOED6 and meticulously enhanced searchability for both phrases and inflections. It is our hope that these thoughtful refinements will better unveil this old book’s enduring value in a new era.
希望我们的一些小小努力,能让这本经典重新找回它应有的位置,也能帮助更多的学习者勇攀英文的高峰。


SCHILLER

ZEBRA

PORT

Oxford Talking图片举例

图片高清化项目成果举例
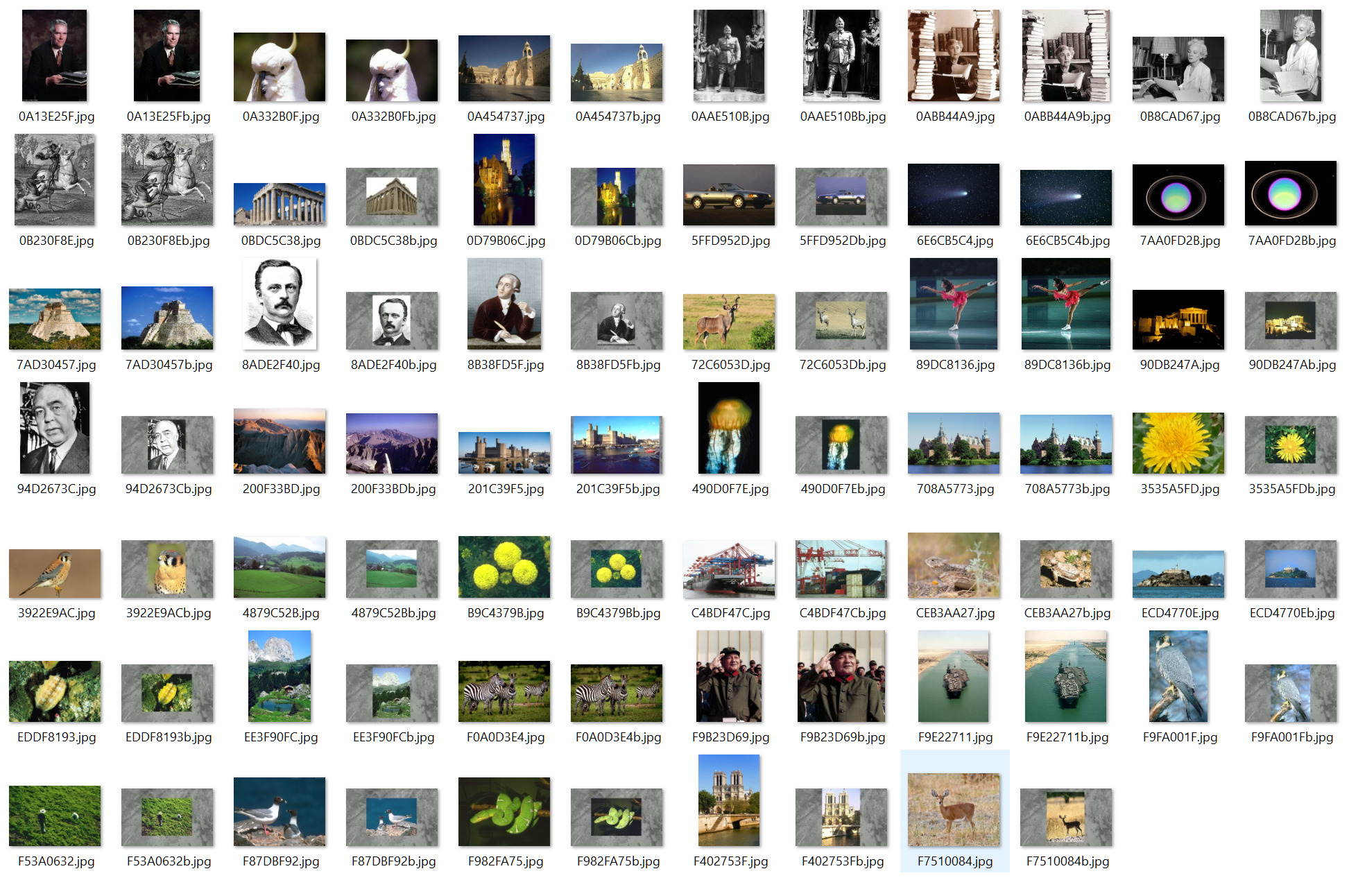
| symbol | = explaination |
|---|---|
| † | = obsolete |
| eOE | = early Old English |
| OE | = Old English |
| lOE | = late Old English |
| eME | = early Middle English |
| ME | = Middle English |
| lME | = late Middle English |
| 14 | = 1400-99 |
| 15 | = 1500-99, etc. |
| 16-18 | = 1600-1899, etc. |
| 18- | = 1800-present, etc. |
| -17 | = before 1700 (labelling Older Scottish forms) |
另外6层义项序号大小(7种序号标识)是按如下逻辑顺序:
1| -A- | I | 1. | a. = a) | (a)
例句独立单列在义项下部分,所以一个总义项下面的顺序是,总义项-分义项-总义项的例句-分义项的例句
其中无标识的例句隶属于主义项 1. 这一层的
标识为a)的例句属于次义项 a. 这一层的
S0ED6来自于Hugh大的版本,排版蓝本基于dfliaoyue改版。0xford Talking文字和图片数据都来自jonah_w提供。jonah_w提供扩容技术支持,kriskr和galcinzhang做了短语提取,志愿者帮助整理了一些LINK信息。
计划更新:
1. 已由Kriskr兄完成。计划进一步提取短语,现在查短语只有跳转,提取之后以后查短语就可以直接显示+跳转。届时将大幅删减多余的跳转。
2. 已完成,感谢V2E和wnsfzf帮助整理额外616个词的其他拼写方法,完成后将整合,提高可查性。
3. 招募志愿者 帮助为2700副插图高清化。Talking词典毕竟年代久远,很多图片其实在互联网上都有更高清的版本。通过谷歌/百度/tineye的图片反查搜索引擎找到高清版本的图片。我会随后替换。如果有兴趣可以私信我。
更新日志:
2025-09-21
- 根据反馈,修复引用词条在主词条前的排序问题。
- 删除少数明显有问题的
@@@link。
2025-09-12
- 根据 atauzki兄的版本反馈,进一步修复词头重复、空词头、不合理链接等问题,总容量从90W词头精简至约70W词头。词头问题基本得到彻底解决。
- 增加少量缺失链接词头如χ。
- 继续高清化少量图片,如steenbok, cathedral, boa, gull, tea, peregrine, aircraft carrier, chalet, Alcaatraz, horned, marigold, Pyrenees, kestrel, dandelion, castle, jellyfish, Caernarfon, whitney, Bohr, acropolis, skate, Lavoisier, kudu, Helmholtz, Mayan, convertible, belfry
2021-03-03
- 海上1212兄帮忙进一步修复html tag缺失、多余、交叉等问题。并通过代码验证所有标签均闭合。
2020-11-01
- Kriskr兄帮忙删除不恰当的词条重定向,深度提取词组。
- 一些图片更新成了高清版本
2019-10-30
- 调整序号排列,增加a) b) c)逻辑层
2019-10-27
- 修正数个排版的小问题
- 修正256楼提出的多词条欧路跳转不畅的问题
2019-10-26 初版
- 修复巨量的html错误,包含未闭合html tag,为之后提取短语铺平道路
- 让6层义项层次符合逻辑
- 合并Oxford Talking百科词条和插图
- 增加跳转(之后会继续精简)
SØED6+ØTD.txt (151 Bytes)