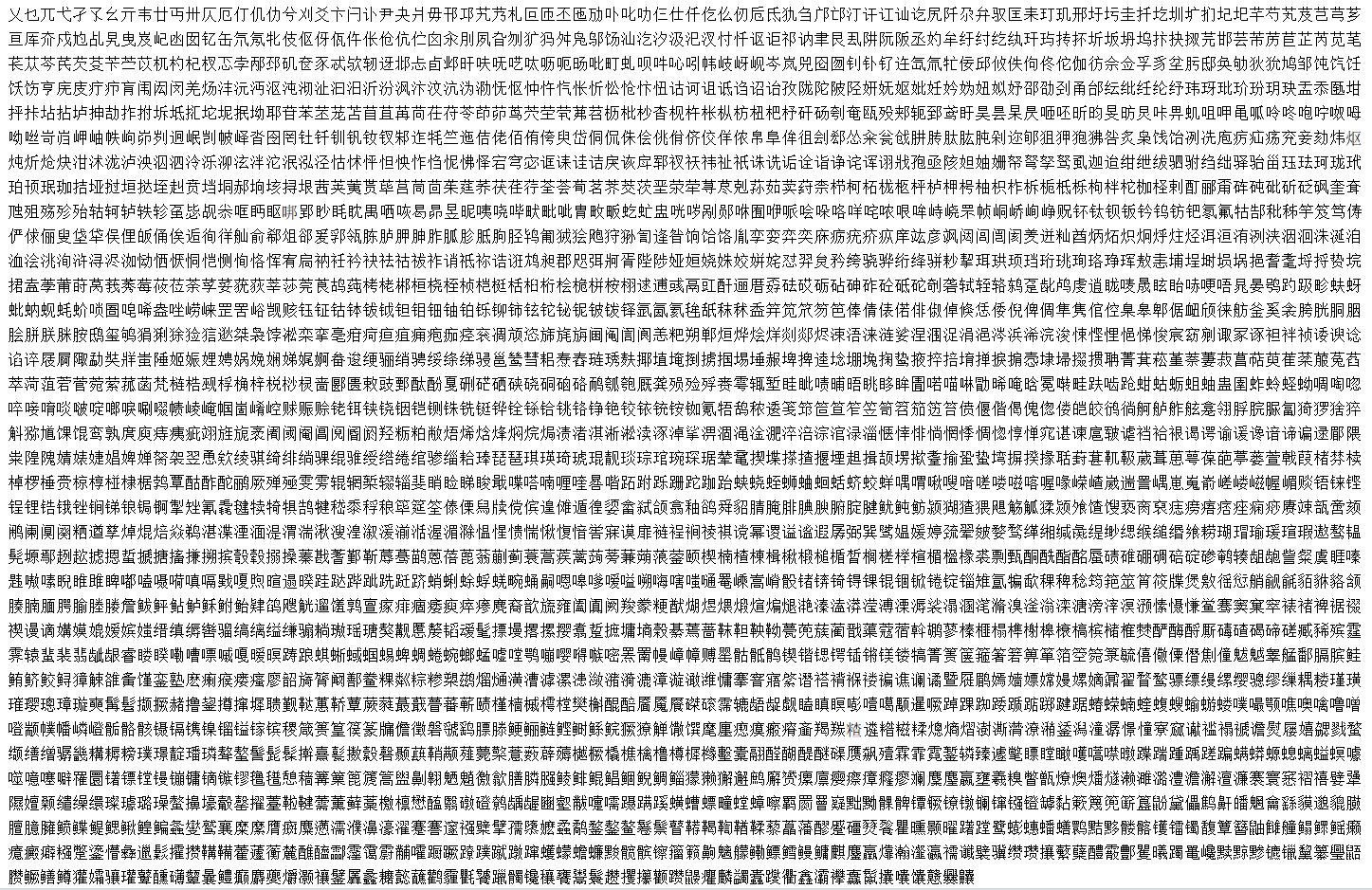单开一贴,总结下常见 OCR 引擎的识别结果。
省流不看版:
通用字文档识别率: 合合 > 有道 = 谷歌 AI > 阿里 = 百度 > 火山
生僻字文档识别率: 合合 = 有道 > 火山 > 谷歌 AI > 阿里 = 百度
识别率最高:合合 0.050 元/页
性价比最高:有道 0.007 元/页
样本一:汉语成语源流大辞典
测试图片:1468_0.png.zip (3.2 MB)
PaddleOCR(开源): 生僻字、拼音无法识别,标点符号正确
- 专(阃)久膺 // 错字:阔
- 孙(膑)兵法 // 漏字
- 五(一) // 漏字
- 分卒守(徼) // 错字:激
- 二(〇)八 // 错字:O
- (缮)甲兵 // 漏字
EasyOCR(开源): 生僻字可以识别,拼音无法识别、标点符号错误很多
- 袁(枚) // 漏字
- 排(日)出署 // 错字:月
- 奕(䜣) // 错字:诉
- (汉)墓、(汉)书 、(汉)王、(汉)之粟、 (汉)齐盖庙碑 // 错字:汊
- 汉(王) // 错字:壬
百度高精度: 生僻字可以识别,拼音漏了两处声调,标点符号正确
- 奕(䜣) // 错字:诉
- 孙(膑)兵法 // 漏字
夸克扫描王(阿里): 生僻字识别错误,拼音全对,标点符号正确
- 专(阃)久膺 //错字:间
- 奕(䜣) // 错字:诉
扫描全能王(合合): 生僻字可以识别,拼音全对,标点符号正确
- 奕(䜣) // 错字:诉
- 二(〇)八 // 错字:O
白描(有道): 生僻字可以识别,拼音全对,标点符号正确
- (一) // 错字:-
- 二(〇)八 // 错字:。
火山引擎: 生僻字可以识别,拼音漏了三处声调,标点符号正确
- 分卒守(徼) // 错字:微
- 二(〇)八 // 错字:0
谷歌 AI:生僻字识别错误,拼音全对,标点符号错两处
- 大(孚)众望 // 漏字
- 专(阃)久膺 // 漏字
- (圣)明洞鉴 // 漏字
- 九(一) // 错字:-
谷歌AI 8 月新模型:生僻字识别错误,拼音错三处,标点符号错两处
- 专(阃)久膺 // 错字
- 九(一) // 错字:-
- 二(〇)八 // 错字:o
- (一)7 // 错字:-
感谢 匿名1664 提供 EasyOCR 的识别结果。
感谢 将作大匠 提供夸克扫描王和扫描全能王的识别结果。
感谢 soso 提供白描的识别结果。
感谢 Chengzhir 提供谷歌 AI 的识别结果。
感谢 random 提供谷歌 AI 8 月新模型的识别结果。
样本二:中国古代史教程
主要任务是测试生僻字的识别。
测试图片:072.jpg.zip (484.3 KB)

合合: 错漏 0 个字,标点符号正确
有道: 错漏 0 个字,标点符号正确
火山引擎: 错漏 0 个字,标点符号正确
谷歌 AI 8月新模型: 2 个错字,标点符号正确
- 铜(铙) // 错字:饶
- (盉) // 错字:盃
百度高精度: 错漏 5 个字,标点符号正确
- (甗) // 漏字
- 铜(铙) // 错字:饶
- (觯) // 错字:解
- (卣) // 错字:卤
- (觥) // 漏字
阿里高精度: 错漏 8 个字,标点符号正确
- (鬲) // 漏字
- 铜(铙) // 错字:饶
- (觚) // 错字:缸
- (觯) // 错字:鯽
- (卣) // 错字:卤
- (盉) // 漏字
- (觥) // 漏字
- (瓿) // 错字:部
上述引擎的识别结果:072.zip (499.6 KB)
样本三:留声机与清末民初的世俗文化
主要任务是测试完整单页的识别。
测试图片:085.jpg.zip (700.1 KB)
此次测试总计 860 个汉字,138 个符号。
合合: 汉字 0 个错误,符号 0 个错误
谷歌AI 8月新模型: 汉字 0 个错误,符号 0 个错误
百度高精度:汉字 0 个错误,符号 2 个错误
阿里高精度:汉字 1 个错误,符号 1 个错误
- 年 // 幻觉:(全)年
有道:汉字 0 个错误,符号 3 个错误
- ①②③ // 符号可以识别,出现 3 个错误
火山:汉字 4 个错误,符号 7 个错误
- (阶)层 // 错字:防
- (时)// 错字:日
- (20) // 漏字
- (段) // 错字:县没
- ①②③ // 6 个符号都无法识别
上述引擎的识别结果:085.zip (708.5 KB)
欢迎补充其他软件的识别结果!