各位论坛大佬你们好。
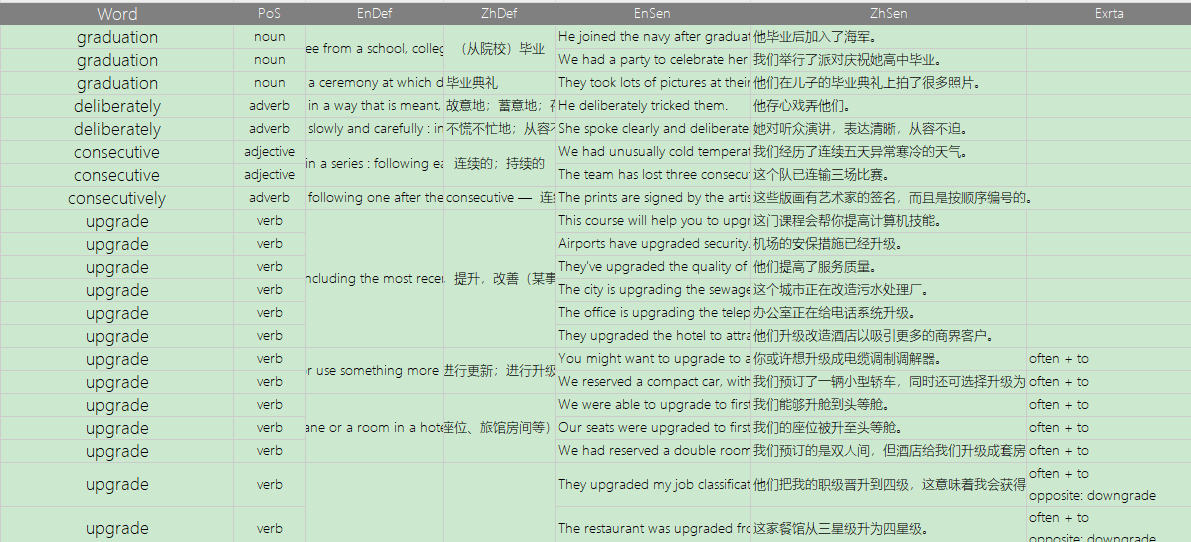
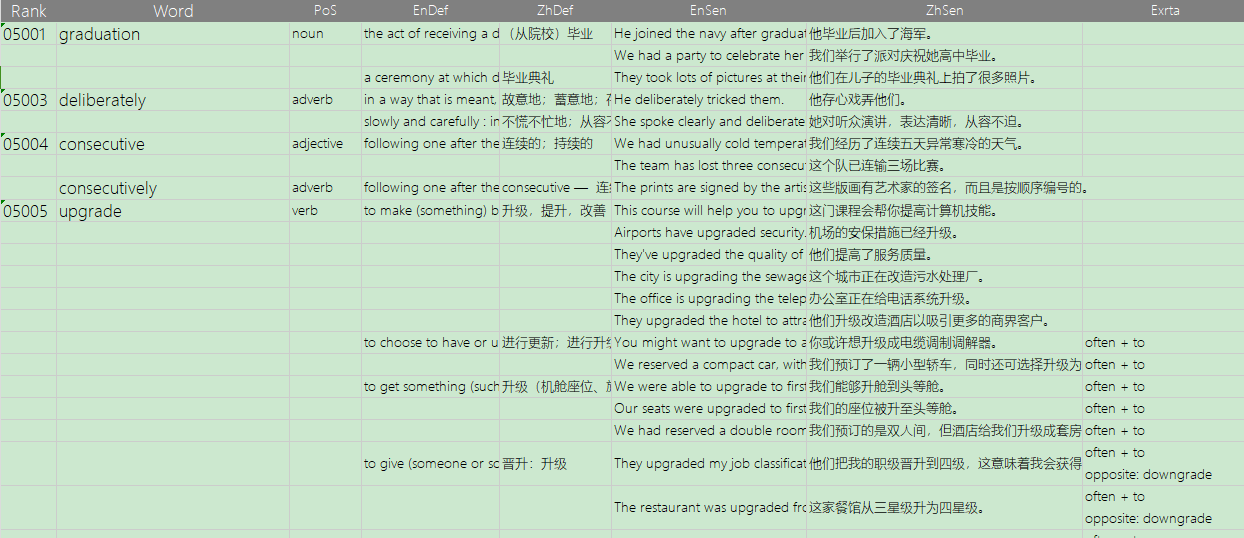
我目前在使用韦氏高阶双解v3词典配合Anki来背单词,我的学习方法是单词的每个例句单独制卡,但是手动复制每个例句以及对应的释义,粘贴到表格再导出到Anki,真的太耗费时间了(如图)
非常希望有大佬能帮助指导下:
整个释义包括例句是在div class="sense"里的

但是释义通常都包含多个例句div class=“vi_content”
求教如何能导出到Excel表格,并且使多个例句对应一个释义呢:
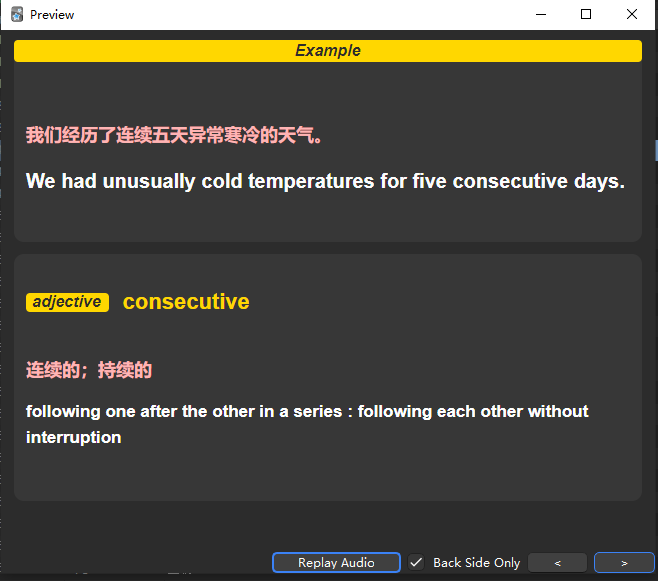
或者如下图一样,仅第一个例句有释义词头等,剩下的可以靠excel自动向下填充
PS:看到之前有大佬们做过朗文5的拆解, 但是没有放出数据 :smiling_face_with_tear:
@hua 不知道您有没有当时的数据,或者能告诉我该怎么拆解呢,感谢
PS:此为词典链接:
1 个赞
简单的资料提取通常可以做得到,但得自己做,没人这么闲空帮人做。
我举一个假设性的例子,假设某词典的例子都有<example>This is an example</eample>标签。
1.先用mdxexport把mdx变成文本。详见《新手指南:怎样编辑mdx?》。
2.先用Emeditor让<example>都变成独立一行。
replace <example> with \n<example>
注意必须选勾regular expression(正则表达式)。
3.用Emeditor find – extract <example>。
例子就全提取出来了。
这只是例子,不包括对应释义。你如果需要复杂的释义一一对应于例子的格式,那就需要复杂的编程,我就不说了,
1 个赞
词典链接、例句需求(只要例句不要词头吗?css还要吗?例句数量多要精简为每个释义的第一个吗)
excel 格式?可以根据 14.1 文本文件导入 | Anki 官方文档翻译 你做一个文本例子吗,没用过 anki 和 excel 数据io
wyq
4
感谢,例句都是在div class="vi_content"里的。问题正是是如你所说的,一个释义对应多个例句的问题,目前也是没有头绪,请问还能细说一下这部分的编程思路吗  我会更新一下主题帖,给出更多信息
我会更新一下主题帖,给出更多信息
感谢回复,此为词典链接:
需求是,每个例句带上它对应的释义、词头以及词性(如图,手动制作,但这样太耗时间了),不需要css,纯文本表格就可以
请问有什么思路吗 
17万个句子,10万个水分词头,5万个非链接词头,1.4万个衍生重复词头(未去重),1.4万个只有释义没有例句的词头未收入。
1 个赞
你是我的英雄!python我还一窍不通,容我先照着你的code学习下 。请问这个表格就是词典的全部词条的例句了吗,如果是的话102258条好像比想象的少哎 
朗文真人例句牌组(A1-B2级)我之前做例句卡片是一边看词典一边手动录入的,主要改词典的js,实现点击例句自动整理并复制,然后通过python检测剪贴板写入到txt再批量导入到anki。
如果你考虑看词典可以参考一下,我并不太喜欢自动制卡
感谢你的coca,在我制卡中也有帮助
Waylon
10
嗨gtxxeon,请问这样的方法点击例句有可能自动把对应的释义也复制进去吗,如果可以的话这个思路还蛮有用的 
要啥拿啥 js功能还是很强大的。我拿了发音,例句和翻译。我觉得例句法就在于忽略孤立的单词,我就没要其他。但要是保留层级信息可以实现每次一个释义出现不同例句,我很后悔
本质就是用正则匹配要的东西嘛,有gpt很简单
Waylon
12
你提醒到我还有gpt这个好东西了,我先试试让它教我@匿名1669 的代码

,确实我自己也是要看一遍的,但目前还是更倾向自动制卡+手动校对了,thanks(GPT看起来很聪明,会自己猜mdx文件是三行一个循环)
Waylon
14
感谢,这个看起来只包含例句了,难点还是需要对应的释义。无论如何谢谢你的回复,不然我可能永远看不到这个帖子。
匿名1669
15
直觉很准嘛,17万个句子(未去重)
mwald_anki.xlsx (16.5 MB)
mainC.py (5.8 KB)
Waylon
17
刚看了新的这版代码,好家伙又看不懂了哈哈
刚刚:我又想了想,不对呀,我在excel里把序号匹配给能对应上的词头,一排序不就有了  何必再改python
何必再改python 
Waylon
18
2024/6/13:去重后跟COCA词汇表匹配了一下,词典全14.6万例句,COCA前6万词覆盖了13.8万的例句,前2万词覆盖了12.1万。
 看着太有难度了,原本以为会少一点的
看着太有难度了,原本以为会少一点的
背单词图的是效率 这样多少有点南辕北辙了。1w例句的压力已经非常大,而且未经筛选的例句生词多,不能突出中心词