ppxia
1
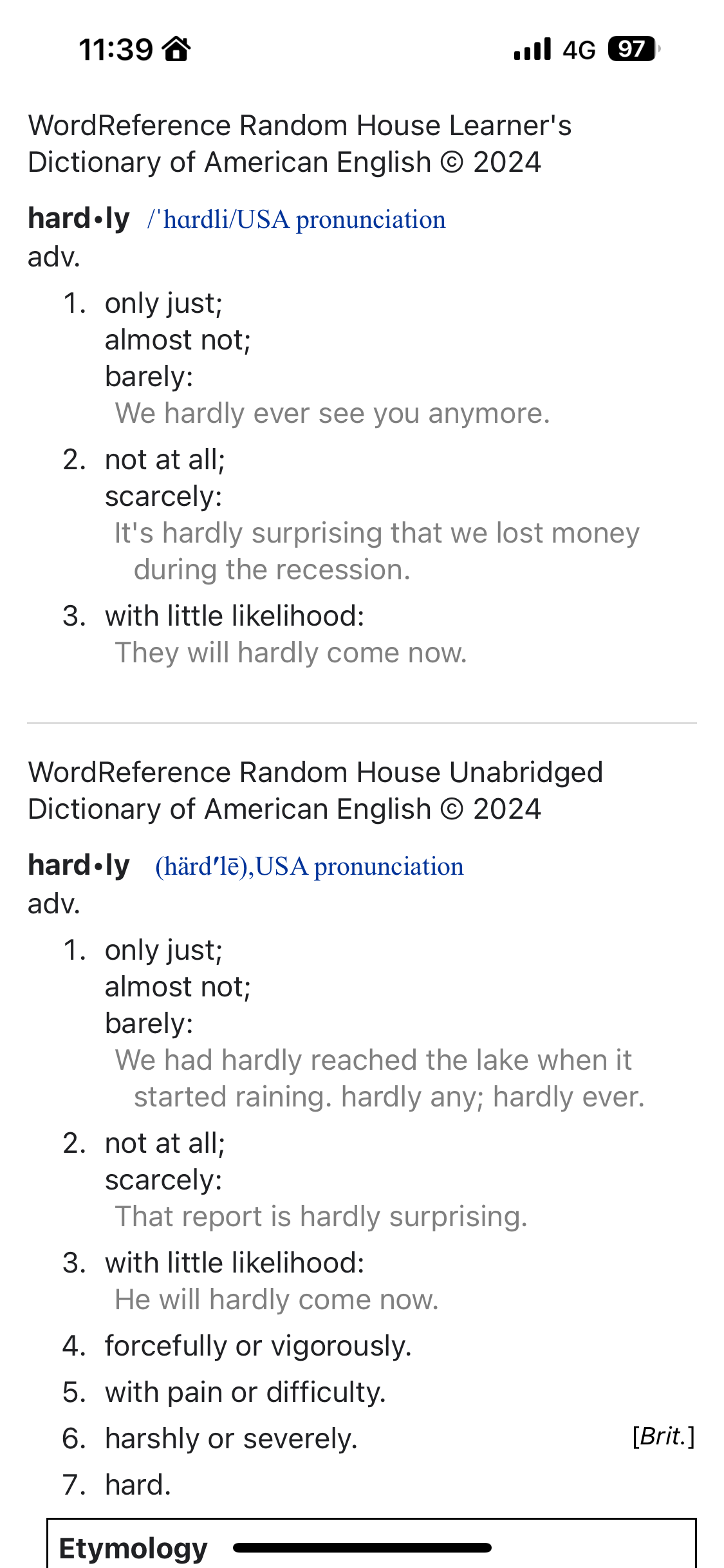
WordReference Random House Learner’s Dictionary of American English © 2024
WordReference Random House Unabridged Dictionary of American English © 2024
Collins Concise English Dictionary © HarperCollins Publishers::
词条数:(原始版本)
Entries: 188688 (incl. 1383 LINKS)
词典分离版本的词条数(内容全去重,根据rh_me、rh_ros、var添加词头链接)
RHUD: 135168 entries + 41231 links
RHLD: 25913 entries + 8760 links
Changelog:
20240328: 词头+内容去重,RHUD和RHLD的单独版本mdx
20240329:更新mdd里面的css,隐藏词典名字和底部分割线。
20240331:更新RHUD和RHLD,删除mdx中的解释前置的词典名字和释义底部分割线,添加词头链接增加查询可用性(以rh_ros、var定位)
20240405:更新css文件以补充部分缺失的样式(请删除原mdd文件,下载css文件使用即可)
Todo list:
词组提取添加词头链接(以rh_def定位,不确定可行性)
【已完成】删除mdx中的解释前置的词典名字和释义底部分割线,添加词头链接增加查询可用性(以rh_ros、var定位)
【没必要添加,音标本身无链接】添加音标词条
链接:
下载mdx和css文件即可(css文件对RHLD/RHUD均通用)。原mdd文件不再适用。
RHUD、RHLD分开的独立版本
原来在用论坛里面的WR2021,也很好用,但词头里面冗余数据稍多一些,所以花了1周试着重新抓取2024数据做了一版。
主要还是以原来Random House的词头为基础来抓取,所以没有把3本字典分开做tab(collins可能遗漏会多一些),感兴趣的可以自己改造。
内容仅供测试。
后面是制作过程中的一些笔记,供感兴趣的伙伴参考。
未解决问题:
代理池使用:只是能让proxy_pool跑起来调用,但用起来死链多,效率不高。想看看一下有没有大佬指点一下可以参考的其它思路,或者好资料、好资源。
尝试过用headers列表来减少被识别反爬,但似乎作用不太大。
没有词头列表怎么办?
- 从其它mdx提取词头
- 官网在词条的左边栏和中间栏分别有see also和also found栏目,保存并用于扩充词头(但这点对于孤立词头无效)
- robots.txt里面没找到有用的信息
词头包含特殊字符的处理
这次只碰到"/“符号的问题,所以统一用”_“来代替,也方便后面还原(词头中本来不存在使用”_"符号的情况)
忽略了返回结果的多样性,前期只保存了部分结果,后期无法有效清洗
前期爬取时只保存了otherDicts内容,判断内容时只用了:
- g-recaptcha判断是否需要验证
- 用noTransFound判断是否无结果
结果在整合时发现还有:
- WarnNote(其实也是未找到但会返回其它结果供参考)
- showingFor(类似词头跳转)
无奈只能又重新再爬取一次。
结论:发请求保存网页是最耗费时间的,应该先保存更大范围的内容,后期清洗再做内容的修剪
第一次使用concurrent.futures.ThreadPoolExecutor来做并发多线程爬取,效率确实高不少,但容易跳验证码。
代理池
用过开源的代理池,代理质量很差, 可用ip预先请求目标网站一次,保留成功的再进行使用
没有词头列表怎么办?
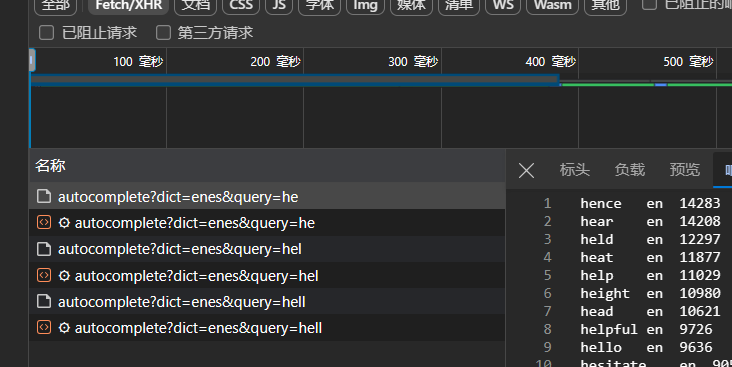
可以通过 autocomplete 接口获取, 构建单词组合穷举
词头包含特殊字符的处理
可以进行urlencode编码
Tab 版本
体积从85MB 降到 35MB,主要是style进入css文件和去重。
另外把实际词头分开了(比如running词头以下的run剥离进入run)
三个字典。
Collins Concise
RHLearners
RHUD
ppxia
5
感谢提供思路。之后我试试 
我本意倒不是担心url拼接问题,就是文件保存时候我都用词头的全小写作为文件名,脚本会检查是否已经保存过同名文件。不知道这方面是否有更优解?
文件名建议使用行号。词头可能包含非法字符,或者同名词头。
ppxia
7
感谢分tab版本。
能否指点下思路或者分享代码,怎么做到词条内容去重的同时保留原有词头?是用headerWord标签来重新匹配吗?
我猜是否直接删除run的部分?实际使用中,偶尔可能会存在错配。不过也可能是数据本身需要进一步处理。
比如run in这个词条,会错配到RHU的run-in,但RHU里面run下面还有单独run in的释义。
ppxia
8
我之前用的办法比较原始,我代码放在下面,帮忙指点下。如果用行号保存,怎么检查呢?
脚本启动时,先重新生成新的词头列表
def updatewordlist():
# 生成新的词头列表,去除大小写
# 读入去重的原词头列表
with open('wordlistV2', 'r', encoding='utf-8') as wordlist_old:
wordlist_V2 = set(map(str.lower, wordlist_old.readlines()))
# 读入errors.log并且进行去重、排序、重新写入
with open('errorsV2.log', 'r', encoding='utf-8') as errors_old:
errors_log = set(map(str.lower, errors_old.readlines()))
with open('errorsV2.log', 'w', encoding = 'utf-8') as new_errors_file:
new_errors_file.writelines(sorted(errors_log))
# 读入已保存文件的词头列表
with open('htmlfilesV2', 'w', encoding = 'utf-8') as htmllist:
html_files = {file.rsplit('.', 1)[0].replace("_","/") + '\n' for file in os.listdir('raw') if file.endswith('.html')}
htmllist.writelines(sorted(html_files))
# 读入已保存文件的词头列表
with open('linkfiles.list', 'w', encoding = 'utf-8') as linkfilelist:
link_files = {file.rsplit('.', 1)[0] + '\n' for file in os.listdir('link') if file.endswith('.html')}
linkfilelist.writelines(sorted(link_files))
# 删除not found的词头、已保存文件的词头,并且保存成最新需要抓取的词头列表,并且全部变成小写去重
wordlist_final = sorted(wordlist_V2 - errors_log - html_files - link_files)
with open('wordlist.new', 'w', encoding='utf-8') as output_file:
output_file.writelines(wordlist_final)
print("wordlist has been updated!")
保存文件时
if (os.path.exists(fullpath)):
print(f'{word} : already exist')
return None
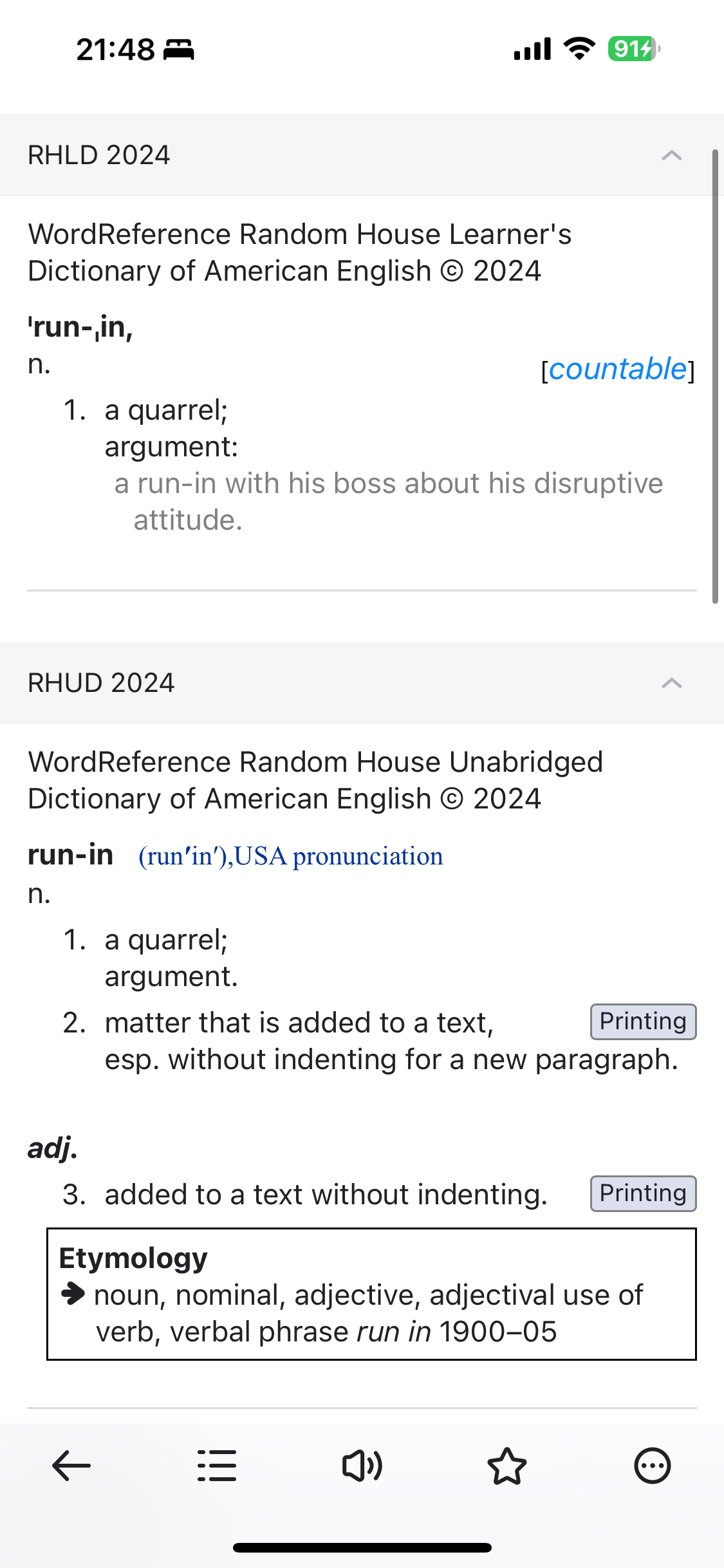
同一个字典内容相同,就保留一份,其他的指向那份即可。
网站会把很多类似的词头放到搜索关键词底下。把词头分开就行了。
run-in 和run in是不同的词头,没有必要合并。
ppxia
11
抱歉刚才可能没说清楚。不过我又去官网查了,本来源数据的指向也跟您的tab版本一样,靠我们后期修正估计也不现实,就先不用管它了。
搜run-in出来的结果符合预期。
但搜run in的结果不太对,collins因为run in和run-in两个合一起出现所以没问题,但RHU和RHL只显示了run-in的释义。(官网自己也是这样,只是后面还附了run的完整释义)
估计是因为RH没有把词组单独作为词头 (在run底下)collins作为词头了。
解决办法就是提取RH词组。目前不打算折腾了。
css就是楼主版本mdx里面style tag的内容。
ppxia
14
思路大概是理解了,就是把a词头里面不直接属于a词头的部分删除。
能否展开说说代码层面怎么操作的?我没想明白怎么样可以匹配定向删除内容。
每个词头加内容,先把内容按字典切割,然后不管mdx是什么词头,找到内容里面的所有实际词头,把内容放在这些词头下,因为只有一份内容per字典,第二以上的实际词头只是一个link指向第一个词头的内容。这里完全不删除任何内容,只是把它们重新定位于实际词头和字典以下。
然后全局去重,重复部分变成link。比如run重复出现在running和run里面,重组的字典会出现多次完全同样的run内容,而且还在run词头下,不在running下。这时候全局就会保留一份,其他变成link。此后重复的link再次去重 。
Where is this version downloading link?
Click on the first word tab.
this is how it works:
[spoiler]example[/spoiler]
I’m talking about this modify version. Above tabbed version, I have downloaded it.