- 三体I-中英段段对齐csv下载:threebody-1-zh-threebody-1-en-csv.zip (523.3 KB)
对齐费时约40秒!需联网。
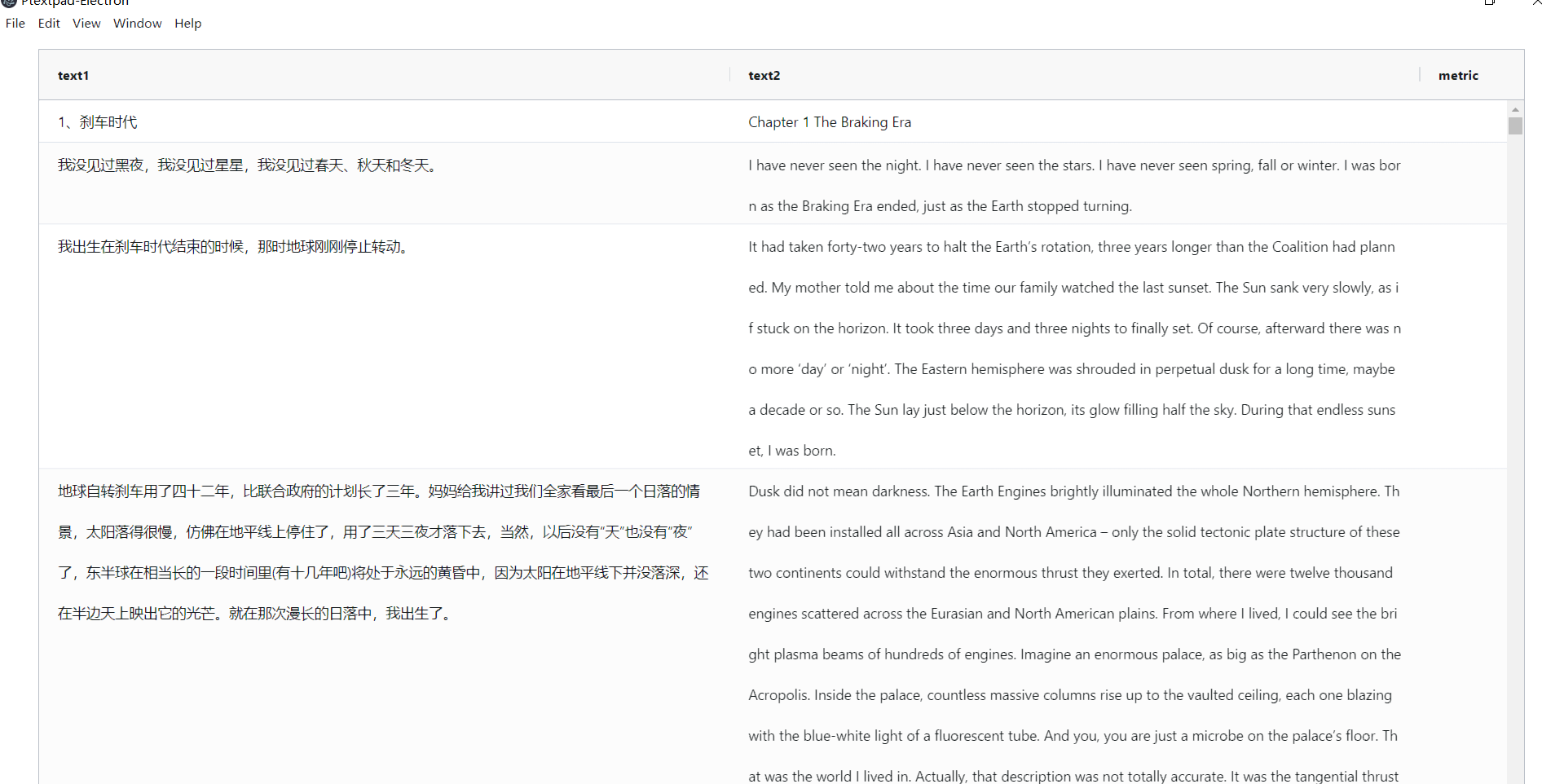
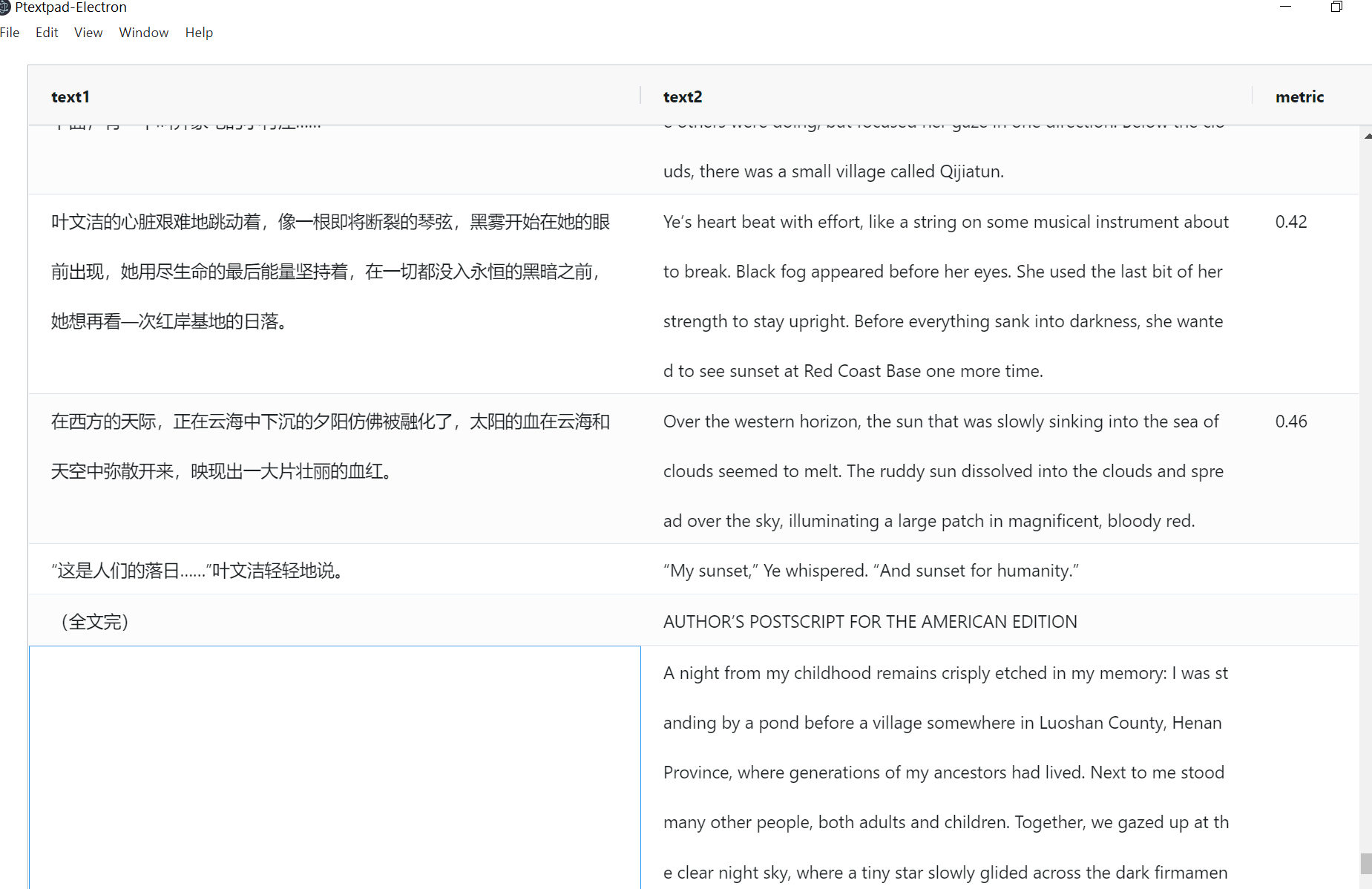
- ptextpad界面
-
ptextpad测试版0.0.3-0安装包(Windows10)下载(freemdict云) FreeMdict Cloud
-
参看另一个贴 Ptextpad + 双语对齐工具网页版 mlbee(任意语言对) + 其他bee系列对齐工具 - #130,来自 mikeee
ptextpad测试版0.0.3-0安装包(Windows10)下载(freemdict云) FreeMdict Cloud
参看另一个贴 Ptextpad + 双语对齐工具网页版 mlbee(任意语言对) + 其他bee系列对齐工具 - #130,来自 mikeee
不能选择安装路径这点很不好,不是谁都喜欢安装在C盘
可能服务器那边出了点问题,正常第三列会有些数字,表示相似度的…… 我找找bug在哪里
多试了几个例子,好像段数太多了会出现第三列空白无对齐的情况。具体原因现在还不清楚,可能与服务器内存不够或类似的有关系。服务器是别人的,有时候外网端口不回应请求。需要时间找出原因才能修补。
你弄个离线版就是了,干嘛还要用服务器?难道句子对齐的运算还需要电脑内存达到TB级别?我测试的那个流浪地球的文件算是小说中的短篇了,都比你测试用的那个小说短很多倍。我测试之前还真以为你这个软件经过修改这么久超越了ABBYY Aligner呢
最后会整个单机版。但因为对齐部分是用python实现,而且几个第三方库都比较大,凑一起近1G。加上安装及操作时也会更复杂些,所以弄了个服务器版。只需下载70M的文件就可以走起来。
对齐需不需要大内存要看对齐的段数,对一本书还真的需要十几G几十G的内存。
自认为这个软件的核心部分确实超越Abbyy Aligner。不过因为我不是专业开发软件的,实现起来各种地方都有出bug的可能。你可以试试这个网络版 http://forindo.net:8501/ ,和 Abbyy Aligner 的对齐效果比较一下。
你前面提到的 ptextpad 安装时不能选择安装路径并不是我设置的。我用了 electron-builder打包,它就整成了这样。我再看看有没办法解决。
开发这个软件纯属业余,加上还是测试版,不便之处,多多包涵。
是不是按章节分大段可以减少内存使用?
你这人说话语气能不能好听点儿?好多热心的朋友都是被你们这种不咸不淡、冷嘲热讽的腔调给弄得没了动力?
不知道你这样到底有何居心?是为了显摆自己,还是要破坏论坛?
不错的想法,但问题是对齐段可能被分到另一组里,所以有点像先有鸡还是先有蛋。除非假定错位数不会超过某个数,不过最后会搞得复杂。
其实到最后得到的是个 原文段数x译文段数 的大矩阵。再用一些clustering算法定位候选对齐段。用到的这个clustering算法费内存,在本地我的本子上运行大致5000段对就会OOM。ptextpad-electron用的服务器有64G内存,不过同时机主有几个程序在运行(java之类的,动辄十几G)。
不太能理解对齐的算法这么复杂?难道你是假设两种语言中对应的句子的顺序是打乱的?不是我想象中的英文、中文两个译本拿过来简单地调整一下错位?
目前的問題只有一個,隨著文件變大,處理效率急劇降低,近乎無法使用。
我之前是把大文件分割為很多小文件。能不能根據相似度,化整為零,自動切分,由代碼處理。
比如:百萬級別的海量雙語段落,先只切分處理前1000。假設第800段落是較為靠後的高可靠、高相似度段落,那麼以800作為一個分割,下一次就只處理801-1801。
這樣一來,實際使用體驗可能會提高幾十、幾百倍。
之所以复杂是要考虑原文和译文并不是一一对应的。比如上面的三体一,译文可能有前言、译注,译者感想等等,译文也可能用了另外一个原文版本,译者也可能加译(例如舫舫日记的译文加了不少段落),等等。即便手动删掉与原文不相关的东西,译文和原文多数情况下也不是一一对应的(如果是一一对应的就没什么好对的了)。如果想体会一下,可以用中英书的某一章(别太短)试试 Abbyy Aligner。
如果只是中间带有非对应的内容,整体上的对应句子的顺序还是一致的,@hua 建议的按章节大致切割一下应该会大幅提高运行效率。
ezbee是可以微调两个参数的,有个开关可以显示对齐轨迹。但如果段数太多,显示对齐轨迹就会有很多像点(例如10000段对就会有一亿个像点)显示出来很费时间。所以要在图形界面交互设置也不太实际。所以就设定了固定参数。段数太多并且干扰太多时固定参数就不是最佳参数了,会影响对齐质量。
段数太多时还要想想怎么能够解决。一章一章对大致不会有大问题吧。
问题是怎么找到原文章节及对应对应译文章节的位置…… 所以实际是分组对齐,但如何自动分组呢
根据我有限的理解,如果不强制分割,随着处理单元的增大运行效率是指数级降低的。
这个办法倒是不错,主要问题是无法保证高可靠度、高相似度段落,如果某个高相似度段落实际是错的,那么后面的就全部乱套了。这个其实也是 Abbyy Aligner的问题之一。
除非用手动设置高相似度段落,这也是 ptextpad 的另一个潜在功能(不过目前还没实现)。
不是这个行当的,理解很可能是错的。现在的机器翻译引擎本来就是用海量的双语对照语料库训练出来的,翻译工作者费很大劲自建双语对照资料库作为辅助翻译工具,似乎不如直接参照现成的象谷歌翻译这样的免费翻译引擎。
应该不存在这个问题,我对过莎士比亚全集,结果也不错。
我要看看是不是什么地方引进来bug,中间升级了版本。