是有这样的做法,问题是慢啊。算一下,假定每秒获取三个段落的机器翻译(一般服务器都会限流每秒两次访问,百度翻译限流每秒三次访问好像),1000段对需时5.5分钟。5000段就需要约半小时。
自己架机器翻译引擎的话没GPU配置每秒一段算快的了。对齐1000段就需约20分钟,可能有这个耐心的人不多吧。
是有这样的做法,问题是慢啊。算一下,假定每秒获取三个段落的机器翻译(一般服务器都会限流每秒两次访问,百度翻译限流每秒三次访问好像),1000段对需时5.5分钟。5000段就需要约半小时。
自己架机器翻译引擎的话没GPU配置每秒一段算快的了。对齐1000段就需约20分钟,可能有这个耐心的人不多吧。
涨知识了,谢谢科普!
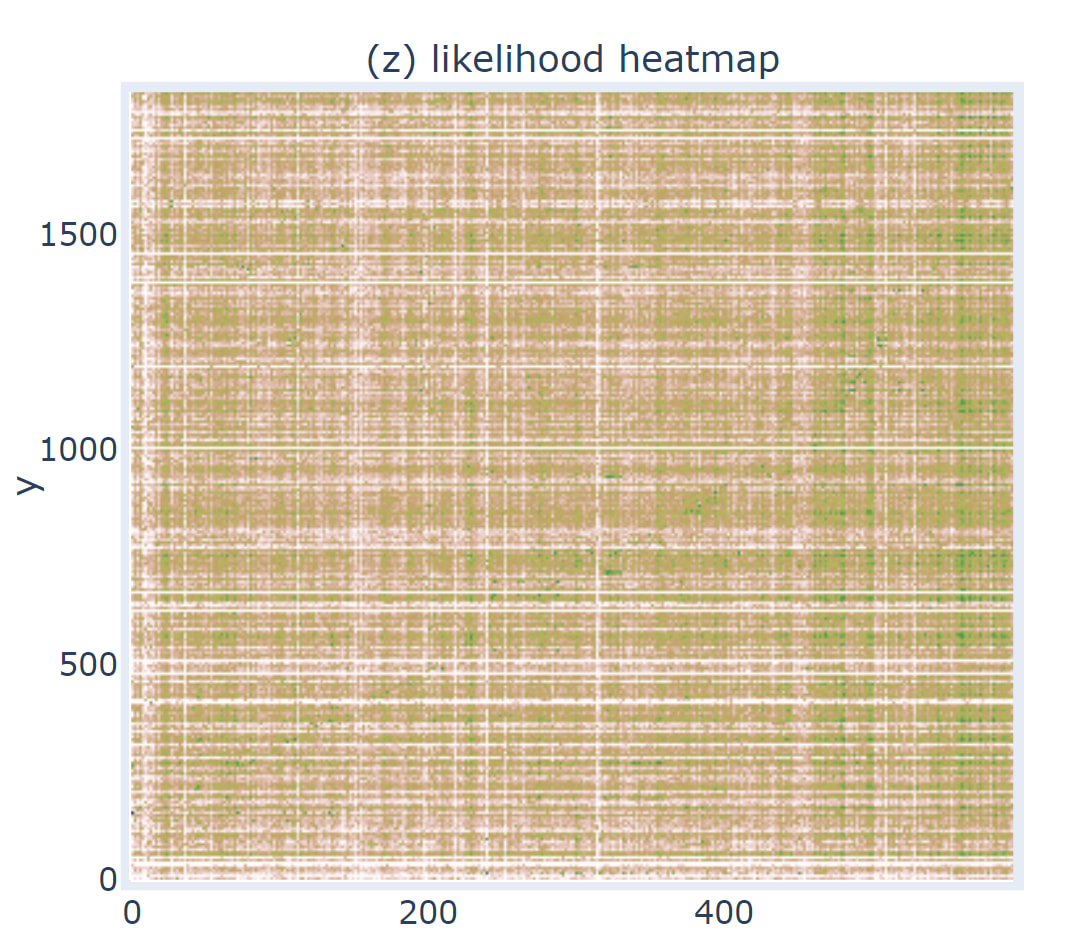
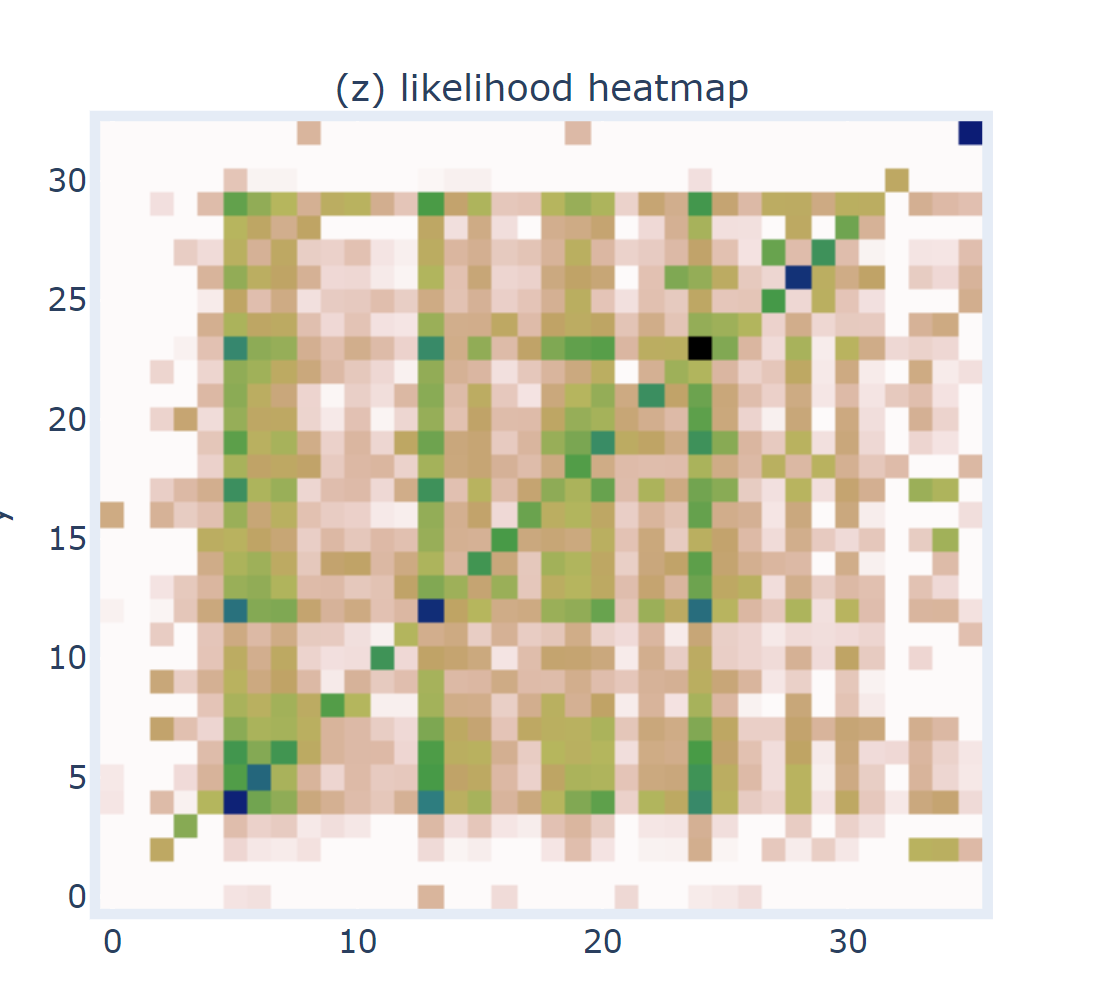
图1、图2是ezbee根据某个规则算出来段段相似度热图。
有些太 freestyle 的翻译 ezbee 有时也无能为力。例如图1(射雕英雄1-4章,横轴中文,纵轴英文)的相似度热图。肉眼也很难看出来哪一段对哪一段。只是隐隐约约从左下角到右上角有一条很发散的绿线。这时候ezbee就无能为力了。或许mlbee(网络版 http://forindo.net:8501/ )能对齐其中的某些段落。
但图2(呼啸山庄ch1,横轴中文,纵轴英文)就很明显可以看到哪些段对应哪些段。例如x:12-y:13那个深绿色的点表示中文第12段对应英文的第13段。
对齐其实就是找到从左下到右上这条对齐轨迹。
附上四个文件,有兴趣的网友可以试试各种对齐工具。
另外也附上ezbee算出来的两个交互热图。解压后在浏览器里打开,鼠标放到图上会显示坐标和相似度值(0…1)。可放大:左键选择区域,回车确认。重载复原。
test-en.txt (5.2 KB)
test-zh.txt (4.9 KB)
射雕英雄传ch1-4-en.txt (339.9 KB)
射雕英雄传ch1-4-zh.txt (197.2 KB)
呼啸山庄ch1热图 test-heatmap.7z (12.3 KB)
射雕英雄传ch1-4热图 FreeMdict Cloud
那么降低机器翻译的粒度呢,一般小说都有章节,首先根据章节定位,然后再在同一章里选取两三段采用机器翻译,以提高对齐的准确性。我不懂技术,只是瞎扯一下 ![]()
他自己说的超越ABBYY Aligner,又不是我替他说的,我只是客观比较。再说他之前的版本我也试用过对齐的结果大量串行。经过这么久的更新还是大量结果串行。他发出这个软件也是让大家测试找bug,如果连这点客观的评述都听不进去,那我真无话可说了。你自己认真看看我的那截图里有几句是准确对齐的,你看完了再回复。那还只是一个流浪地球的对齐效果。
不清楚你为什么用那个软件进行打包,完全可以弄个免安装的,使用者愿意放什么地方都可以,占用内存多是不是因为你把软件处理处理的暂时数据都放内存了?完全可以软件把临时数据在硬盘上建一个临时文件。这样结果可能处理时间更长,但是应该会更稳定。很多大型软件是采用这种思路,Adobe Audition处理大量音频数据的时候就是建立临时文件在硬盘上,处理完毕之后自动删除。EmEditor不是这么干,EmEditor是放内存里,所以在批处理里用正则表达式提取上千个单词的完全解释数据占大量内存。但是EmEditor算是比较稳定的,不过有时候会出问题。
软件就应该加入暂停,人工介入调整,就算是单纯按照章节对齐,也很难做到非常准确。比如:Chapter 1, 规矩的中文翻译成第一章,还有人直接翻译成1,还有人采用罗马数字,软件怎么会知道这些只翻译数字的是章节号?或者把软件里本身加入这种用户多选定义,这些定义里包含所有可能翻译章节的方式,让用户先选择章节的格式,这样定义好了之后软件起码可以把各章准确分出来。章节之间就是段落,软件检测一下中英文段落数量是不是一样。段落对齐之后再可以根据词典文件进行句子层面的对齐,句子层面的对齐会出现分译和并译,句子层面的对齐可以加入分译和并译让用户介入选择,如果是软件自动选择那就采用小分句作为对齐的基础点,而不是严守完整的句子。
我也没说您不能发牢骚。但其实我也不欠您什么东西。您爱用不用。您那么多想法自己实现试试吧。
Mu大侠在一年多的时间内能在对齐方面凭着一腔热血和一己之力取得如此斐然的成绩确实难能可贵。
看看大公司的那些专业团队,如SDL Trados的对齐和双语提取三人项目组,他们近15年在充足的项目资金支持下达到了一个什么技术水平?
俄罗斯软件巨头Abbyy为什么要放弃abbyy Aligner?除了不盈利和内部业务重组定位之外,当然也有技术的突破方面的困境。
当然个人在这方面做的好的也大有人在,如雪人软件的作者,最新版本的对齐效果也是让人惊叹不已的,但是使用是受限的。
最后说一点,我们对他人的工作,都应该表示尊敬,要秉持一个客观的态度。因为每个人因为性格不同,说话方式也会大为不同,我们要相互谅解,彼此包容,千万不要求全责备!
mlbee (http://forindo.net:8501/ )段段对齐射雕英雄传ch1-4:射雕英雄传ch1-4-en.txt–aligned_paras.xlsx (325.0 KB)
个人认为相当不错。mlbee最终会被整合到 ptextpad 里
不妨将 射雕英雄传ch1-4 送给Abbyy Aligner对一下试试。
mlbee 网络版目前仅接受 utf8 txt 格式。附上 射雕英雄传ch1-4 中文文本的 utf8 格式。前面那个文件是 gb2312 格式。
射雕英雄传ch1-4-zh-utf8.txt (292.4 KB)
射雕英雄传ch1-4-en.txt (339.9 KB)
没错,别人爱用不用。当然你也不欠别人什么。还是客观的说,你做这个软件是希望软件写出来好用,起码从你自己角度希望软件对你有用,也没准我猜错了。至于你写软件怎么写是你的自由,别人说啥好像都是多余。不喜欢别人说一些实际问题,别人自然可以闭嘴。
你这叫客观评述吗?即使说的是事实,也不一定叫客观,因为掺入有主观情绪。
作者希望听到的是积极的反馈,不是你这种指手画脚,你以为你是谁?
如果真心想反馈和建议,先向其他人学学怎么说话。要不,就去一边凉快去,作者写软件不是给你这种不懂得尊重别人的人用的。
你没主观情绪!你高人,你不食人间烟火!Sorry. 你看过我截图的测试结果吗?除了开头那句对齐是对的,下面对齐全错了。那我就请教一下你这高人我改怎么评价这个软件?是说这个软件天下无敌?我估计我这样说你就会说我是讽刺了。你告诉我怎么评价??????
看来你确实是想反馈,只是不会说话。你愿意学了就看看别人怎么提建议提意见吧,不愿意学,作者不欢迎你,你可以洗洗睡了。
你还是不知道怎么回答我那个如何评价的问题,你还是在回避我的那个问题,因为那不好说。连你自己都知道怎么说。我可能犯贱的是把ABBYY Aligner拿出来做对比了。我只为那一句话向软件作者和有些人道歉。如果你们还认为我的其它的话还有问题,那就不是我的问题。
反饋可以,千萬不要把自己變成項目經理,居高臨下、盛氣凌人地告訴開發者要如何打包、如何設計軟件。
既然要反饋,最好把你的中英文本上傳一下。
支持作者探索新工具~
可能真的是错怪你了,你可能只是习惯了这样说话。请你比较一下:
建议能够选择安装路径,有人不喜欢把软件装在C盘
我试了一下,效果很不理想,请看看怎么回事
请问为什么不弄个离线版呢?
内容虽没大差,但态度、语气不同。语气不善,一两句话没人计较,如果接二连三就会让人不舒服。
有的人一开口就像谁都欠他似的。情商堪忧还自诩冷静客观!
我一直期待作者在完成文本对齐之后,开始折腾术语提取。目前语帆术语宝术语提取效果不错,但是各种字数限制让人无语。