大佬大佬大佬
dict9k词表更新至airline(1712个).txt (231.1 KB)
有发现bug, 多个连字符的词没法标注。
air-to-air air-to-ground air-to-surface air-to-underwater
超过一个连字符的就没法标
好的,已更新正则表达式;
稍后同步至GitHub;
原
var reWord = /([a-zA-Z]+)+-([a-zA-Z]+)|([a-zA-Z][a-zA-Z']+)/g;
可在 worker.js 中自行替换为
var reWord = /(([a-zA-Z]+)+-*)+|([a-zA-Z]+)/g;
效果如图:

1 个赞
关于词组识别问题的讨论
一、词组分类
- 介词短语
- 短语动词(时态、单复数)
- 名词短语(单复数)
- 固定搭配 (?可能包含1、2、3、5、6)
- 习语
- 其他
二、识别方法:使用正则表达式,根据词典文件词条 一 一匹配;
问题: 时态、单复数变化;
方案一:
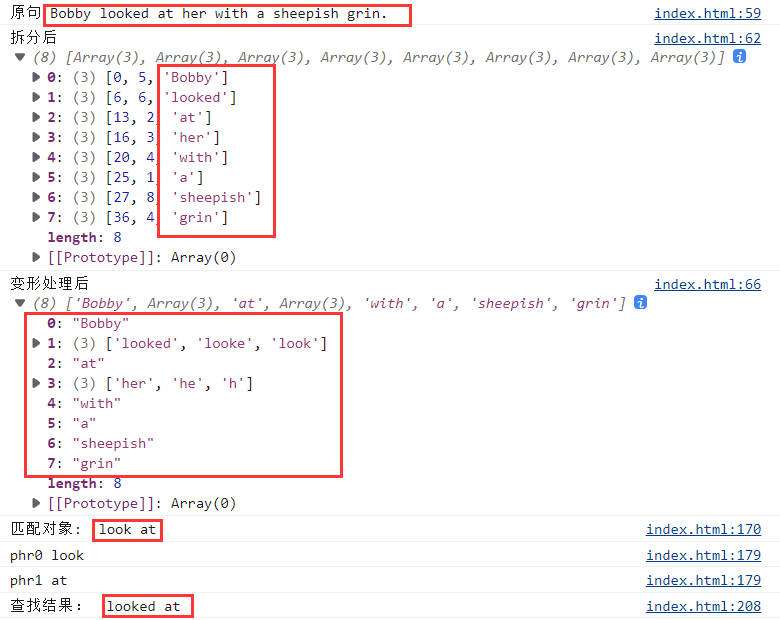
例:Bobby looked at her with a sheepish grin.博比望着她腼腆地咧嘴一笑。
1、按空格拆成数组 [“Bobby”, “looked”, “at” ,“her”, “with”, “a” ,“sheepish”, “grin”]
2、按规则还原原形,合并为新数组
如果length>1,push();
如果length=1,concat();
得[“Bobby”,[“looked”,“look”], “at” ,“her”, “with”, “a” ,“sheepish”, “grin”]

3、按照词典词条匹配,找出 look at
将词条look at拆成
["look", "at"]
先找look,找到后判断后一个元素是不是at
缺点:如果词条数量比较多,就比较花时间;
4、给原文中 looked at 添加标签
【方案一】效果:
连在一起的多个词或者词组或者叫短语或者谚语什么的,只要没有词性变化的,识别难度应该没多高吧。
英语词组统计软件.rar (859.1 KB)
这个软件里面的注册机使用在win10系统的时候容易造成蓝屏,试过多次每次都会造成蓝屏,需要用手机拍下视频才能记录下注册机找出的注册码。
dict9k更新词表2008个至alkyl.txt (266.0 KB)
征集些,比较好的词组(错误少、内容丰富),带释义的;我也会在论坛找找看;
可包含:
- 介词短语
- 短语动词
- 名词短语
- 固定搭配
- 习语
- 其他
结果汇总:
1 个赞
多词结构.txt (6.8 MB)
英汉大词典里提取的多词结构,这个是这词典里的绝大多数的多词结构
内容是很丰富,不过有太多杂乱的内容了;
需要剔除一部分;
需要修正一部分;
需要拆分一部分;
这个工作量太大;我再找找
不过处理好了,将会是非常不错的;
牛津短语动词、牛津习语 这两本基本就行了
1 个赞

越来越好了
词组要兼顾权威和广度的话,可考虑新世纪英汉已提取的词组。另外其释义中都有大量的固定词组搭配也很不错(估计这个就比较难提取了)。
【功能建议】建议增强对于html的支持
我们都知道epub把后缀名改成zip,解压缩后得到一堆html,是可以直接用浏览器打开,连样式都保留得很好的。我刚试了一下用MCP打开这样的html,发现基本上能看,但有些小问题。对于某些标签的解释出现了问题。
比如

有问题部分的html代码

究其原因,就是虽然对于
的解释基本正确,但是带了个class="indent"就出问题了。①建议对此进行增强,这样可玩性大幅提高。
②如果还能够进一步支持里面的css(一般来说,epub的css不会太复杂),就基本上是近乎完美的epub阅读器了,完全可以看小说。
③如果进一步能直接打开epub且保持目录结构,则完美。
看起来似乎①不至于太麻烦,不知道能否考虑一下实现。
主要是我采用了相对偷懒的方式来实现功能,所以目前直接用来解析html是会出现些问题的;
想法很好,如果要做的话基本上得从头写了,用上Vue,结构得大改;
做完词组后,暂时不想再改动了;
可以期望一下以后了(有生之年);
简单修改一下呢?比如对html进行预处理,只保留p(段落)、strong(加粗)、em(斜体)标签,干掉其他所有,小说的话其实主要就用到这3个。

只保留p、strong、em标签;
/<(?!((\s?p)|(\s?strong)|(\s?em)))(\n)?[^>]+>/g
还有,有些斜体是通过class标注的;需要css文件;这些不予保留;
class="italic"
.italic{
font-style: italic;
}
干掉所有
/<.(\n)?[^>]+>/g
匹配class
/class\s*?=\s*?(["])[\s\S]*?\1/g
匹配id
/id\s*?=\s*?(["])[\s\S]*?\1/g
你可以测试一下:正则表达式在线测试 | 菜鸟工具
《三体》英文版的某一节:index_split_009.zip (12.7 KB)

滚动条的滑动块过小的解决方法,附带html处理后的效果
识别短语那功能是不是还没更新?蓝奏云和github文件都是以前的
是的,
总觉添加词组后得使页面更乱了;
词组词典文件还在处理;