你可以先把主要文件发出来,词组词典的文件格式如果没变,可以让使用者先自己做个词组的放里面用着,也可以顺便看看有什么需要调的地方
还发现可能是一个bug,这个index页面有时候上面按钮会失去响应,这里说明一下电脑资源应该够用,Intel(R) Core™ i7-4800MQ CPU @ 2.70GHz 16G内存,感觉应该与这网页和js处理信息的方式有关吧
在什么情况下会失去响应?
除过正在处理文本、标注之类的
失去相应的时候不一定是什么时候,没有什么规律,至少到现在没发现什么规律,有时候可能是上次标注正常,下次就没反应了,有时候可能直接打开就没反应。Edge浏览器开5个页面不进行任何操作,内存占用780-850M正常吗?
词组识别 目前存在问题:
【问题一】
【例:step forward】
【例:“Professor Wang, please don’t misunderstand.” One of the army officers, a major, stepped forward. 】
-
词组判断出来的结果:【正确】

-
生词判断的结果:【错误】

【原因:词形还原:[stepped, steppe, stepp, step],记录了 steppe,而不是 step】
【steppe: (尤指东南欧及西伯利亚树少的)大草原,干草原】 -
过滤:【程序没有根据用step forward 把 steppe去除】

-
最终在页面上 呈现如下混乱的场面
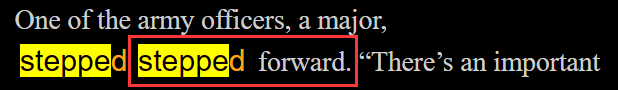
-
解决办法:根据索引【2956】,去除重复的数据;
【已解决】
【问题二】
【例:run out | out of】
【例:They had run out of table space and put a few workstations directly on the floor, where power cords and networking wires formed a tangled mess.】
-
找到两个词组

-
结果:
-
解决办法:词典文件干掉【out of】
以上问题的解决方法可总结为:【5095+7-5099>0】则删除索引为【5099】这一项;
steppe这个问题的出现是与收入的词有关,有些太偏的词就没必要收录。这种问题只有在大量使用的过程中才能发现。解决方案也不是没有,就是太麻烦了,比如引入语料库的词性赋码,不过这样的问题是要写大量的代码。CLAWS赋码在语料库方面已经使用很多年了,而且很成熟了,不过如果要这样就要写很多代码。
还有种解决方案,把动词的各种词形变化做成一个小文件,让代码根据这些数据去判断
不妨开着控制台,可以查看conlose.log信息;
1 个赞
不知道在哪次更新后,出现了以下问题:
- 左键单击后,没有赋予红色状态框;
- 方向键切换下一个时,页面没有跟随滚动;
没事了,html文件内的标签导致的;
【已处理】
【11.9】
【词组识别】功能已更新至GitHub;【蓝奏云】一同更新;
注意:
- 选择【2w+词组】,点击【Click To Start】,即可【进行词组识别】
- 【词组识别】会比【仅标注生词】费时间,因此页面卡顿时间会稍长,可F12打开【控制台】查看进度;
- 目前词组的词典文件有14542词条;均为两个单词的词组;
- 无法识别包含【sb、sb’s、sth等】代词的词组;亦或是含【标点符号、汉字】等;
【词组长度测试】
【例:in accordance with】【3】
【例:on a wing and a prayer】【6】
原文:
in accordance with legal requirements 根据法律要求
on a wing and a prayer
查询结果:

标注后:
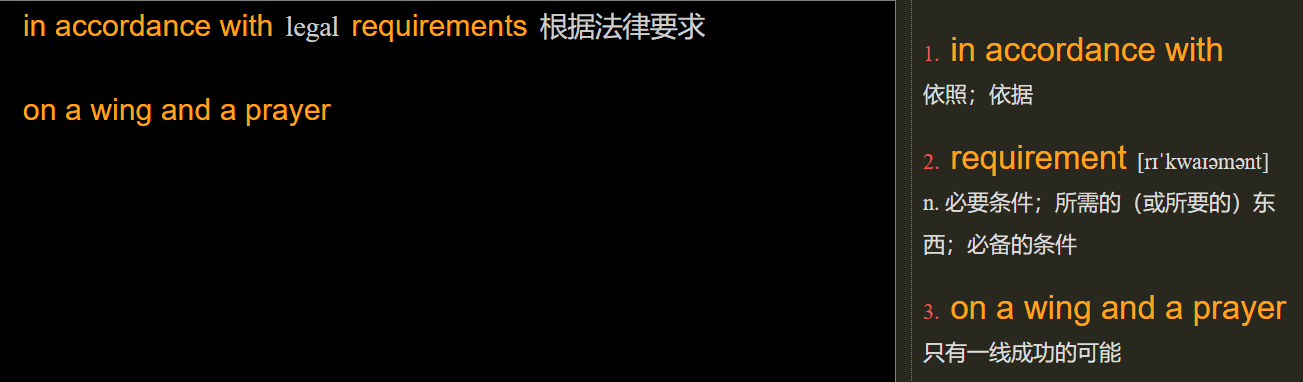
暂时不支持含人称代词、标点符号、中文的词组;
问看了看词组的那个文件,好像都是两个词的,如果把多于两个词的加入那个文件,是否能识别?词组解释的大括号里面的那个分号是不是必须有?
只要文中的词组和词典文件里的是连着的【例:in accordance with】,理论上没有长度限制【不过会受标点符号影响,待优化】;
双引号里面的都是字符串,可随意改动,无影响;
关于词组和单词一并处理可能会出现问题的一个解决方案:可以设置一个标注单词和标注词组的切换按钮,切换到标注单词的时候只标单词的,切换到标注词组的时候只标词组的。这样分开处理就不会出现那种问题了,而且还解决了加载速度的问题,
考虑过,但当时由于没想好怎么在标注词组时处理生词的标签,现在可以通过正则来解决标签引起的索引问题;
以后再更新;
现在再优化一下查询词组的代码;
目前加载文章后默认是只标注生词,然后自己从【English level】中选择是否标注【词组】;
加载文章速度,无法通过拆分标注【生词】【词组】的步骤解决;
耗时的仅是【词组识别的过程】
【例:】

- 如何在【accordance】存在span标签的情况下,给 【in accordance with】添加标签;
/in.*accordance.*with/g貌似 单独标注词组意义不大;
- 不过,上述方法可用于处理含人称代词、标点符号(不包含括号)的词组【主要是习语吧,还比较长】
【例:beat sb off】
She used her handbag to beat the attacker off. 她用手提包将袭击者打跑。
/beat.*off/g
【例:morning, noon, and night】
It’s been raining morning, noon, and night since we arrived. 从我们到达后天从早到晚下雨。
/morning.*noon.*and.*night/g
但是,该方式存在问题:
【不规则动词】暂时无法处理
【例:blow sb away】
She just totally blew me away with her singing. 她的歌声让我完全陶醉其中。
【添加】:快捷键【Ctrl+X】,用于 隐藏/显示【Click To Start】那一行按钮;【![]() Nav -】时生效;
Nav -】时生效;
离谱
问题一:
文中没有【take kindly to】
Forty-plus years later Wang Miao thought the four people who came to find him made a rather odd combination


怎么根据【take kindly to】匹配到文中的【to】,还记录了【索引】和【长度】?????
更离谱。。。

错误的根源在这里:
![]()
正常逻辑是 to !== take,应该继续 find !== take、him !== take…
不应该记录【to】的;
【出现错误的原因未知】
解决:length为1的不予记录;
问题二:

存在大量重复内容;
检查后发现,把文中出现的相同的词组都记录在一起了;
解决:当一个词组识别完成后,及时清理缓存;之后一并去除重复数据

删除重复数据:

dict9k词汇更新至2340个(alvar)
dict9k词汇更新至2340个(alvar).txt (308.8 KB)
这个Milkway-Cloze改名为无障碍读原著可能更符合它的功能,估计大多数人用这个来当查生词的。
1 个赞
本来就写了蒙哥阅读器了。