关于词组识别问题的讨论
一、词组分类
- 介词短语
- 短语动词(时态、单复数)
- 名词短语(单复数)
- 固定搭配 (?可能包含1、2、3、5、6)
- 习语
- 其他
二、识别方法:使用正则表达式,根据词典文件词条 一 一匹配;
问题: 时态、单复数变化;
方案一:
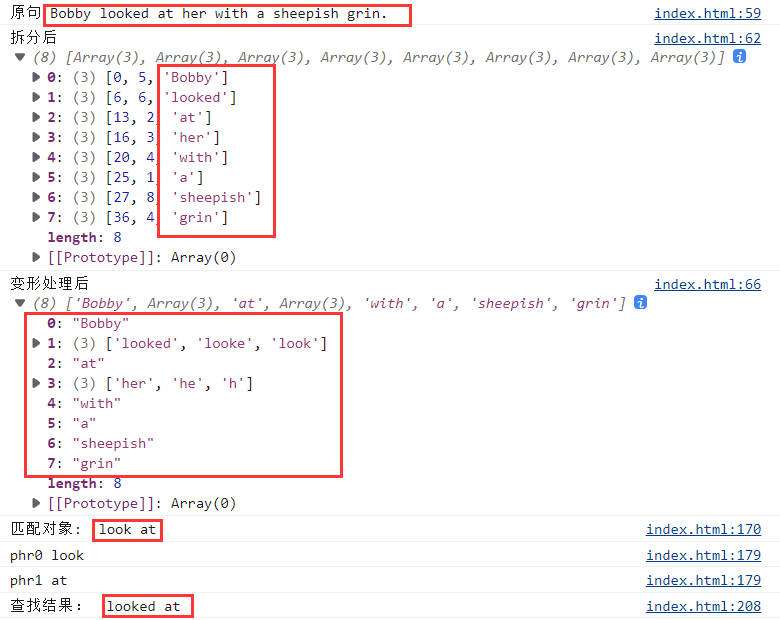
例:Bobby looked at her with a sheepish grin.博比望着她腼腆地咧嘴一笑。
1、按空格拆成数组 [“Bobby”, “looked”, “at” ,“her”, “with”, “a” ,“sheepish”, “grin”]
2、按规则还原原形,合并为新数组

如果length>1,push();
如果length=1,concat();
得 [“Bobby”,[“looked”,“look”], “at” ,“her”, “with”, “a” ,“sheepish”, “grin”]
3、按照词典词条匹配,找出 look at
将词条look at拆成["look", "at"]
先找look,找到后判断后一个元素是不是at
缺点:如果词条数量比较多,就比较花时间;
4、给原文中 looked at 添加标签
【方案一】效果:
M303
2
英汉大词典里标了中文意思的单词也就在9万多,词组搭配和成语习语加上谚语加起来应该到不了4万(应该在两三万的数量) 。 英汉大词典里的所有前缀后缀加起来在1500个左右,前阵子删除的时候只是看了个大致数字,没记准确数字是多少。这词典还有个问题就是人名太多,甚至连演员都收录进去。简直就是部野史,可以用来查有些人的祖宗十八代。这词典还收录很多别的语种的词汇,就是字母上面带标音符号的那种,严重怀疑当初作者找不到词汇了用这些词汇来拼凑。在用这词典做词表整理里面数据才发现这词典真像那啥飞机的发动机似的只能靠进口,里面的例句与日本人编写的词典真是有差距,而且差距不小,之前从日本人写的词典里搜过例句发现里面的长句子真多,很多是从美国的各种报刊啥摘录的。
可能是法语词汇或者其他语言的词汇,英语吸收了不少;
M303
5
没贴串,只是顺带说了一些数据问题而已。他说“如果词条数量多,就比较花时间”,我只是把这些客观数据说了说。
因为英汉大词典不是学习型词典啊,看名字就知道是“大词典”,是以广博为目标的(当然,作为大词典收词量其实是不足的)。至于例句,收录长句、原句是一种风格(大多数词典是这个风格),收录短句、词组当例子也是一种风格,各有受众,我觉得没啥高低之分。