明白你的意思,但是在词典里不合适;
建议:
1、初次进入完形填空模式,光标输入焦点自动停在第一空位上(目前要鼠标点击,或按<,、.>键左右移动后才能进行输入);
2、按<,、.>键移位,或Enter键移到下一填空处时,不要做输入正误判断(目前模式,没有一个空能填对)。
mdx-server 可以通过 http 请求获取词的页面。wikit 也可以,介绍的第一段就说了。
前者可以直接使用,就是实现得比较简陋,但改也挺方便的。后者是比较完整的实现,但mdx 格式的词典可能必须转成它的格式才可以用,了解不多,只是以前简单试用过。
有道理,我改改;
正误判断还是要有的,把错误提示取消就行了;
发一个添加的词表,词表里的单词音标以及解释都是取自陆谷孙主编的英汉大词典,弄了1017个单词了,dict9k.js里面的dict9k[“adumbrate”] 这个词之前的词都处理完了,没添加大写的单词。把英汉大词典里的缩略的那些词全去掉发现英汉大词典没有标称的那么多词,估计删干净之后也就有十万的孤立的词也就不错了。
dict9k添加修改词.rar (47.3 KB)
这个添加修改词可以复制进那个js文件,这里面的解释就是非常多。
顺便也把那个没处理完的英汉大词典的文件发上来,有兴趣删里面标签的可以继续处理,里面的数量是11万多,例子都删了,大写的缩略全处理掉了,开头大写的词也都去掉了,短语的全去掉了,这11万多不能直接复制到js文件里用,需要手动删改。用getdict软件解mdx词典文件不知道为何汉语解释里没序号。不过前面有标记符号。
英汉删除全大写的词.rar (5.4 MB)
2 个赞
多谢推荐工具;
多谢分享;
不过,个人觉得没必要搞太多的词放进词典文件里(不要在搞工具上花太多时间);
2w差不多就可以了,实在不行就查查词典;
目标数量起码弄七八万词,要么就把这个英汉大词典的独立的小写的那些词都弄完。这样基本就可以无障碍处理几乎任何一本英文原著了。全部弄完估计那个js文件应该十几兆。
我个人目前可能没太多精力处理这个,
如果想补充词汇的话,可以在2w的基础上补充,
这是2w词头;避免重复;2w词头.txt (265.1 KB)
到时候可以拆成多个文件;
先在此致谢了;
解释一下为何从9k词表弄,最初是从2W的那个弄,因为当时出错一直没找出什么问题来,后来找出问题所在了。因为js对格式里的标点符号啥的要求的比较严,少个标点也没法测试成功,最初折腾多天一直不知道怎么回事,后来还出现过原来词表里有那个词只是放在词表的最后部分,造成使用的时候一直标注原来那个含义短的,这个问题郁闷了我多天,后来找出问题所在也知道怎么处理这个词表了。在没找出问题的时候改成修改9k的那个词表了。当然只要js要求的那个格式符合弄哪个词表无所谓,当然弄2W的那个表里要把开头的那改成2w。这词表里的词太多,有些地方不敢一下子用正则表达式全把没多少用处的删掉,因为会造成误伤,上面发出来的那个英汉大词典的是我所敢删的极限了,剩下的内容只能手动修改或删减。
2w那个删改过几次,后来又在末尾补充过一些;
或者可以用同样的格式,做一个新的词典【dict8w】,这样就不怕词头重复了;
那时候我是用excel填充的,单词、音标、释义 中间各空一列,然后把对象格式放进空的位置,双击填充就行了;
问题已处理,代码已推送至GitHub;
蓝奏云内也已更新;
dict9k词表更新 (包括上面发的内容共1244词)
dict9k更新至1244词.txt (168.9 KB)
这样吧,你做的这个词表更新的时候,在帖子里标注上序号,
最后我把这个系列整合成单独一项【dict8w】,放进项目里;
js词表添加修改注意事项:
在js文件夹的dict里添加单词的时候,有些特别需要注意的事项:
1."千万不能弄成中文引号
2."千万不能只使用半边
3.[“这个引号千万别掉了
4.”]这个引号也千万别掉了
5.ipa: "这里的冒号和引号千万别弄成中文的
6., def: "这个逗号冒号引号千万别弄成中文的
7.dict9k,dict7k,dict2w的名称千万别弄错了
8.不该多的空格千万别弄多了
上面的问题只要出现一个就可能查不出单词来。
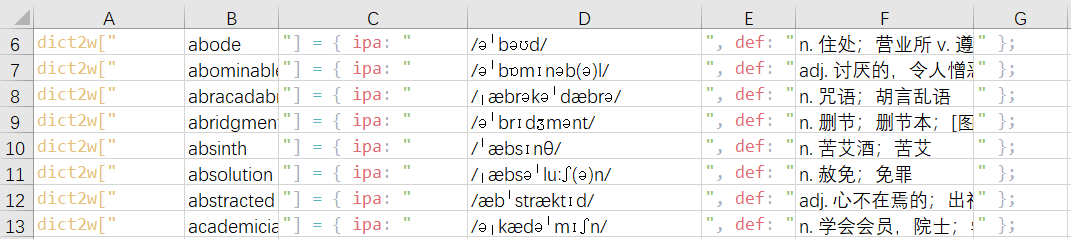
比如:aasvogel /'ɑːsfəʊɡəl/ <鸟>n. 南非兀鹫 这个词要添加到js词表里,如果你添加dict9k里面那就写成:dict9k[“aasvogel”] = { ipa: “/'ɑːsfəʊɡəl/”, def: “<鸟>n. 南非兀鹫”};
如果添加到dict2w里面就写成dict2w[“aasvogel”] = { ipa: “/'ɑːsfəʊɡəl/”, def: “<鸟>n. 南非兀鹫”};
如果你的单词没有音标,那后面的大括号就去掉音标项目,dict9k[“aasvogel”] = { def: “<鸟>n. 南非兀鹫”};
注意这例子里的引号都是英文体系中的引号,不是中文体系的,为什么是英文的引号不是中文的,因为js编程的那些东西都是用纯英文写的,反正不是中国人发明的,所以就用英文体系的引号。这里面最容易出错的就是这引号。
把这注意事项发出来,有想添加单词的可以根据这个添加。如果不知道这些注意事项,添加单词的时候出错可能半天都找不出什么原因来。这里是指那些学过js编程的人。当然我也没学过js编程。
谢谢,更新下蓝奏云盘挺好的,GitHub经常登不上去。
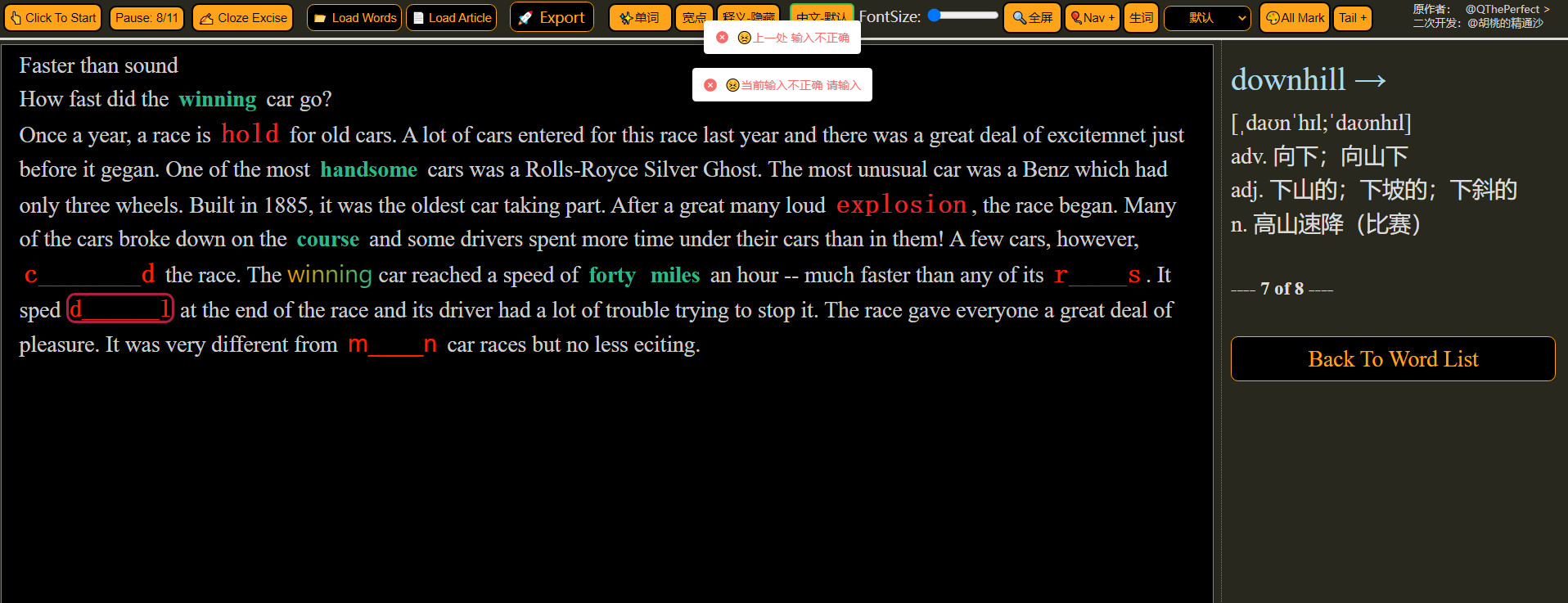
关于正误判断:移动光标后,可对刚失去输入焦点,且有有效输入(至少输入了一个字母)的上一填空判断正误,对刚得到输入焦点的当前填空不必判断正误。
1 个赞
已经去掉了当前位置的错误提示,不影响使用即可;
为了防止误触,只有判断为 填空 和 输入错误 时,才能使键盘输入;(这是针对原作的修改)
所以不能取消;
因为英汉大词典里面的那些数据是用正则表达式处理掉一些标签符号,有些不规矩的地方可能会出错,在excel里批量填充或者在EmEditor里批量替换有可能会出错,一个出错可能造成很多内容串行。因为里面的原始数据毕竟不是一个单词一个音标一个含义这样规规矩矩的。里面还有一个拼写多个不同音的,还有一个含义多种拼写的。如果是没有例句的那种词汇书的最好处理了,直接用扫描仪扫描识别或速录笔扫就行了,单纯音标部分也很好处理,直接用软件批量转出来就行。
今天上午删英汉大词典txt文件里没处理干净的多词结构光是删那些各种学会协会理事会啥的折腾了一上午,是手动删的,不是用批量删除,批量删除会删掉一些有用的内容。删这些内容的过程中发现这个词典真是一部政治词典,几乎啥会都有,还有里面收录了大量死人人名,真有点查人家八辈祖宗都能查到