biu
1
Update 2023-02-13
第一个可日常使用的桌面版本 (Linux/MacOS/Windows) 已经发布, 版本号为 0.0.5,
同时提供了 ECDICT 简明中英文词典文件.
桌面版本软件下载地址: wikit 0.0.5
简明中英文词典下载地址: ecdit-v1.0.28
Update 2022-11-06
-
本项目目前状态
感谢各位朋友对该词典工具的关注, 本项目更新比较缓慢, 原因有很多, 就不一一细说, 不过本项目我从未放弃过, 这是我首先要跟大家说的.
-
使用问题
我看到关于本项目的使用有一些问题, 希望大家可以到项目主页上发起 issue (项目主页上提问题的页面是 https://github.com/ikey4u/wikit/issues), 这样的话我可以直接在 github 上回复相关问题, 在修复的时候可以引用上相关 issue, 而且也能方便后来人查看.
-
实时反馈
为了方便大家交流, 我新建了一个微信群
Update 2021-11-29
目前 wikit 词典格式已经基本设计完毕, 索引算法也已经实现, windows/mac/linux 桌面端 GUI 程序 beta 版本也已经实现, 能够加载本地词典, 也可以从网络 API 实现词典查询( wikit 实现了一个简单的词典 server).
wikit 桌面端 (wikit desktop) 的设计本着简洁的原则, 也就是说能够选择不同词典, 然后进行模糊查词(即单词拼写不正确时, 会提示相关词汇) . 如果你的需求还包括其他的功能, 比如收藏词汇, 导出 anki 等, 那么 wikit desktop 大概率不适合你, 下面对 wikit 词典加载词典方式进行一下简单的说明
-
本地加载词典
wikit 的本地词典可以从 mdx 直接生成, 或者从 mdx 的源码生成.
-
网络加载词典
网络加载词典这个功能特别实用, 如果你有很多词典, 而且词典又很大, 如果你想随时随地的使用词典, 那么从网络加载就是不二的选择. 而且 wikit 的server端可以去加载另外一个 server 端的词典, 也就是词典中继, 你可以中继另外一个人的词典, 这样理论上会得到无数的词典资源共享.
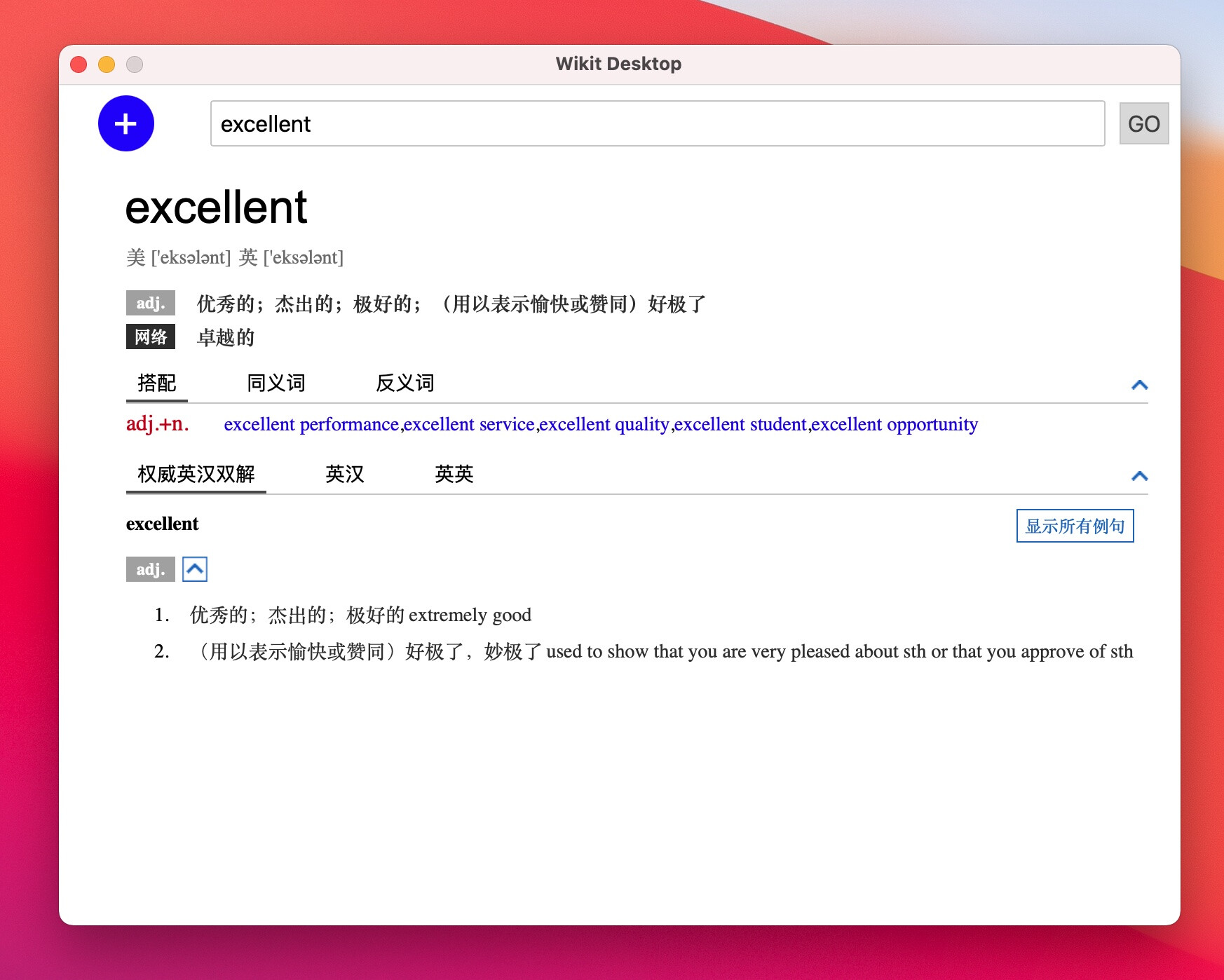
桌面主截图如下所示
如果有问题, 请务必先阅读项目首页那短短一百来行的说明, 如果的确解决不了, 再提问, 感谢理解与支持, 欢迎下载体验: Releases · ikey4u/wikit · GitHub
大家好,目前我正在编写一个mdx和mdd的创建以及解析工具,已经实现了mdx的解析,mdx的生成近期就会完工,此外我根据已有的资料绘制了mdx 1.2和2.0的详细格式,这个项目已经开源,地址为
想看看这里的大佬和mdx用户有什么建议货,如果有人可以参与项目开发就再好不过了,希望有志之士能一起让这个项目发展壮大。
目前 Wikit v0.1.0 CLI 版本以及放出, 下载地址在这里 Release v0.1.0 · ikey4u/wikit · GitHub 欢迎各位朋友使用该工具进行 mdx 的创建和解析, 如果有问题, 到项目主页开一个 issues, 我有空就会着手解决.
40 个赞
biu
5
目前图行界面还不完善,核心功能实现后会去处理图形界面这一部分。
2 个赞
kaser
6
另外,你做了 Wikit-darwin,那做Mac版,用 Cocoa (API),gui用WebView
2 个赞
233,之前在群里看到过,这个工具里使用的ripemd128 hash算法,是我两年前写的,很怀念啊。
7 个赞
mdx/mdd 有个很大问题,就是用了gpl 协议的 lzo 压缩算法,现有实现都没能绕开这个协议,包括 hadoop,他们也遇到过这个版权问题,最后为避免 gpl 协议的污染,是以插件形式提供压缩/解压功能的。社区里有很多词典是用 lzo 这个算法压缩的,围绕这个词典格式,再继续推进,可能需要先解决这个问题。
还有 mdx 词头排序黑盒的问题,社区里讨论很多了,对于英文来说,mdict-utils 之类的工具已经够用了,但官方的 mdxbuilder 在勾选 stripkey 后,到底去掉哪些符号,还是个黑盒,真的只是 python 内置符号表里的那些吗,中文日文符号要不要考虑下。对使用 mdict-utils 打包后的词典排序,欧路和 mdict 有很多表现不一致的地方,疑问很多,所以社区里还是推荐使用官方的 mdxbuilder 打包。
8 个赞
hua
10
整个新格式呀,哎,mdx 不好用 索引太差,现在都不缺存储空间了,
2 个赞
biu
11
现在的界面是用electron搞的,其实就是对web页面简单的封装,结果生成的程序巨大,十分不友好,我是打算用tauri这个来搞个ui,不过tauri目前还不太能打,其他的native层框架一个人搞不过来。
3 个赞
biu
12
@hua @last_idol
不好意思, 这个帐号由于是新帐号, 所以被限制发言了, 昨天到现在得隔 22 个小时才能回复.
- 压缩问题: 这个问题其实很好解决, 我们不压缩就行了,或者要压缩的话, 我们不用 lzo, 使用 zlib 就可以了. 目前我的处理是不压缩, 因为貌似空间占用现在不是一个很大的需要首要考虑的问题.
- mdx 词头排序问题: 我目前不是特别明白词头排序是为了解决什么? 为了解决查询问题吗? 我目前是对所有词头进行了升序排列, 而至于 mdxbuilder 对词头怎么处理的, 我觉得没必要关注.
- 新的词典格式: 由于目前 mdx 的词典资源已经相当多, 但是 mdx 的设计我认为太过于复杂, 所以我这边设计了一种简单的结合 sqlite 的一种词典格式, 稍后我会在项目主页上更新.
- ripemd128: 另外感谢你提供这个算法实现

- 项目进展: 已经实现了 MDX 的创建(2.0)以及解析(1.2 和 2.0), 有网友使用本工具创建的 500M 左右的 MDX 可以在 goldendict 中正常使用.
hua
13
怎样结合?我建议是不要造轮子,统一 schema 就行。
1 个赞
hua
16
索引 (全文也好,词头也好) 是一个重要很重要的考量,如果新格式不能在查询层面给出一些跨越性,历史性的进步的话,很难普及。你提到的提案其实就是将索引做到了 sqlite,确实更清晰了,然而并没有什么吸引我的地方。
设计一个新的格式很难,加油楼主!
另外 RUST 太小众了吧,我只能在精神和建议层面多多支持你们。
另外 项目 README 里面网址对了,字错了。freemdict 这个字真的挺多人打错的,也不知道为啥。
第三方电子书或者词典软件想支持 mdx/mdd,需要支持 lzo 的解压,会涉及到 gpl 协议的污染问题,这会是这个格式推广的阻碍。仅是制作工具,确实不需要考虑。
词头排序是索引里最重要的部份,写入词典里的排序,需要和词典软件电子书的预期排序一致,后者才能正常读取词典里的词头索引。GoldenDict 是自建索引,所以不在乎词典里的排序,但欧路和 MDict 是依赖的。
Mdxbuilder 里的 stripkey 和忽略大小写这两个选项,会影响词头排序,但能够很好的提高查询体验,英语世界里有大量连字符。
总结来说,第三方制作 mdx 词典的工具,生成的词头排序,需要和官方工具保持一致,才能在欧路和 MDict 上保证最佳的查询体验。
5 个赞
biu
18
谢谢指出错误, 对于新格式有什么自己的想法, 可以提出来, 集思广益.
biu
19
我想说明一点, 之所以写一个开源软件, 不是为了去支持闭源的(商业或非商业)软件, 因为这是费力不讨好, 目前为了支持 MDX 的创建和解析, 唯一的理由就是因为 MDX 目前资源比较多.
至于 mdict 和欧陆, 他们只是一个解析软件, 能够查询, 后续如果有更多的人参与进来, 我们大可自己写 android, ios 以及 pc 客户端. 目前在我看来重写 pc 客户端(win, linux, mac) 上是没有什么大问题的(主要是精力为题), 移动端可能要费点事情.
5 个赞
支持楼主,不被个别商业软件给绑架了才能更加free更加健康的发展下去的。
下文可能有个别语法或什么的错误,不知道分析的对不对:
另外 freedict 好像不是指向 https://freedict.org/ 的,应该改成 hua 大建议的吧
1 个赞
biu
21
感谢感谢, 英文写的还不利索, 晚上回去修改一下 typo
1 个赞