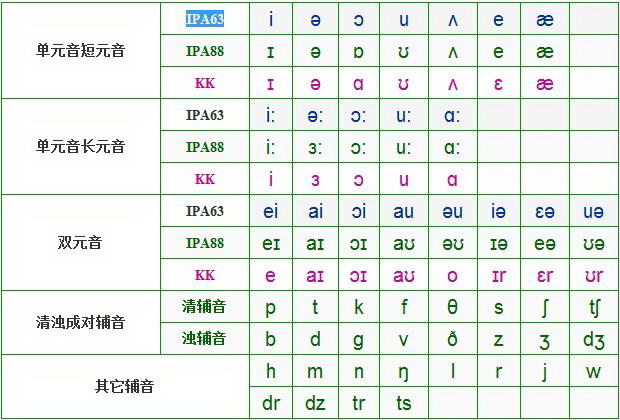
修正牛高4的金山音标字体,我原来用的script是:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
OALD4原始文档音标使用了"Kingsoft Phonetic Plain"字体,
导致不安装该字体的电脑会出现乱码,在此批量替换修正。
金山词霸音标字体编码表可参见 http://www.fmddlmyy.cn/text66.html
"""
import re
def converter(match):
phonetic_string = match.group()
correct_symbol = phonetic_string.replace('5', 'ˈ')\
.replace('7', 'ˌ').replace('9', 'ˌ')\
.replace('A', 'æ').replace('B', 'ɑ')\
.replace('C', 'ɔ').replace('E', 'ə')\
.replace('F', 'ʃ').replace('I', 'ɪ')\
.replace('J', 'ʊ').replace('N', 'ŋ')\
.replace('Q', 'ʌ').replace('R', 'ɔ')\
.replace('T', 'ð').replace('U', 'u')\
.replace('V', 'ʒ').replace('W', 'θ')\
.replace('Z', 'ɛ').replace('\\', 'ɜ')\
.replace('^', 'ɡ').replace(':', 'ː')\
.replace('[', 'ɜːr').replace('L', 'ər')\
.replace('?@', 'US').replace('`', 'ˈ')
return correct_symbol
def main():
file_src = r'C:\Users\xxx\Desktop\oald.txt'
file_dst = r'C:\Users\xxx\Desktop\oald-2.txt'
with open(file_src, 'r', encoding='UTF-8') as f:
text = f.read()
p = re.compile('/.*?; .*?/ ') # 建议先用“/ .{1,60}?; .{1,40}?/ ”等,分步修改
result = re.sub(p, converter, text)
with open(file_dst, 'w', encoding='UTF-8') as fout:
fout.write(result)
if __name__ == '__main__':
main()
现在看来这个映射表用于牛高4有问题,把 “C” 和 “R”都转成了 “ɔ”,“J” 和 “U” 的转换搞反了,“[” 转成 “ɜːr”、“L” 转成 “ər” 也不规范,不是KK音标使用的字符,应该分别为 “ɝ” 和 “ɚ” 。修改后的转换函数应为:
def converter(match):
phonetic_string = match.group()
correct_symbol = phonetic_string.replace('5', 'ˈ')\
.replace('7', 'ˌ').replace('9', 'ˌ')\
.replace('A', 'æ').replace('B', 'ɑ')\
.replace('C', 'ɒ').replace('E', 'ə')\
.replace('F', 'ʃ').replace('I', 'ɪ')\
.replace('J', 'u').replace('N', 'ŋ')\
.replace('Q', 'ʌ').replace('R', 'ɔ')\
.replace('T', 'ð').replace('U', 'ʊ')\
.replace('V', 'ʒ').replace('W', 'θ')\
.replace('Z', 'ɛ').replace('\\', 'ɜ')\
.replace('^', 'ɡ').replace(':', 'ː')\
.replace('[', 'ɝ').replace('L', 'ɚ')\
.replace('?@', 'US').replace('`', 'ˈ')
return correct_symbol
但这个修正后的script是无法直接用于修复OX-7中已有的失误的,用简单替换的方法也不行,因为音标字符再映射回去存在一对多的关系。
我想出来的解决办法是重新生成一份正确的音标字典(dict),然后对OX-7中单词的音标查表替换,音标字典的原始形式略如下所示:
★zero | /ˈzɪərəʊ; ˈzɪro/
★zest | /zest; zɛst/
★zestful | /-fʊl; -fəl/
★zestfully | /-fʊlɪ; -fəlɪ/
★zigzag | /ˈzɪgzæg; ˈzɪɡzæɡ/
★zillion | /ˈzɪlɪən; ˈzɪljən/
★zinc | /zɪŋk; zɪŋk/
★zing | /zɪŋ; zɪŋ/
★Zion | /ˈzaɪən; ˈzaɪən/
★Zionism | /ˈzaɪənɪzəm; ˈzaɪənˌɪzəm/
★Zionist | /ˈzaɪənɪst; ˈzaɪənɪst/
★zip | /zɪp; zɪp/
★Zip code | /ˈzɪp kəʊd; ˈzɪpˌkod/
★zircon | /ˈzɜːkɒn; ˈzɝˌkɑn/
★zither | /ˈzɪðə(r); ˈzɪðɚ/
★zodiac | /ˈzəʊdɪæk; ˈzodɪˌæk/
★zodiacal | /zəʊˈdaɪəkl; zoˈdaɪəkl/
★zombie | /ˈzɒmbɪ; ˈzɑmbɪ/
★zone | /zəʊn; zon/
★zonal | /ˈzəʊnl; ˈzonl/
★zonked | /zɒŋkt; zɑŋkt/
★zoo | /zuː; zu/
★zoology | /zəʊˈɒlədʒɪ; zoˈɑlədʒɪ/
★zoological | /ˌzəʊəˈlɒdʒɪkl; ˌzoəˈlɑdʒɪkl/
★zoologically | /-klɪ; -klɪ/
★zoologist | /zəʊˈɒlədʒɪst; zoˈɑlədʒɪst/
★zoom | /zuːm; zum/
★zoophyte | /ˈzəʊəfaɪt; ˈzoəˌfaɪt/
★zucchini | /zʊˈkiːnɪ; zuˈkinɪ/
★Zulu | /ˈzuːluː; ˈzulu/
查表替换则用如下代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import re
def converter(match):
ph_dict ={}
file_erratum = r'C:\Users\xxx\Desktop\ph.txt'
with open(file_erratum, 'r', encoding='UTF-8') as fe:
text_list = fe.readlines()
for row in text_list:
ph_dict[row.split('|')[0]] = row.split('|')[1]
headword = match.group(1)
phonetic = match.group(2)
if headword in ph_dict:
correct_symbol = headword + '\n' + ph_dict[headword].strip() + ' '
print(correct_symbol)
else:
correct_symbol = match.group()
return correct_symbol
def main():
file_src = r'C:\Users\xxx\Desktop\OX-7.txt'
file_dst = r'C:\Users\xxx\Desktop\OX-8.txt'
with open(file_src, 'r', encoding='UTF-8') as f:
text = f.read()
p = re.compile('(★.*?)\n(/.{1,60}?; .{1,40}?/ )')
result = re.sub(p, converter, text)
with open(file_dst, 'w', encoding='UTF-8') as fo:
fo.write(result)
if __name__ == '__main__':
main()
程序本身workable,修正了绝大多数不规范的音标,是否高效再说了。现在的问题是,如何评估这种批量修改造成的潜在误伤?针对这种没有形式化规范过的纯文本数据,正则/程序批量修改我一直是比较忌讳的,尽量少用,但数据量较大,手工一个个修正也不太现实,看来只能折中选择。
用正则“/.{1,60}?; .{1,40}?/”搜索OX-7,返回29177个结果,用“/.{1,60}?; .{1,40}?/ ”(最后加了空格),返回27394个结果,用“^/.{1,60}?; .{1,40}?/ ” (指定以“/”开头),返回26935个结果。说明了牛高4中大概有28000左右个音标,上列“查表替换”script选择最严格的正则表达式,只会修改26935个音标,剩余的1000、2000个音标,只能人工查核纠正了。