感谢分享, tsiank 有点眼熟。
给的是个双解版修改的mdx 么(好像是![]()
感谢分享, tsiank 有点眼熟。
给的是个双解版修改的mdx 么(好像是![]()
争取下个版本改正发现的问题。
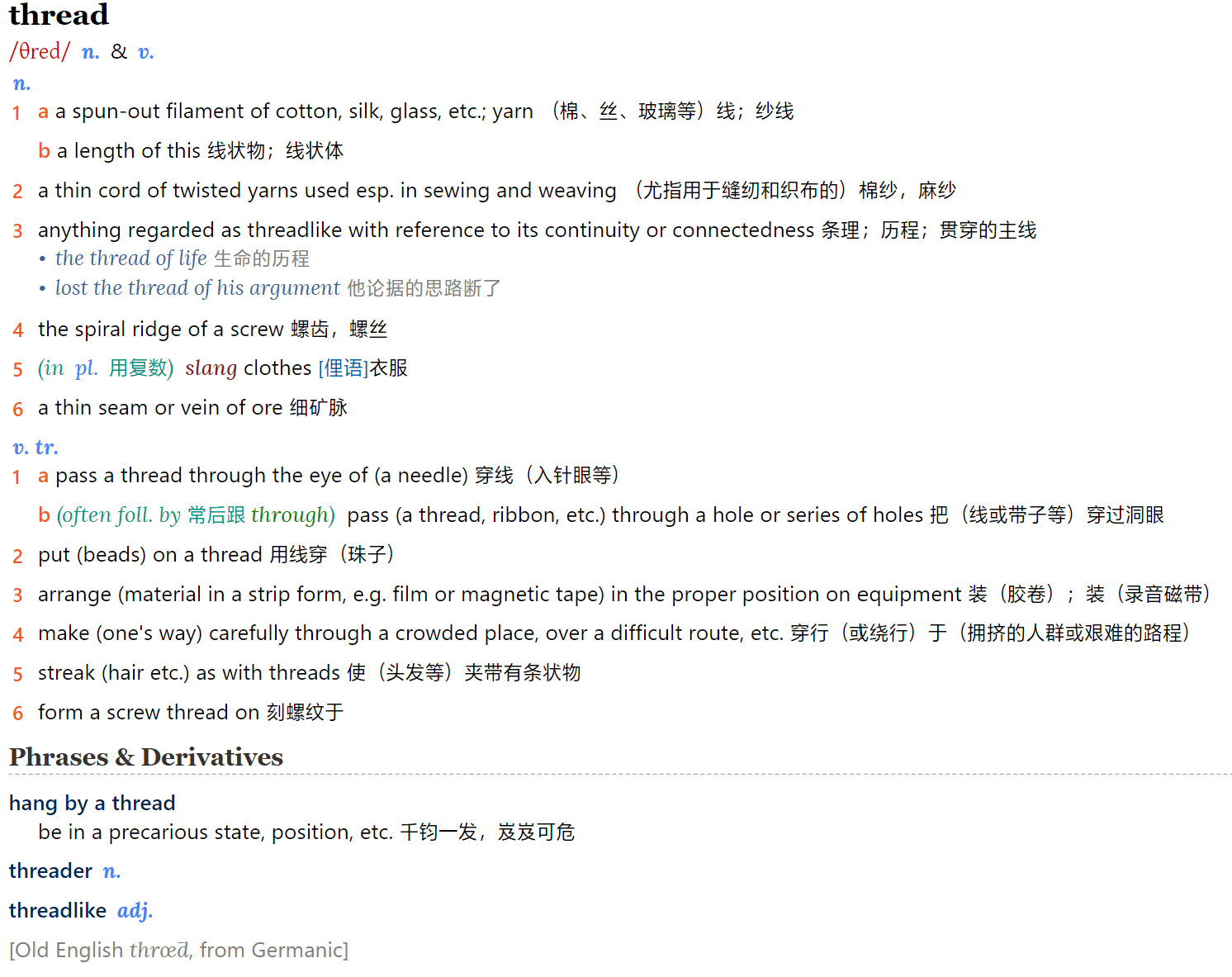
plus条没发现排版错误,希望有纸质中文版的截图
不过,本mdx版本尽力与牛津现代英汉双解词典(第9版)原版保持一致,不会根据英文版增改双解版内容,除非是明显的排版错误。
此外,这个MDX估计还有不少标签不完整的问题,逐步完善吧
感谢楼主分享~~
COD9 双解切换2022-10-18
COD9双解切换2022-10-18.rar (11.7 MB)
补上全mdx三十多处“亦作”前后缺失的<cn>标签
修正词头中多余的<tm>标签;copyread词头问题
借助 @last_idol 检查标签的工具,修正缺失或错置的html标签
参考tsiank的帖子,尽可能修正了所发现century/open sesame等排版错误,个别单词中的法语字母ɒ̃改为â等等;
其他:改用扩展B区的"𬭳、𬬻";ask条第三释义、stitch up条第三释义的错置
![]()
靴靴你 ,因为有你,温暖了司机
谢谢分享cod9
,想问下这个工具在哪,想用
我手头没有这个工具,是请 @last_idol 把检查结果发给我的。检查结果是个文本文件,提示×行×列标签有误,每个错误一行。
牛津英汉辞书这三个MDX的标签有缺失或错置等小瑕疵,有不少人都试图改进。比如有用beautifulsoup强行补全标签的,但这样批量处理又新增了一些新问题。
我觉得有能力和意愿改进的,如果借助这个工具的提示、逐一调整一下有问题的标签,应该能制作出一个更好的版本出来,整个文本篇幅也不算大。
endnote 哥,是参考了 海宝 网页的纠错嘛,差了几个法文词组都纠正了![]()
![]()
多谢更新。提个建议,关于词条末尾的Phrases & Derivatives部分,能否去掉这个phrases & Derivatives标识,或者修改一下,感觉有些突兀。另外,其中的派生词的音标能否修改一下,目前的斜体和显示字体感觉和主词不协调。多谢了!

从截图上看,好像不是。
我贴的截图是266M的大小跟Cloud一样,而 @hahaya 截图要清晰很多。我没赶上,能再分享一次吗?
我觉得OCD9双解版还是很有参考价值的。而COED双解版意义不大,因为ODE有双解版了。
有啊,你对比一下#56和#88,肉眼可见
你要pdf的时候不是说校对吗?
第9版的牛津现代英汉双解词典,确实没有找到特别完整高清的PDF版本,只找到一个1.23G的切边版本
cod9ec.css (6.1 KB)
字体.zip (506.2 KB)
css样式调整,主要改动是去掉原版的背景色,使字体、颜色和大小更加统一。
使用双解切换版的将原版css的296行到末尾复制粘贴进来就行了
Concise Oxford Dictionary
Concise 版 CSS for PC(无切换):
其他说明:
See main entry at with css ` 字样,改成一个图标。感谢楼主制作并分享
可以进一步优化的方向
See main entry at 是原书没有的,理应符合原书的简明风格如“see mainEntry”至少不能这么长,COD全篇用了很多缩写,而这几个词简直出戏。可以替换为空,然后由css自由添加标记。突出一个Concise。' 省略号('m)&符号(A. & m.)'mongst中的第一个跳转没有词头,只是次级变形,点击后查不到词;在第二个跳转的一级词头中。这个是英式写法的查询的索引词头提取的问题。<apd>(e.g. <cn>如 </cn><x>perspire</x> for <x>sweat</x> <cn>用</cn> perspire <cn>代替</cn> sweat)</apd>中,双解的 perspire for sweat 用 perspire 代替 sweat) 切换成英文时变成了perspire for sweat perspire sweat 好在只是冗余的无效信息,不是缺漏。<prx><pos>det.</pos> (also <h>an</h> before a vowel <cn>在元音前亦作</cn> an) (<x>called the indefinite article</x> <cn>不定冠词</cn>)</prx> 这里的 also an before a vowel 是完整的,汉解应该是"在元音前亦作 an", 而不是“在元音前亦作”。prx cn: display:none 了!-a词条下的
进度:42/2871 done.