前言
《日本語非辞書形辞典》项目主要是为了提高看日语小说时的查词速度,但由于本人精力有限,一直只提供mdx格式下载。作为词典制作者和使用者(非词典软件开发者),我对这种格式很满意。
不过,我看小说时使用的词典软件们却齐刷刷地转投其他阵营:
idx:即Stardict格式的词典,多见于各大国产电子书阅读器,比如博阅系统、Kindle多看阅读系统以及真·跨平台开源阅读APP KOReader
txt:AnkiHelper(这个不支持mdx可以理解
zip:日语划词插件Yomichan支持的格式(我实在不想去折腾mdx怎么转EPWING
mobi:Kindle支持的词典格式,但如果想在Android和iOS上使用,请参考这里的方法,但是单词卡既没有记录上下文的功能,也没有动词活用推导功能。
kobo:日本电子书厂商,未使用过该产品。只是注意到其有专门的词典格式,估计也不支持 mdx。
前不久发现了Python 第三方库 pyglossary ——一个提供了多种词典快速转换工具。
从本人的实际体验来看:mdx转idx时会处理mdx格式独有@@@跳转语法,还会将mdx的部分语法转为idx支持的语法,秒杀本人之前提出的蹩脚方案,对此,本人只能振臂高呼:Open Source Made Python Great Again! Life is Short, you need Python:)
只需花5分钟阅读PyGlossary:将不同格式的字典转换成 Kindle 字典(看完第一步就可以了),然后花10分钟配置好环境,再花5分钟就可以得到一本新鲜出炉的idx词典了。
如果有强迫症、有时间、有能力(懂一点点Python即可),可以接着阅读本帖,通过本人提供的转换脚本,不仅可以一键批量转换,还可以收获更完美的阅读体验。
有多完美呢?楼主在用 KOReader 测试词典时直接一口气读完了一本《古書堂》233。多说一句,KOReader 用来看日语原文书真的是个大杀器,对日语的活用处理堪比Kindle设备,而且也有Kindle设备独有的保存单词上下文功能(APP没有),还有间隔重复算法安排复习)
以下部分只谈mdx转idx的,欢迎坛友替大家踩其他格式转换的坑:
v2 · NoHeartPen/NonJishoKei - 码云 - 开源中国 (gitee.com)
NonJishoKei/v2/mdx2idx at master · NoHeartPen/NonJishoKei (github.com)
快速上手
请下载《日本語非辞書形辞典》项目v2文件夹下的所有文件,在mdx2idx文件夹,运行add_index.py脚本,脚本运行成功会生成一个名为done的txt文件。
将想转换的 mdx 词典用 getDic 等软件解压为 txt 文件,把add_index.py脚本生成的done的txt文件添加到解压后的 txt 文件中(注意 mdx 源文件的格式要求),然后打包为 mdx,再使用 PyGlossary 将重新打包的 mdx 转为 idx 即可。关于 PyGlossary 的使用方法,可以参考项目官网 GitHub - ilius/pyglossary: A tool for converting dictionary files aka glossaries. Mainly to help use our offline glossaries in any Open Source dictionary we like on any operating system / device. 和这篇教程 PyGlossary:将不同格式的字典转换成 Kindle 字典
高级指南
批量转换
如果希望快速转换多本词典,请通过命令行pip install -r requirements.txt安装相关依赖(请在mdx2idx文件夹下使用这条命令)。
将所有 mdx 文件放到mdx2idx文件夹下,运行main.py脚本,等待片刻即可。
自定义索引
由于 idx 的跳转特性,转换好的词典可能会包含一些无法跳转的链接。如果不想在这些无意义的跳转链接中浪费时间,可以将v2文件夹下index内的index.txt里的内容删除,然后替换为想转换的词典的词条,再执行main.py。
词条导出方法:可以使用 GoldenDict,在词典详情界面右键查看词条然后导出的文本,不需要删除たべる【食べる】这样的词条,脚本会自动处理,也不需要包含词性。
多语言支持
如果将index.txt替换为其他按照词形变化 原型格式储存的数据,比如:
perceived perceive
perceived perceive
perceives perceive
perceiving perceive
那么,本项目提供的脚本就可以用于其他语言的 mdx 转 idx。由于精力有限,本项目暂不提供这样的数据,有需要的同学请自行尝试。
英语的词形变化数据可以参考:Free English to Chinese Dictionary Database
转换 mdd 文件
如果希望转换 mdd 文件,请将 mdd 文件和 mdx 一起放在mdx2idx文件夹下,然后运行main.py。
请注意:这种方式只能保证 PyGlossary 会识别并处理 mdd 文件,转换的 idx 可能存在图片显示为[image]的情况。
删除 HTML 标签
PyGlossary 不会处理不被 idx 支持的 mdx 源文件语法,有需要和有时间的同学可以参考这部分的内容,自行修改.process文件夹下dics解压出的源文件,修改完成后,请运行pack_mdx.py,不要运行main.py文件。
- 不支持
<a class="link" href="javascript:;">(.*?)</a>跳转语法- 替换参考正则:
<a href="entry://\1">\1</a>
- 替换参考正则:
- 不支持
<img alt="" src="data:image/png;base64,(.*?)>这样含有 base64 码的图像标签- 替换参考正则:替换为空即可
- StarDict似乎不支持图片,可以考虑手动删除图片标签
<img (.*?)>
<span>(.*?)</span>标签:- 替换参考正则:替换为空即可
- PyGlossary 似乎会按照特殊的格式渲染该标签的文本
……(欢迎补充反馈)
转换为其他格式
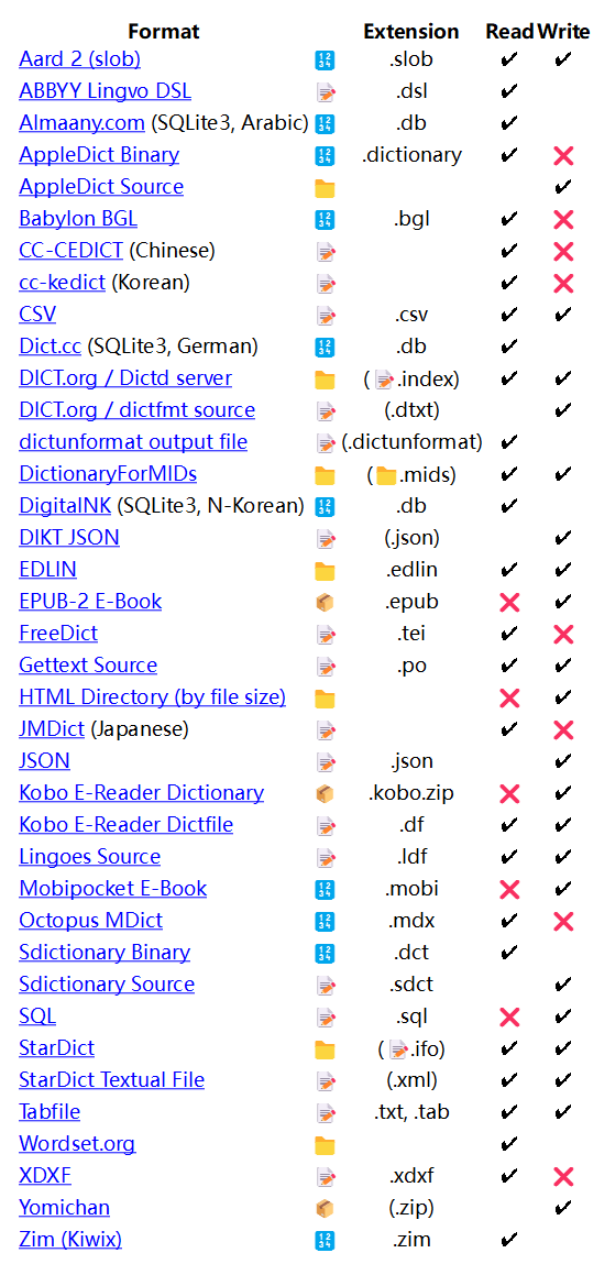
pyglossary 提供如下格式转换支持:
有需要的同学请自行修改convert_idx.py的内容。
词典分享
最后,分享本人打磨了3天的《新世纪日汉双解大辞典》,在使用脚本转换并补充了大量词条的基础上,删除了[image]等不被支持的标签,还对中日文解释做了排版的分割调整,简洁清晰,适合各个阶段的日语学习者使用,也期待看到各位的作品:)
https://cloud.freemdict.com/index.php/s/FwxqieecqHzsCee
有和楼主一起挑战一晚读完第五次圣杯战争的Fate厨吗233