䩶(兩個字形佔同一個字碼)
筮(模擬單欄)

《漢語大字典》(2010) 第二版 九卷本
圖文綜版的使用:
- 點擊字目、或字條右邊緣來展現圖像頁面。
- 在頁面,點擊左右邊緣來翻頁;點擊中間來關閉頁面。
- 窗口放大,則展現整頁圖像;縮窄,則模擬單欄模式。
- 注意:不能讓軟件控制列圖寬度,否則CSS無效。
MDict app:關掉“Settings: View: Resize images to fit in window”.
Dict Tango:勾選 “詞典管理:編輯詳情:禁止自動調整圖片”。
2023.9.15
- 更新到 Unicode 15.1:“𮱣”、“𮱻”、“𮲡”、“𮲔”四字頭,‘旊’字下的“𮲡”,‘𣖒’字下的“㇯” 。
2023.8.4
- 收受匿名捐贈者的數據,補充了 2,400 有字頭、無釋義的字條,終於完成了文字版。這數據缺專名號,所以手工增補。
- 字頭:60,367。其中 2,000 字沒有統一編碼,字目標朱色。字碼用‘全宋體’的 PUA(私有區字),可與‘部件檢索’通用。
- 內嵌字型用‘中華書局’字形,以 G 字樣爲主。紙書若與 G 字樣脫離,則字目標綠色。中華書局字型所缺的(尤其是 PUA、G 區、H區,及 T 字形),我修了 300 形,配合中華書局規度與風格,餘形借用其他字型補充。
- 268 字目,用圓括號列出相似字形。主要給 PUA 字提供對應的標準字,可與其他字典通用,如“(𢃵)”、“(𥔄)”、“(䖫)”。或紙書字形失真,提供忠實於書證的字形,如“𦸥()”、“(𢃛)”、“(𢁂)”。
舊記錄:
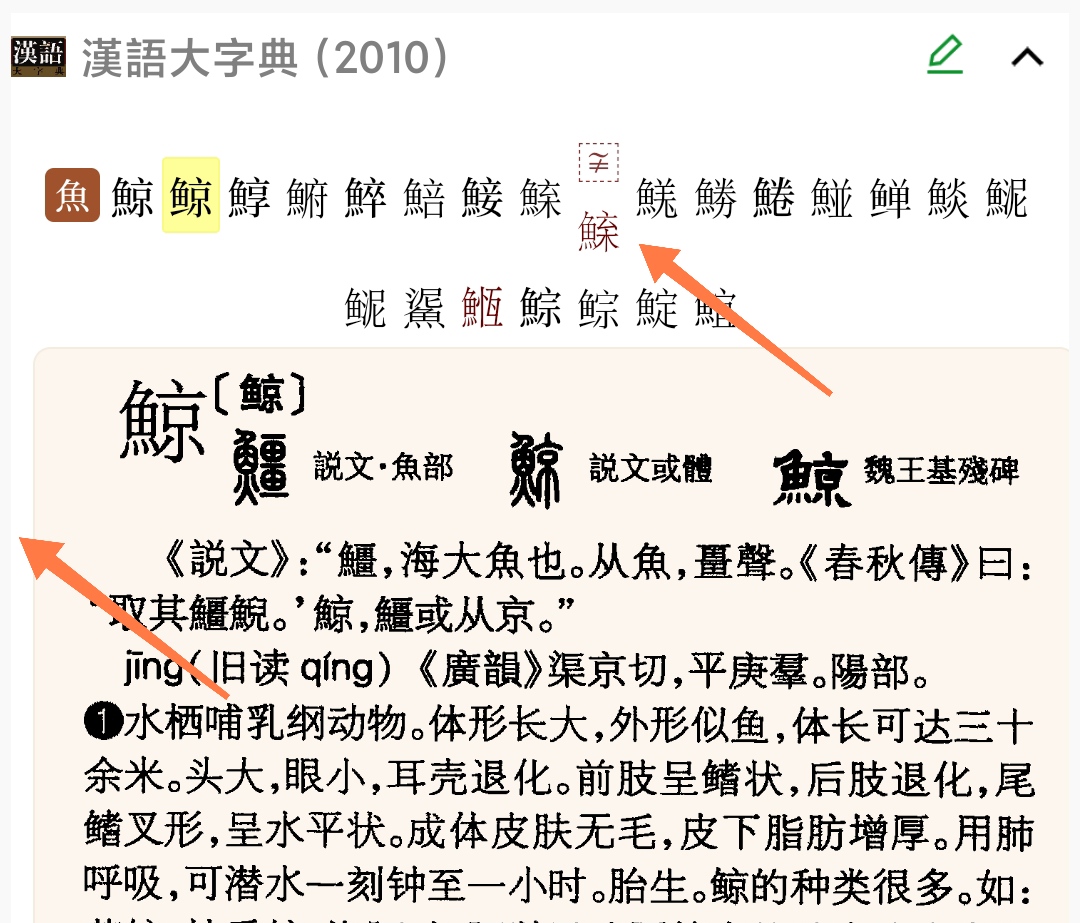
- 字頭中 36 字,其 Unicode 編碼包含 G(國標)、T 兩形,《大字典》兼收而分成兩條。兩形佔同一個字碼,因此字碼重出,我用特製字型來分辨:龜犮丽充育㤺裗㡛宂壳𦥨䃣䈧䞈儰蟡摾糨珊粣跚𤜂𥶽㨰㪌䩶宐鵖檨𤲸𪑿𣯉𤰣𥾬𧔠𦣹。(兩個“𦣹”實爲同字,字典偏分成兩條。)非 G 字樣的字形,字目標綠色。
- 字頭中 20 字組,《大字典》不分,但 Unicode 有所分辨,字目旁邊提供對應的字:夐曶壿胊朦朏脧朌䐠朣脼朡䏓朧胶䏙𦝲䐋肭𣎛。
- 復詞跳轉:10,000。單字跳轉:4,000;這種跳轉加得較謹慎,原則上局限於字形相近的異體,如“𡠌@媲”、“𡤞@䶯”、“𬱈@𩓔”。簡化字跳轉:2,000;都是《大字典》沒收的簡體(包括《通用規範漢字表》的字)和歷來俗體,如“劢@勱”、“桠@椏”、𬜯@䓣”、“𡞋@㜗”、“嘨@嘯”。
- ‘全息’數據問題多,例如“鄌”字頭出現三次,其中兩條實爲“岙”﹑“嶴”。內容混亂交錯:A 釋文誤插入 B 字條,使 A 條遺失或殘缺,又使 B 字條亂插衍文.如“𧚫”釋文混進“䘻”字條,“𧚫”字皆誤作“䘻”;“𦒜”﹑“翧”併成一條,“𦒜”字皆誤作“翧”;“𤴁”條重疊兩條等等。光這問題,就整理了六七百條⸺分開字條,歸回釋文,訂補字頭⸺結果分出 300 新條,例如:黁﹑𩐃﹑熚等。
- 原來引號(“”)前後兩半沒達到一對一的比例,說明紙本標點或漏或衍,我糾正了幾百處,然後把書證標籤化。Single quotes(‘’)仍不對稱,差一百筆,其格式有點曖昧,必須查書證資料才能準確整理,因此就擱著不動。
- 鳴謝 feiwu 新抓字條,我收納了一千條;感謝 alexpeng 整理出和標簽化一百多字條。
- 9.23 升級到 Unicode 15.0:字頭 51 字;釋文 5 字。
- 亂碼都解決了。2,000 多 “
 ” 符號,已經處理其五分之四。邊用邊改。
” 符號,已經處理其五分之四。邊用邊改。 - 索引更新到2021年Unicode 14.0版(等於把私有區字換成標準字),又經過幾輪校對,總共改了 2,400 字頭。
2022.3.29 首發