如果Unicode打过来了,我第一个跑 ![]()
2025.09.18更新:
1,属性“部首”改为“部首余笔”,符合直觉
2,4位码点不再首位补0,5位码点不变,提高与其他词典的查得率
三种查询方式,字头,Unicode码点,完整Unicode代码
㐀,3400,U+3400
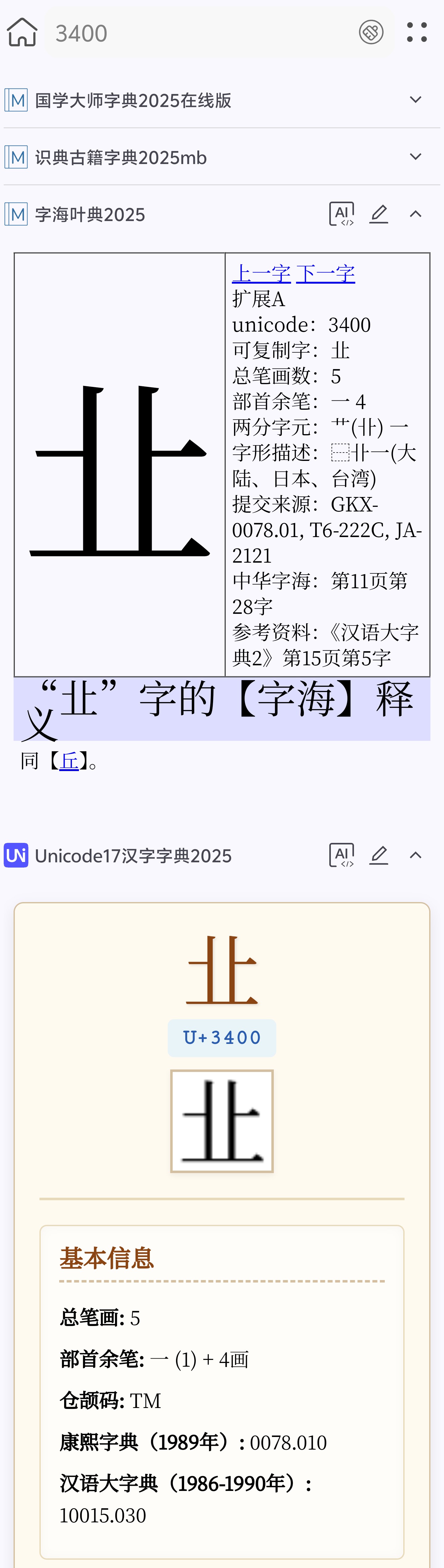
2025.09.17更新:
tango样式不一样是界面宽度策略不同,
手机欧陆字体不一样,是因为调用了国学大师2025的老文津字体,把国学大师2025的字体.mdd替换成文津宋体2.0就可以了(将此.mdd改个名,给国学大师用)
历史更新
总结
2025.09.15更新:
0更新图标,更新css,
1字体更新为文津宋体2.0,ttf转为woff2,需更新.mdd,换成ttf,改个名,给国学大师用,免得改css节外生枝
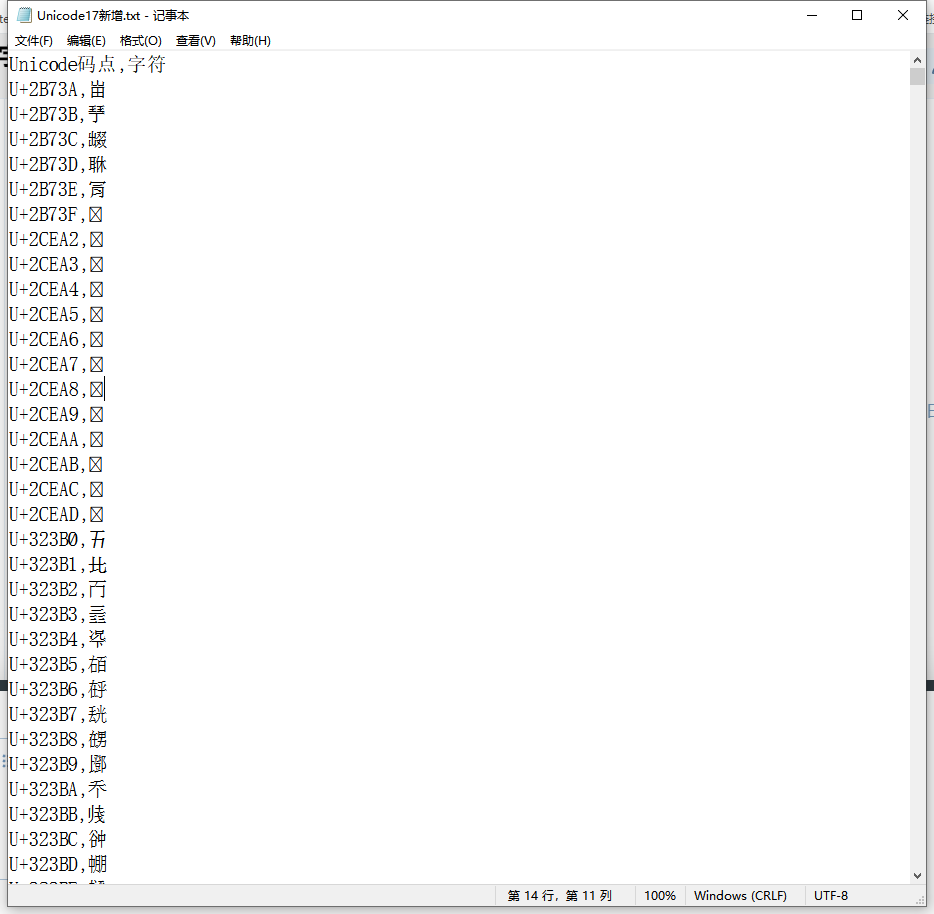
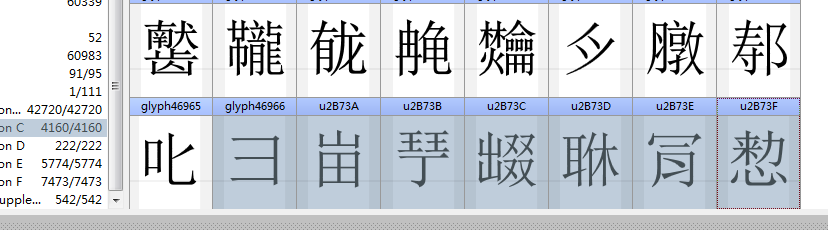
2按照Unicode17的字形变更,替换图片,需更新.1.mdd,测试汉字𫟂,U+2B7C2


2025.09.11更新:
1.更新至Unicode17正式版,102998汉字,各个有图有真相,
mdd为字体文件(WenJinMinchoP0-Regular.ttf,WenJinMinchoP2-Regular.ttf,WenJinMinchoP3-Regular.ttf,WenJinMinchoDevU17-Regular.otf),1.mdd为图片文件,方便自定义,
依照17的变化,删除两条属性
'kGB7': 'GB/T8565.2-1988', 'kJa': '日本工业标准',
2.完善所有序号和部首
序号和部首
“1”: “一”,
“2”: “丨”,
“3”: “丶”,
“4”: “丿”,
“5”: “乙”,
“6”: “亅”,
“7”: “二”,
“8”: “亠”,
“9”: “人”,
“10”: “儿”,
“11”: “入”,
“12”: “八”,
“13”: “冂”,
“14”: “冖”,
“15”: “冫”,
“16”: “几”,
“17”: “凵”,
“18”: “刀”,
“19”: “力”,
“20”: “勹”,
“21”: “匕”,
“22”: “匚”,
“23”: “匸”,
“24”: “十”,
“25”: “卜”,
“26”: “卩”,
“27”: “厂”,
“28”: “厶”,
“29”: “又”,
“30”: “口”,
“31”: “囗”,
“32”: “土”,
“33”: “士”,
“34”: “夂”,
“35”: “夊”,
“36”: “夕”,
“37”: “大”,
“38”: “女”,
“39”: “子”,
“40”: “宀”,
“41”: “寸”,
“42”: “小”,
“43”: “尢”,
“44”: “尸”,
“45”: “屮”,
“46”: “山”,
“47”: “巛”,
“48”: “工”,
“49”: “己”,
“50”: “巾”,
“51”: “干”,
“52”: “幺”,
“53”: “广”,
“54”: “廴”,
“55”: “廾”,
“56”: “弋”,
“57”: “弓”,
“58”: “彐”,
“59”: “彡”,
“60”: “彳”,
“61”: “心”,
“62”: “戈”,
“63”: “戶”,
“64”: “手”,
“65”: “支”,
“66”: “攴”,
“67”: “文”,
“68”: “斗”,
“69”: “斤”,
“70”: “方”,
“71”: “无”,
“72”: “日”,
“73”: “曰”,
“74”: “月”,
“75”: “木”,
“76”: “欠”,
“77”: “止”,
“78”: “歹”,
“79”: “殳”,
“80”: “毋”,
“81”: “比”,
“82”: “毛”,
“83”: “氏”,
“84”: “气”,
“85”: “水”,
“86”: “火”,
“87”: “爪”,
“88”: “父”,
“89”: “爻”,
“90”: “爿”,
“90’”: “丬”,
“91”: “片”,
“92”: “牙”,
“93”: “牛”,
“94”: “犬”,
“95”: “玄”,
“96”: “玉”,
“97”: “瓜”,
“98”: “瓦”,
“99”: “甘”,
“100”: “生”,
“101”: “用”,
“102”: “田”,
“103”: “疋”,
“104”: “疒”,
“105”: “癶”,
“106”: “白”,
“107”: “皮”,
“108”: “皿”,
“109”: “目”,
“110”: “矛”,
“111”: “矢”,
“112”: “石”,
“113”: “示”,
“114”: “禸”,
“115”: “禾”,
“116”: “穴”,
“117”: “立”,
“118”: “竹”,
“119”: “米”,
“120”: “糸”,
“120’”: “纟”,
“121”: “缶”,
“122”: “网”,
“123”: “羊”,
“124”: “羽”,
“125”: “老”,
“126”: “而”,
“127”: “耒”,
“128”: “耳”,
“129”: “聿”,
“130”: “肉”,
“131”: “臣”,
“132”: “自”,
“133”: “至”,
“134”: “臼”,
“135”: “舌”,
“136”: “舛”,
“137”: “舟”,
“138”: “艮”,
“139”: “色”,
“140”: “艸”,
“141”: “虍”,
“142”: “虫”,
“143”: “血”,
“144”: “行”,
“145”: “衣”,
“146”: “襾”,
“147”: “見”,
“147’”: “见”,
“148”: “角”,
“149”: “言”,
“149’”: “讠”,
“150”: “谷”,
“151”: “豆”,
“152”: “豕”,
“153”: “豸”,
“154”: “貝”,
“154’”: “贝”,
“155”: “赤”,
“156”: “走”,
“157”: “足”,
“158”: “身”,
“159”: “車”,
“159’”: “车”,
“160”: “辛”,
“161”: “辰”,
“162”: “辵”,
“163”: “邑”,
“164”: “酉”,
“165”: “釆”,
“166”: “里”,
“167”: “金”,
“167’”: “钅”,
“168”: “長”,
“168’”: “长”,
“169”: “門”,
“169’”: “门”,
“170”: “阜”,
“171”: “隶”,
“172”: “隹”,
“173”: “雨”,
“174”: “靑”,
“175”: “非”,
“176”: “面”,
“177”: “革”,
“178”: “韋”,
“178’”: “韦”,
“179”: “韭”,
“180”: “音”,
“181”: “頁”,
“181’”: “页”,
“182”: “風”,
“182’”: “风”,
“182’'”: “𲋄”,
“183”: “飛”,
“183’”: “飞”,
“184”: “食”,
“184’”: “饣”,
“185”: “首”,
“186”: “香”,
“187”: “馬”,
“187’”: “马”,
“188”: “骨”,
“189”: “高”,
“190”: “髟”,
“191”: “鬥”,
“192”: “鬯”,
“193”: “鬲”,
“194”: “鬼”,
“195”: “魚”,
“195’”: “鱼”,
“196”: “鳥”,
“196’”: “鸟”,
“197”: “鹵”,
“197’”: “卤”,
“198”: “鹿”,
“199”: “麥”,
“199’”: “麦”,
“200”: “麻”,
“201”: “黃”,
“201’”: “黄”,
“202”: “黍”,
“203”: “黑”,
“204”: “黹”,
“205”: “黽”,
“205’”: “黾”,
“206”: “鼎”,
“207”: “鼓”,
“208”: “鼠”,
“208’'”: “鼡”,
“209”: “鼻”,
“210”: “齊”,
“210’”: “齐”,
“210’'”: “斉”,
“211”: “齒”,
“211’”: “齿”,
“211’'”: “歯”,
“212”: “龍”,
“212’”: “龙”,
“212’'”: “竜”,
“212’‘’”: “𱷥”,
“213”: “龜”,
“213’”: “龟”,
“213’'”: “亀”,
“214”: “龠”,
3.完善属性翻译,照抄总汇的翻译
英文-原AI翻译-总汇翻译
‘unicode’: ‘Unicode码点’,
‘character’: ‘字符’,
‘kCompatibilityVariant’: ‘兼容变体’,“兼容字符”,
‘kIICore’: ‘国际表意文字核心子集(IICore)’,“IRG Minimal Set of Required Ideographs”,
‘kIRG_GSource’: ‘中国大陆源’,“IRG 中国/新加坡”,
‘kIRG_HSource’: ‘中国香港源’,“IRG 香港”,
‘kIRG_JSource’: ‘日本源’,“IRG 日本”,
‘kIRG_KPSource’: ‘朝鲜源’,“IRG 朝鲜”,
‘kIRG_KSource’: ‘韩国源’,“IRG 韩国”,
‘kIRG_MSource’: ‘蒙古源’,“IRG 澳门”,
‘kIRG_SSource’: ‘新加坡源’,“IRG SAT 大正新修大藏经编辑委员会”,
‘kIRG_TSource’: ‘中国台湾源’,“IRG 台北市电脑公会”,
‘kIRG_UKSource’: ‘英国源’,“IRG 英国”,
‘kIRG_USource’: ‘美国源’,“IRG 统一码技术委员会”,
‘kIRG_VSource’: ‘越南源’,“IRG 越南”,
‘kRSUnicode’: ‘Unicode部首笔画’,“部首”,
‘kTotalStrokes’: ‘总笔画数’,“总笔画”,
‘kCheungBauerIndex’: ‘张群显-白瑞德索引(香港中文大学汉字数据库索引)’,“Cheung & Bauer(2002年)”,
‘kCihaiT’: ‘辞海(繁体版)’,“辞海(1983年)”,
‘kCowles’: ‘Cowles索引’,“Cowles(1999年)”,
‘kDaeJaweon’: ‘韩语大字典(Dae Jaweon)页码’,“汉韩大辞典(1988年)”,
‘kFennIndex’: ‘Fenn索引’,“Fenn(1942年)”,
‘kGSR’: ‘高本汉《汉文典》(Grammata Serica Recensa)’,“Kalgren(1957年)”,
‘kHanYu’: ‘汉语大字典’,“汉语大字典(1986-1990年)”,
‘kIRGDaeJaweon’: ‘IRG韩语大字典’,“汉韩大辞典 [IRG](1988年)”,
‘kIRGHanyuDaZidian’: ‘IRG汉语大字典’,“汉语大字典 [IRG](1986年)”,
‘kIRGKangXi’: ‘IRG康熙字典’,“康熙字典 [IRG](1989年)”,
‘kKangXi’: ‘康熙字典’,“康熙字典(1989年)”,
‘kKarlgren’: ‘高本汉索引’,“Kalgren(1974年)”,
‘kLau’: ‘Lau索引’,“Lau(1977年)”,
‘kMatthews’: ‘Matthews索引’,“Matthews(1975年)”,
‘kMeyerWempe’: ‘Meyer-Wempe索引’,“Meyer & Wempe(1947年)”,
‘kMorohashi’: ‘日本《大汉和辞典》(Morohashi)’,“大汉和辞典(1986年)”,
‘kNelson’: ‘Nelson索引’,“Nelson(1974年)”,
‘kSBGY’: ‘《宋本广韵》(韵书)’,“广韵(宋版)”,
‘kSMSZD2003Index’: ‘《现代汉语规范字典》(2003年版)’,
‘kCantonese’: ‘粤语拼音’,“广东话”,
‘kDefinition’: ‘英文定义’,“定义”,
‘kFanqie’: ‘反切’,
‘kHangul’: ‘韩语发音’,“韩文”,
‘kHanyuPinlu’: ‘拼音频率’,“中文(现代汉语频率词典)”,
‘kHanyuPinyin’: ‘汉语拼音’,“中文(汉语大字典)”,
‘kJapanese’: ‘日语发音’,
‘kJapaneseKun’: ‘日语训读’,“日语训读”,
‘kJapaneseOn’: ‘日语音读’,“日语音读”,
‘kKorean’: ‘韩语罗马字’,“韩语(耶鲁)”,
‘kMandarin’: ‘普通话拼音’,“中文”,
‘kSMSZD2003Readings’: ‘《现代汉语规范字典》(2003年版)拼音’,
‘kTang’: ‘中古汉语’,“唐代音(Stimson 1976年)”,
‘kTGHZ2013’: ‘《通用规范汉字表》(2013年版)’,“中文(通用规范汉字字典 2013年)”,
‘kVietnamese’: ‘越南语发音’,“越南语”,
‘kXHC1983’: ‘《现代汉语词典》(1983年版)’,“中文(现代汉语词典 1983年)”,
‘kZhuang’: ‘壮语发音’,
‘kAlternateTotalStrokes’: ‘替代笔画数’,
‘kCangjie’: ‘仓颉编码’,“仓颉码”,
‘kCheungBauer’: ‘张群显-白瑞德的研究数据’,
‘kFenn’: ‘Fenn编码’,
‘kFourCornerCode’: ‘四角号码’,“四角号码”,
‘kGradeLevel’: ‘学习等级’,“香港年级水平”,
‘kHDZRadBreak’: ‘《汉语大字典》部首拆分’,“《汉语大字典》部首段*”,
‘kHKGlyph’: ‘香港字形’,“常用字字形表(2000年)”,
‘kMojiJoho’: ‘日本文字情报数据库(Moji Joho Kiban)’,
‘kPhonetic’: ‘音标’,“Casey(1980年)”,
‘kStrange’: ‘特殊标记’,
‘kUnihanCore2020’: ‘2020年版的Unihan核心字符集’,“UnihanCore2020 Minmal Set of Required Ideographs”
‘kBigFive’: ‘Big5编码’,“大五码”,
‘kCCCII’: ‘CCCII编码’,“中文资讯交换码(CCCII)”,
‘kCNS1986’: ‘CNS1986’,“中文标准交换码(CNS 11643-1986)”,
‘kCNS1992’: ‘CNS1992’,“中文标准交换码(CNS 11643-1992)”,
‘kEACC’: ‘EACC编码’,“东亚文字码(EACC)”,
‘kGB0’: ‘GB2312-80’,“国标(GB/T 2312-1980)”,
‘kGB1’: ‘GB/T12345-90’,“国标(GB/T 12345-1990)”,
‘kGB3’: ‘GB7589-87’,“国标(GB/T 13131)”,
‘kGB5’: ‘GB7590-87’,“国标(GB/T 13132)”,
‘kGB8’: ‘GB/T8565.3-1988’,“国标(GB/T 8565.2-1988)”,
‘kIBMJapan’: ‘IBM日本’,
‘kJinmeiyoKanji’: ‘日本人名用汉字’,“人名用汉字(2010-2017年)”,
‘kJis0’: ‘JIS X0208-1983’,“日本产业规格(JIS X 0208-1990)”,
‘kJis1’: ‘JIS X0212-1990’,“日本产业规格(JIS X 0212-1990)”,
‘kJIS0213’: ‘JIS X0213:2000’,“日本产业规格(JIS X 0213:2004)”,
‘kJoyoKanji’: ‘日本常用汉字’,“常用汉字(2010年)”,
‘kKoreanEducationHanja’: ‘韩国教育用汉字’,“韩文教育用基础汉字(2007年)”,
‘kKoreanName’: ‘韩国人名用汉字’,“人名用汉字(2015年)”,
‘kMainlandTelegraph’: ‘大陆电报码’,“中文电码”,
‘kPseudoGB1’: ‘伪GB1’,“信息交换用汉字编码字符集 GB/T 12345-1990”,
‘kTaiwanTelegraph’: ‘台湾电报码’,“台湾电报码”,
‘kTGH’: ‘《通用规范汉字表》编号’,“通用规范汉字表(2013年)”,
‘kXerox’: ‘施乐编码’,“Xerox编码”,
‘kSemanticVariant’: ‘语义变体’,“意义相近异体字”,
‘kSimplifiedVariant’: ‘简体变体’,“简体字*”,
‘kSpecializedSemanticVariant’: ‘专业语义变体’,“特殊语义异体字”,
‘kSpoofingVariant’: ‘欺骗性变体’,“欺骗性异体字”,
‘kTraditionalVariant’: ‘繁体变体’,“繁体字”,
‘kZVariant’: ‘字形变体’,“Z异体字”,
‘kRSAdobe_Japan1_6’: ‘Adobe Japan1-6字符部首笔画’,
‘kAccountingNumeric’: ‘会计数字’,“数值(会计)”,
‘kOtherNumeric’: ‘其他数字’,“数值(其他)”,
‘kPrimaryNumeric’: ‘基本数字’,“数值(主要)*”,
‘kTayNumeric’: ‘泰语数字’,
‘kVietnameseNumeric’: ‘越南语数字’,
‘kZhuangNumeric’: ‘壮语数字’
总汇的翻译
{
“unihan.kFenn”: “Fenn(1979年)”,
“unihan.kPseudoGB1”: “信息交换用汉字编码字符集 GB/T 12345-1990”,
“unihan.kIBMJapan”: “IBM日本”,
“unihan.kJa”: “Unified Japanese IT Vendors Contemporary Ideographs 1993”,
“unihan.kDefinition”: “定义”,
“unihan.kJis0”: “日本产业规格(JIS X 0208-1990)”,
“unihan.kPrimaryNumeric”: “数值(主要)",
“unihan.kJis1”: “日本产业规格(JIS X 0212-1990)”,
“unihan.kJIS0213”: “日本产业规格(JIS X 0213:2004)”,
“unihan.kAccountingNumeric”: “数值(会计)”,
“unihan.kOtherNumeric”: “数值(其他)”,
“unihan.kRSUnicode[radical]”: “部首”,
“unihan.kTotalStrokes”: “总笔画”,
“unihan.kRSUnicode[residualStrokes]”: “部外笔画”,
“unihan.kCangjie”: “仓颉码”,
“unihan.kHangul”: “韩文”,
“unihan.kCCCII”: “中文资讯交换码(CCCII)”,
“unihan.kCNS1986”: “中文标准交换码(CNS 11643-1986)”,
“unihan.kFourCornerCode”: “四角号码”,
“unihan.kFrequency”: “使用频率”,
“unihan.kGradeLevel”: “香港年级水平”,
“unihan.kCompatibilityVariant”: “兼容字符”,
“unihan.kTraditionalVariant”: “繁体字”,
“unihan.kSimplifiedVariant”: "简体字”,
“unihan.kSemanticVariant”: “意义相近异体字”,
“unihan.kSpecializedSemanticVariant”: “特殊语义异体字”,
“unihan.kSpoofingVariant”: "欺骗性异体字 ",
“unihan.kZVariant”: “Z异体字”,
“unihan.kMandarin”: “中文”,
“unihan.kKorean”: “韩语(耶鲁)”,
“unihan.kVietnamese”: “越南语”,
“unihan.kCihaiT”: “辞海(1983年)”,
“unihan.kHanYu”: “汉语大字典(1986-1990年)”,
“unihan.kHanyuPinyin”: “中文(汉语大字典)”,
“unihan.kHanyuPinlu”: “中文(现代汉语频率词典)”,
“unihan.kXHC1983”: “中文(现代汉语词典 1983年)”,
“unihan.kTGHZ2013”: “中文(通用规范汉字字典 2013年)”,
“unihan.kCantonese”: “广东话”,
“unihan.kTang”: “唐代音(Stimson 1976年)”,
“unihan.kJapaneseKun”: “日语训读”,
“unihan.kJapaneseOn”: “日语音读”,
“unihan.kBigFive”: “大五码”,
“unihan.kIRGHanyuDaZidian”: “汉语大字典 [IRG](1986年)”,
“unihan.kIRGKangXi”: “康熙字典 [IRG](1989年)”,
“unihan.kKangXi”: “康熙字典(1989年)”,
“unihan.kSBGY”: “广韵(宋版)”,
“unihan.kMorohashi”: “大汉和辞典(1986年)”,
“unihan.kIRGDaiKanwaZiten”: “大汉和辞典 [IRG](1986年)”,
“unihan.kDaeJaweon”: “汉韩大辞典(1988年)”,
“unihan.kIRGDaeJaweon”: “汉韩大辞典 [IRG](1988年)”,
“unihan.kTGH”: “通用规范汉字表(2013年)”,
“unihan.kHKGlyph”: “常用字字形表(2000年)”,
“unihan.kJinmeiyoKanji”: “人名用汉字(2010-2017年)”,
“unihan.kHKSCS”: “大五码香港增补字符集-2008(HKSCS-2008)”,
“unihan.kJoyoKanji”: “常用汉字(2010年)”,
“unihan.kKoreanEducationHanja”: “韩文教育用基础汉字(2007年)”,
“unihan.kKoreanName”: “人名用汉字(2015年)”,
“unihan.kPhonetic”: “Casey(1980年)”,
“unihan.kCheungBauerIndex”: “Cheung & Bauer(2002年)”,
“unihan.kCowles”: “Cowles(1999年)”,
“unihan.kFennIndex”: “Fenn(1942年)”,
“unihan.kGSR”: “Kalgren(1957年)”,
“unihan.kKarlgren”: “Kalgren(1974年)”,
“unihan.kLau”: “Lau(1977年)”,
“unihan.kMatthews”: “Matthews(1975年)”,
“unihan.kMeyerWempe”: “Meyer & Wempe(1947年)”,
“unihan.kNelson”: “Nelson(1974年)”,
“unihan.kCNS1992”: “中文标准交换码(CNS 11643-1992)”,
“unihan.kEACC”: “东亚文字码(EACC)”,
“unihan.kGB0”: “国标(GB/T 2312-1980)”,
“unihan.kGB1”: “国标(GB/T 12345-1990)”,
“unihan.kGB3”: “国标(GB/T 13131)”,
“unihan.kGB5”: “国标(GB/T 13132)”,
“unihan.kGB7”: “国标(现代汉语通用规范汉字及简化字总表)”,
“unihan.kGB8”: “国标(GB/T 8565.2-1988)”,
“unihan.kRSAdobe_Japan1_6[mapping]”: “Adobe Japan 部首/总笔画/笔画”,
“unihan.kKPS0”: “朝鲜(KPS 9566-97)”,
“unihan.kKPS1”: “朝鲜(KPS 10721-2000)”,
“unihan.kKSC0”: “韩文(KS X 1001:1992)”,
“unihan.kKSC1”: “韩文(KS X 1002:1991)”,
“unihan.kMainlandTelegraph”: “中文电码”,
“unihan.kTaiwanTelegraph”: “台湾电报码”,
“unihan.kXerox”: “Xerox编码”,
“unihan.kIRG_GSource”: “IRG 中国/新加坡”,
“unihan.kIRG_HSource”: “IRG 香港”,
“unihan.kIRG_JSource”: “IRG 日本”,
“unihan.kIRG_KPSource”: “IRG 朝鲜”,
“unihan.kIRG_KSource”: “IRG 韩国”,
“unihan.kIRG_MSource”: “IRG 澳门”,
“unihan.kIRG_SSource”: “IRG SAT 大正新修大藏经编辑委员会”,
“unihan.kCheungBauer[radical]”: “部首(Cheung & Bauer)”,
“unihan.kCheungBauer[residualStrokes]”: “部外笔画(Cheung & Bauer)”,
“unihan.kIRG_TSource”: “IRG 台北市电脑公会”,
“unihan.kIRG_UKSource”: “IRG 英国”,
“unihan.kIRG_USource”: “IRG 统一码技术委员会”,
“unihan.kIRG_VSource”: “IRG 越南”,
“unihan.kRSKangXi[radical]”: “部首(Kangxi)”,
“unihan.kRSKangXi[residualStrokes]”: “部外笔画(Kangxi)”,
“unihan.kRSAdobe_Japan1_6[radical]”: “部首(Adobe Japan)”,
“unihan.kRSAdobe_Japan1_6[totalStrokes]”: “总笔画(Adobe Japan)”,
“unihan.kRSAdobe_Japan1_6[residualStrokes]”: “部外笔画(Adobe Japan)”,
“unihan.kRSAdobe_Japan1_6[radicalStrokes]”: “部首笔画(Adobe Japan)”,
“unihan.kCheungBauer[cangjie]”: “仓颉码(Cheung & Bauer)”,
“unihan.kCheungBauer[cantonese]”: “广东话(Cheung & Bauer)”,
“unihan.kHDZRadBreak”: “《汉语大字典》部首段*”,
“unihan.kIICore”: “IRG Minimal Set of Required Ideographs”,
“unihan.kUnihanCore2020”: “UnihanCore2020 Minmal Set of Required Ideographs”
}
4.跳转从显示码点改为显示汉字,
2025.06.30更新:
更新css,mdd,
Unicode17预览版,102998个字头,102998个字的图片,来自pdf,
Unicode16,补全98682个字的图片,来自pdf,
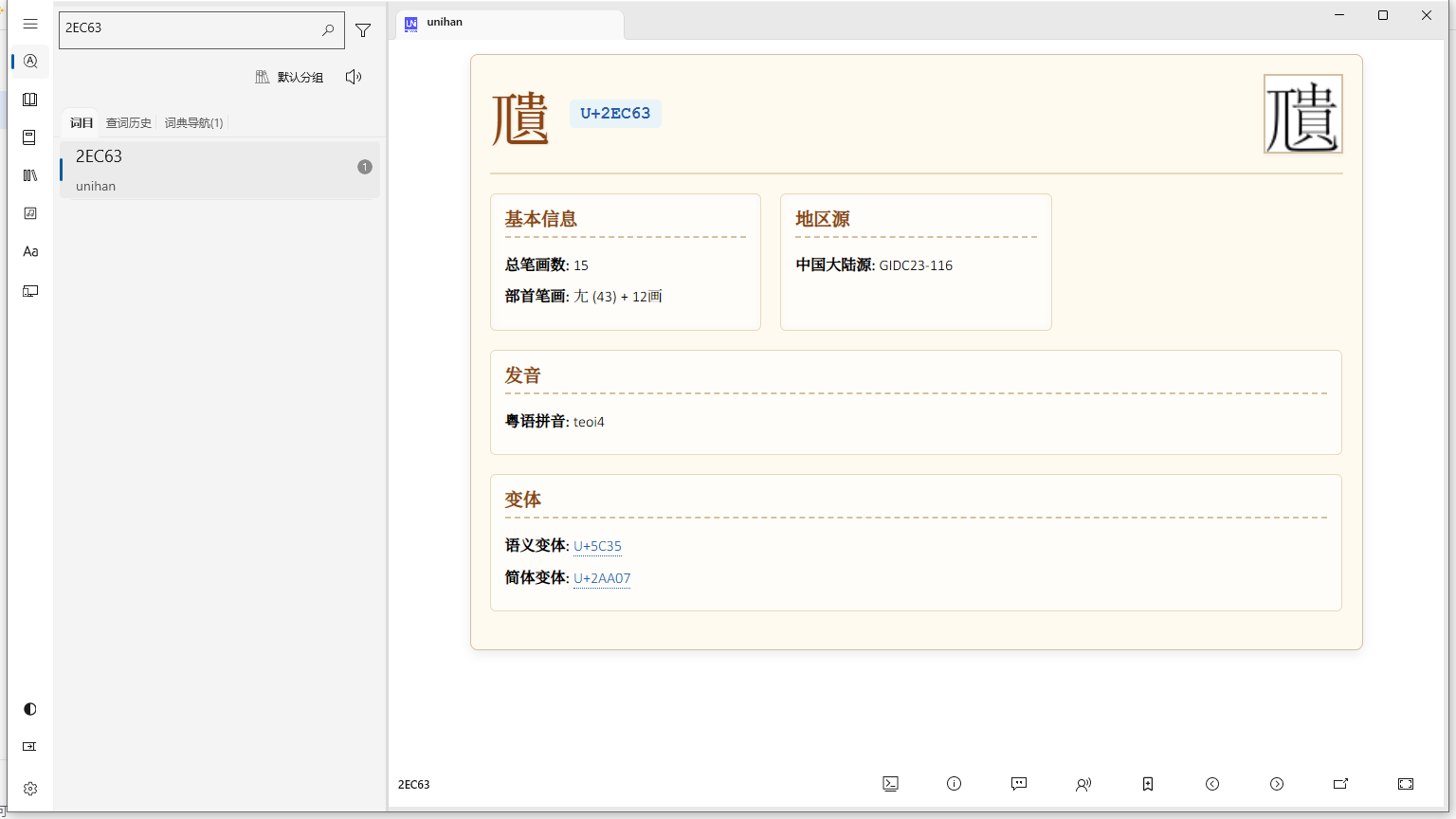
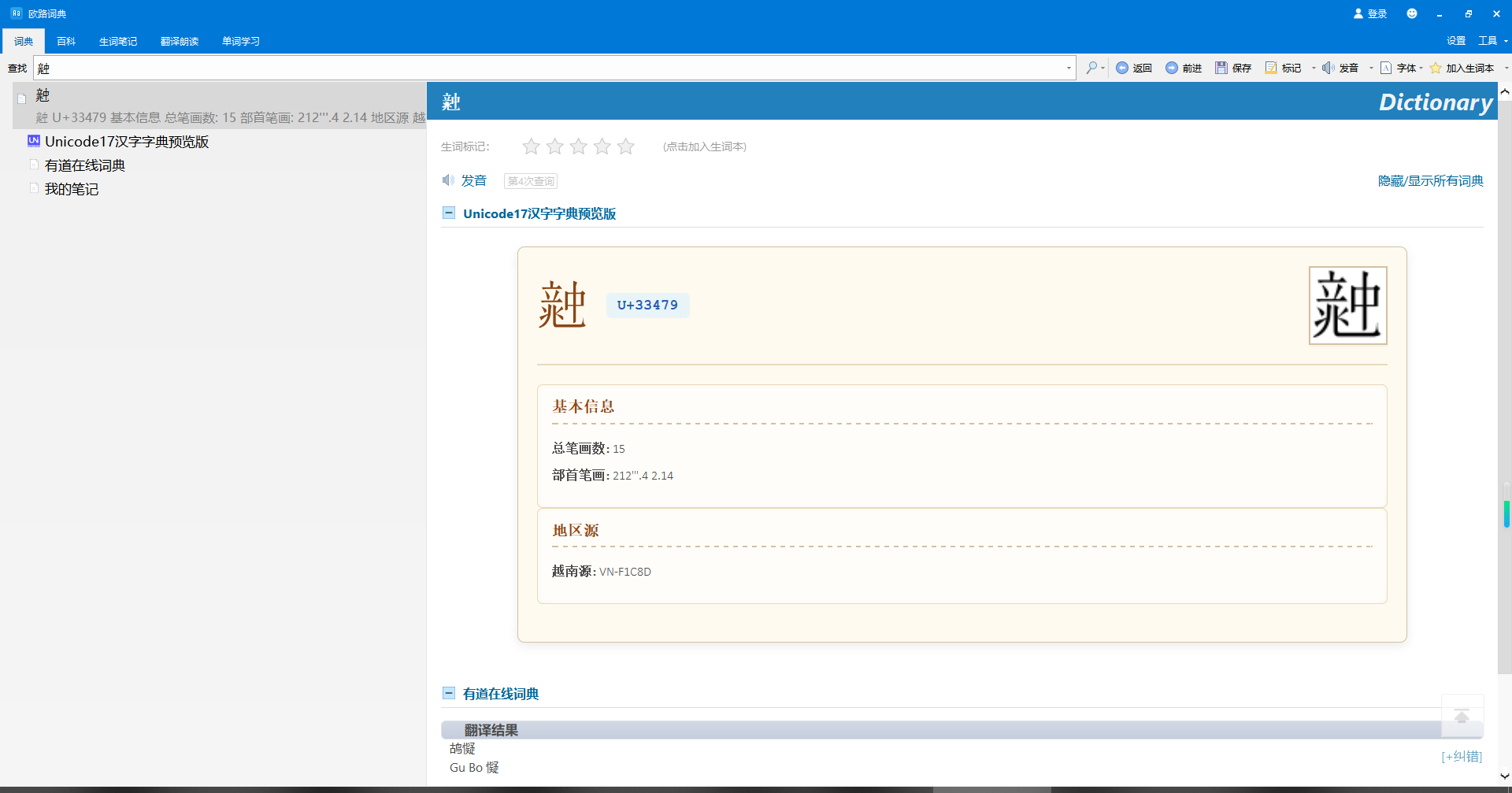
6个带三撇
U+31DE5,𱷥
U+31E22,𱸢
U+3267E,
U+32A83,
U+32C47,
U+33479,
87个带两撇
U+4E80,亀
U+5264,剤
U+6589,斉
U+6B6F,歯
U+7ADC,竜
U+9F21,鼡
U+9F62,齢
U+21676,𡙶
U+232F0,𣋰
U+23BE1,𣯡
U+2412F,𤄯
U+25269,𥉩
U+25A9D,𥪝
U+25A9E,𥪞
U+29091,𩂑
U+2964C,𩙌
U+2A5F1,𪗱
U+2A602,𪘂
U+2A61A,𪘚
U+2A6B2,𪚲
U+2A95B,𪥛
U+2AC6F,𪱯
U+2ADF9,𪷹
U+2AF5E,𪽞
U+2AFC1,𪿁
U+2B3FD,𫏽
U+2B5BC,𫖼
U+2B5BD,𫖽
U+2B5BE,𫖾
U+2B5BF,𫖿
U+2B5C0,𫗀
U+2B5C1,𫗁
U+2B5C2,𫗂
U+2B5C3,𫗃
U+2B5C4,𫗄
U+2B818,𫠘
U+2B81A,𫠚
U+2B81D,𫠝
U+2B840,𫡀
U+2BDD9,𫷙
U+2C099,𬂙
U+2C514,𬔔
U+2CC76,𬱶
U+2CC79,𬱹
U+2CC7B,𬱻
U+2CC81,𬲁
U+2CC82,𬲂
U+2CC83,𬲃
U+2CC84,𬲄
U+2CC87,𬲇
U+2CC88,𬲈
U+2CE74,𬹴
U+2CE97,𬺗
U+2CE98,𬺘
U+2CE99,𬺙
U+2CE9A,𬺚
U+2E13F,𮄿
U+2EBBE,𮮾
U+2EBC3,𮯃
U+2EBC5,𮯅
U+2EBC7,𮯇
U+2EBC8,𮯈
U+2EBCB,𮯋
U+2EBCC,𮯌
U+2EBCE,𮯎
U+313A4,𱎤
U+318C3,𱣃
U+318E8,𱣨
U+31DE5,𱷥
U+31E22,𱸢
U+31EE2,𱻢
U+31F50,𱽐
U+322C4,𲋄
U+322C7,𲋇
U+322C8,𲋈
U+322CB,𲋋
U+323AC,𲎬
U+323AD,𲎭
U+3267E,
U+32A83,
U+32C47,
U+332CF,
U+332D0,
U+33472,
U+33477,
U+33478,
U+33479,
繁简部首
乛/乙(亅) 艹/艸 丬/爿 门/門 辶/辵 飞/飛 马/馬
王/玉 韦/韋 车/車 贝/貝 见/見 长/長 风/風 户/戶
龙/龍 鸟/鳥 覀/襾 页/頁 齐/齊 麦/麥 卤/鹵 龟/龜
青/靑 齿/齒 黾/黽 鱼/魚 黄/黃
2025.06.29更新:
更新css和mdd,
使得电脑dictango(一样的css和mdd,pc端的欧陆无法显示字体,dictango无法显示正确的排版)
手机安卓欧陆,dictango,MDict,能够显示全部的Unicode16汉字,
使用字体:
GitHub - takushun-wu/WenJinMincho: 可免费商用的大字符集宋体字库,以OFL协议发布。/A large character set fonts in Songti(Mincho) style. Licensed under the SIL OFL 1.1.
![]()
网页显示四个方框,
电脑dictango完美显示,图片未加载是因为,5位数字.png已在mdx中预留好了位置,但是png还没有提取,约有空缺98682-93981=4701

![D80@7X1$GO6W141EWKKGXG|690x388]
手机端:
数据来自Unicode官网,
完整收录目前最新Unicode16中的98682个汉字,
三种查询方式,字头,Unicode数字代码(不满5位的首位补0),Unicode代码
㐀,03400,U+3400
部首笔画按照官网214个部首已整理
214个部首
"1": "一",
“2”: “丨”,
“3”: “丶”,
“4”: “丿”,
“5”: “乙”,
“6”: “亅”,
“7”: “二”,
“8”: “亠”,
“9”: “人”,
“10”: “儿”,
“11”: “入”,
“12”: “八”,
“13”: “冂”,
“14”: “冖”,
“15”: “冫”,
“16”: “几”,
“17”: “凵”,
“18”: “刀”,
“19”: “力”,
“20”: “勹”,
“21”: “匕”,
“22”: “匚”,
“23”: “匸”,
“24”: “十”,
“25”: “卜”,
“26”: “卩”,
“27”: “厂”,
“28”: “厶”,
“29”: “又”,
“30”: “口”,
“31”: “囗”,
“32”: “土”,
“33”: “士”,
“34”: “夂”,
“35”: “夊”,
“36”: “夕”,
“37”: “大”,
“38”: “女”,
“39”: “子”,
“40”: “宀”,
“41”: “寸”,
“42”: “小”,
“43”: “尢”,
“44”: “尸”,
“45”: “屮”,
“46”: “山”,
“47”: “巛”,
“48”: “工”,
“49”: “己”,
“50”: “巾”,
“51”: “干”,
“52”: “幺”,
“53”: “广”,
“54”: “廴”,
“55”: “廾”,
“56”: “弋”,
“57”: “弓”,
“58”: “彐”,
“59”: “彡”,
“60”: “彳”,
“61”: “心”,
“62”: “戈”,
“63”: “戶”,
“64”: “手”,
“65”: “支”,
“66”: “攴”,
“67”: “文”,
“68”: “斗”,
“69”: “斤”,
“70”: “方”,
“71”: “无”,
“72”: “日”,
“73”: “曰”,
“74”: “月”,
“75”: “木”,
“76”: “欠”,
“77”: “止”,
“78”: “歹”,
“79”: “殳”,
“80”: “毋”,
“81”: “比”,
“82”: “毛”,
“83”: “氏”,
“84”: “气”,
“85”: “水”,
“86”: “火”,
“87”: “爪”,
“88”: “父”,
“89”: “爻”,
“90”: “爿”,
“91”: “片”,
“92”: “牙”,
“93”: “牛”,
“94”: “犬”,
“95”: “玄”,
“96”: “玉”,
“97”: “瓜”,
“98”: “瓦”,
“99”: “甘”,
“100”: “生”,
“101”: “用”,
“102”: “田”,
“103”: “疋”,
“104”: “疒”,
“105”: “癶”,
“106”: “白”,
“107”: “皮”,
“108”: “皿”,
“109”: “目”,
“110”: “矛”,
“111”: “矢”,
“112”: “石”,
“113”: “示”,
“114”: “禸”,
“115”: “禾”,
“116”: “穴”,
“117”: “立”,
“118”: “竹”,
“119”: “米”,
“120”: “糸”,
“121”: “缶”,
“122”: “网”,
“123”: “羊”,
“124”: “羽”,
“125”: “老”,
“126”: “而”,
“127”: “耒”,
“128”: “耳”,
“129”: “聿”,
“130”: “肉”,
“131”: “臣”,
“132”: “自”,
“133”: “至”,
“134”: “臼”,
“135”: “舌”,
“136”: “舛”,
“137”: “舟”,
“138”: “艮”,
“139”: “色”,
“140”: “艸”,
“141”: “虍”,
“142”: “虫”,
“143”: “血”,
“144”: “行”,
“145”: “衣”,
“146”: “襾”,
“147”: “見”,
“148”: “角”,
“149”: “言”,
“150”: “谷”,
“151”: “豆”,
“152”: “豕”,
“153”: “豸”,
“154”: “貝”,
“155”: “赤”,
“156”: “走”,
“157”: “足”,
“158”: “身”,
“159”: “車”,
“160”: “辛”,
“161”: “辰”,
“162”: “辵”,
“163”: “邑”,
“164”: “酉”,
“165”: “采”,
“166”: “里”,
“167”: “金”,
“168”: “長”,
“169”: “門”,
“170”: “阜”,
“171”: “隶”,
“172”: “隹”,
“173”: “雨”,
“174”: “青”,
“175”: “非”,
“176”: “面”,
“177”: “革”,
“178”: “韋”,
“179”: “韭”,
“180”: “音”,
“181”: “頁”,
“182”: “風”,
“183”: “飛”,
“184”: “食”,
“185”: “首”,
“186”: “香”,
“187”: “馬”,
“188”: “骨”,
“189”: “髙”,
“190”: “髟”,
“191”: “鬥”,
“192”: “鬯”,
“193”: “鬲”,
“194”: “鬼”,
“195”: “魚”,
“196”: “鳥”,
“197”: “鹵”,
“198”: “鹿”,
“199”: “麥”,
“200”: “麻”,
“201”: “黃”,
“202”: “黍”,
“203”: “黑”,
“204”: “黹”,
“205”: “黽”,
“206”: “鼎”,
“207”: “鼓”,
“208”: “鼠”,
“209”: “鼻”,
“210”: “齊”,
“211”: “齒”,
“212”: “龍”,
“213”: “龜”,
“214”: “龠”,
官网8个txt的内容
8个txt及其具体内容
1. Unihan_IRGSources.txt
文件描述:包含汉字在各国或地区编码标准中的映射关系,以及部首笔画等信息。
关键字段:
kCompatibilityVariant:兼容变体(通常指在Unicode中为兼容其他标准而编码的字符)kIICore:IICore(一个紧凑的汉字子集,用于国际交换)kIRG_GSource:中国大陆的源映射(如GB系列的编码)kIRG_HSource:中国香港的源映射kIRG_JSource:日本的源映射(如JIS编码)kIRG_KPSource:朝鲜的源映射(KPS标准)kIRG_KSource:韩国的源映射(KS标准)kIRG_MSource:蒙古的源映射kIRG_SSource:新加坡的源映射kIRG_TSource:中国台湾的源映射(如Big5)kIRG_UKSource:英国的源映射(很少使用)kIRG_USource:美国的源映射(如Hanyu-Da Zidian)kIRG_VSource:越南的源映射kRSUnicode:Unicode部首笔画(部首和剩余笔画数,格式如“149.4”表示部首149,剩余4画)kTotalStrokes:总笔画数
2. Unihan_DictionaryIndices.txt
文件描述:包含各种字典索引信息,这些索引指向不同字典中的位置。
关键字段:
kCheungBauerIndex:张群显-白瑞德(Cheung-Bauer)索引(《漢語多功能字庫》)kCihaiT:《辞海》的页码(传统版)kCowles:Cowles索引(《A Chinese and English Dictionary》)kDaeJaweon:大字典(Dae Jaweon)的页码(韩国的一部字典)kFennIndex:Fenn索引(《Fenn’s Chinese-English Pocket Dictionary》)kGSR:Karlgren’s Grammata Serica Recensa(高本汉的《汉文典》修订本)的编号kHanYu:《汉语大字典》的页码和位置(格式为“卷号.页码.位置”)kIRGDaeJaweon:IRG(表意文字小组)统一的大字典页码kIRGHanyuDaZidian:IRG统一的《汉语大字典》位置kIRGKangXi:IRG统一的《康熙字典》页码kKangXi:《康熙字典》的页码和位置(格式为“页码.位置”)kKarlgren:高本汉(Bernhard Karlgren)的索引(《Analytic Dictionary of Chinese and Sino-Japanese》)kLau:Lau索引(《A Practical Chinese-English Dictionary》)kMatthews:Matthews索引(《Mathews’ Chinese-English Dictionary》)kMeyerWempe:Meyer-Wempe索引(《The Student’s Chinese-English Dictionary》)kMorohashi:《大汉和辞典》的索引(Morohashi)kNelson:《Nelson’s Japanese-English Character Dictionary》的索引kSBGY:《宋本广韵》(Song Ben Guang Yun)的页码和位置kSMSZD2003Index:《现代汉语规范词典》(2003)的索引
3. Unihan_Readings.txt
文件描述:包含汉字的读音(拼音、注音、粤语、日语、韩语、越南语等)和定义。
关键字段:
kCantonese:粤语拼音(常用罗马化表示)kDefinition:英文定义kFanqie:反切(古代注音方法)kHangul:韩语发音(韩文)kHanyuPinlu:汉语拼音频率(来自《现代汉语频率词典》)kHanyuPinyin:《汉语大字典》中的拼音(多音字会有多个拼音)kJapanese:日语发音(罗马字,包括音读和训读的混合)kJapaneseKun:日语训读kJapaneseOn:日语音读kKorean:韩语罗马字发音kMandarin:普通话拼音(最常用的拼音)kSMSZD2003Readings:《现代汉语规范词典》(2003)的拼音kTang:中古汉语发音(唐朝发音,重构)kTGHZ2013:《通用规范汉字表》(2013)的拼音kVietnamese:越南语发音(汉越音)kXHC1983:《现代汉语词典》(1983)的拼音kZhuang:壮语发音(用拉丁字母表示)
4. Unihan_DictionaryLikeData.txt
文件描述:包含字典类型的数据,如字形结构、四角号码、仓颉码等。
关键字段:
kAlternateTotalStrokes:替代总笔画数(当存在多个写法时)kCangjie:仓颉输入法编码kCheungBauer:张群显-白瑞德(Cheung-Bauer)的编码和位置kFenn:Fenn编码(Fenn’s Chinese-English Pocket Dictionary)kFourCornerCode:四角号码kGradeLevel:汉字的学习等级(常用于教育,如日本的小学汉字等级)kHDZRadBreak:《汉语大字典》的部首和拆分kHKGlyph:香港字形(香港增补字符集的字形描述)kMojiJoho:文字情报(Moji Joho)的编码(日本)kPhonetic:音标(通常为其他注音系统)kStrange:特殊标记(用于标记特殊字形)kUnihanCore2020:Unihan核心2020(一个汉字子集)
5. Unihan_OtherMappings.txt
文件描述:包含其他编码标准的映射,如Big5、GB、CNS、电报码等。
关键字段:
kBigFive:Big5编码(台湾繁体字编码)kCCCII:CCCII编码(中文资讯交换码)kCNS1986:CNS 11643-1986(台湾标准交换码)kCNS1992:CNS 11643-1992(台湾标准交换码)kEACC:EACC(东亚字符编码,ANSI Z39.64)kGB0:GB2312-80编码(区位码)kGB1:GB/T 12345-90(繁体字集)kGB3:GB7589-87(简体字集)kGB5:GB7590-87(简体字集)kGB7:GB/T 8565.2-1988(用于信息处理)kGB8:GB/T 8565.3-1988(用于信息处理)kIBMJapan:IBM日本使用的编码kJa:日本工业标准(JIS)编码(旧版本)kJinmeiyoKanji:日本人名用汉字(JIS X 0213)kJis0:JIS X 0208-1983kJis1:JIS X 0212-1990kJIS0213:JIS X 0213:2000kJoyoKanji:日本常用汉字(教育用)kKoreanEducationHanja:韩国教育用汉字kKoreanName:韩国人名用汉字kMainlandTelegraph:中国大陆电报码kPseudoGB1:伪GB1(非标准映射)kTaiwanTelegraph:台湾电报码kTGH:《通用规范汉字表》的编号kXerox:施乐公司使用的编码
6. Unihan_Variants.txt
文件描述:包含汉字的变体关系(如简体、繁体、异体等)。
关键字段:
kSemanticVariant:语义变体(意义相同但写法不同的字)kSimplifiedVariant:简体变体(对应的简体字)kSpecializedSemanticVariant:专业语义变体(在特定领域意义相同)kSpoofingVariant:欺骗性变体(易混淆的字)kTraditionalVariant:繁体变体(对应的繁体字)kZVariant:字形变体(字形不同但可视为相同)
7. Unihan_RadicalStrokeCounts.txt
文件描述:包含部首和笔画数信息(主要针对Adobe-Japan1-6标准)。
关键字段:
kRSAdobe_Japan1_6:Adobe-Japan1-6标准中的部首笔画(格式:部首+剩余笔画,可能包含多个,用空格分隔)
8. Unihan_NumericValues.txt
文件描述:包含汉字的数字含义(用于表示数字的汉字)。
关键字段:
kAccountingNumeric:会计数字(大写数字,如壹、贰)kOtherNumeric:其他数字(如干支、特殊计数)kPrimaryNumeric:基本数字(一、二、三……)kVietnameseNumeric:越南语中的数字kZhuangNumeric:壮语中的数字
词典界面翻译,
100种属性
"字符": "字符",
"兼容变体": "兼容变体",
"国际表意文字核心子集(IICore)": "IICore",
"中国大陆源": "中国大陆源",
"中国香港源": "中国香港源",
"日本源": "日本源",
"朝鲜源": "朝鲜源",
"韩国源": "韩国源",
"蒙古源": "蒙古源",
"新加坡源": "新加坡源",
"中国台湾源": "中国台湾源",
"英国源": "英国源",
"美国源": "美国源",
"越南源": "越南源",
"Unicode部首笔画": "部首笔画",
"总笔画数": "总笔画数",
"张群显-白瑞德索引(香港中文大学汉字数据库索引)": "张群显-白瑞德索引",
"辞海(繁体版)": "辞海",
"Cowles索引": "Cowles索引",
"韩语大字典(Dae Jaweon)页码": "韩语大字典",
"Fenn索引": "Fenn索引",
"高本汉《汉文典》(Grammata Serica Recensa)": "高本汉《汉文典》",
"汉语大字典": "汉语大字典",
"IRG韩语大字典": "IRG韩语大字典",
"IRG汉语大字典": "IRG汉语大字典",
"IRG康熙字典": "IRG康熙字典",
"康熙字典": "康熙字典",
"高本汉索引": "高本汉索引",
"Lau索引": "Lau索引",
"Matthews索引": "Matthews索引",
"Meyer-Wempe索引": "Meyer-Wempe索引",
"日本《大汉和辞典》(Morohashi)": "大汉和辞典",
"Nelson索引": "Nelson索引",
"《宋本广韵》(韵书)": "宋本广韵",
"《现代汉语规范字典》(2003年版)": "现代汉语规范字典",
"粤语拼音": "粤语拼音",
"英文定义": "英文定义",
"反切": "反切",
"韩语发音": "韩语发音",
"拼音频率": "拼音频率",
"汉语拼音": "汉语拼音",
"日语发音": "日语发音",
"日语训读": "日语训读",
"日语音读": "日语音读",
"韩语罗马字": "韩语罗马字",
"普通话拼音": "普通话拼音",
"《现代汉语规范字典》(2003年版)拼音": "现代汉语规范字典拼音",
"中古汉语": "中古汉语",
"《通用规范汉字表》(2013年版)": "通用规范汉字表",
"越南语发音": "越南语发音",
"《现代汉语词典》(1983年版)": "现代汉语词典",
"壮语发音": "壮语发音",
"替代笔画数": "替代笔画数",
"仓颉编码": "仓颉编码",
"张群显-白瑞德的研究数据": "张群显-白瑞德数据",
"Fenn编码": "Fenn编码",
"四角号码": "四角号码",
"学习等级": "学习等级",
"《汉语大字典》部首拆分": "汉语大字典部首拆分",
"香港字形": "香港字形",
"日本文字情报数据库(Moji Joho Kiban)": "日本文字情报数据库",
"音标": "音标",
"特殊标记": "特殊标记",
"2020年版的Unihan核心字符集": "Unihan核心2020",
"Big5编码": "Big5编码",
"CCCII编码": "CCCII编码",
"CNS1986": "CNS1986",
"CNS1992": "CNS1992",
"EACC编码": "EACC编码",
"GB2312-80": "GB2312",
"GB/T12345-90": "GB12345",
"GB7589-87": "GB7589",
"GB7590-87": "GB7590",
"GB/T8565.2-1988": "GB8565-2",
"GB/T8565.3-1988": "GB8565-3",
"IBM日本": "IBM日本",
"日本工业标准": "日本工业标准",
"日本人名用汉字": "日本人名用汉字",
"JIS X0208-1983": "JIS X0208",
"JIS X0212-1990": "JIS X0212",
"JIS X0213:2000": "JIS X0213",
"日本常用汉字": "日本常用汉字",
"韩国教育用汉字": "韩国教育用汉字",
"韩国人名用汉字": "韩国人名用汉字",
"大陆电报码": "大陆电报码",
"伪GB1": "伪GB1",
"台湾电报码": "台湾电报码",
"《通用规范汉字表》编号": "通用规范汉字表编号",
"施乐编码": "施乐编码",
"语义变体": "语义变体",
"简体变体": "简体变体",
"专业语义变体": "专业语义变体",
"欺骗性变体": "欺骗性变体",
"繁体变体": "繁体变体",
"字形变体": "字形变体",
"Adobe Japan1-6字符部首笔画": "Adobe部首笔画",
"会计数字": "会计数字",
"其他数字": "其他数字",
"基本数字": "基本数字",
"越南语数字": "越南语数字",
"壮语数字": "壮语数字"
已经预留好同名css和js的开头,效果如图
支持变体跳转,图片93981张,来自電腦漢字字典
如果能从pdf中补齐图片就更好了,
同样的css在欧陆中和tango中显示不一样,我无能为力,
数据全收录,无修改,未删节,仅供参考,仅供网络带宽下载测试,
17
链接:百度网盘 请输入提取码
提取码:kkkk
旧版16懒得删
98682/102998个字头和对应的码点,
98682.txt (1.3 MB)
Unicode17新增.txt (59.0 KB)
102998.txt (877.9 KB)