更新2025.9.19
简单更新,Unicode17,102998字,单色版mdx,采用Unicode部首检索,
同样手机上点击自动跳转,电脑上点击自动复制汉字
手机适用欧路,tango,MDict,(无限词典会闪退)电脑适用tango
历史更新
更新2025.7.15
新版pc的tango升级之后,效率大大升级,使得mdx版得以实现,仅在pc端tango通过,点击汉字自动复制
感觉对Unicode的部首分类和国学大师的部首分类不是很满意,有没有更好的部首和拼音检索方案,求指点,下一版想整合进来,有思路了,但是没方案
更新
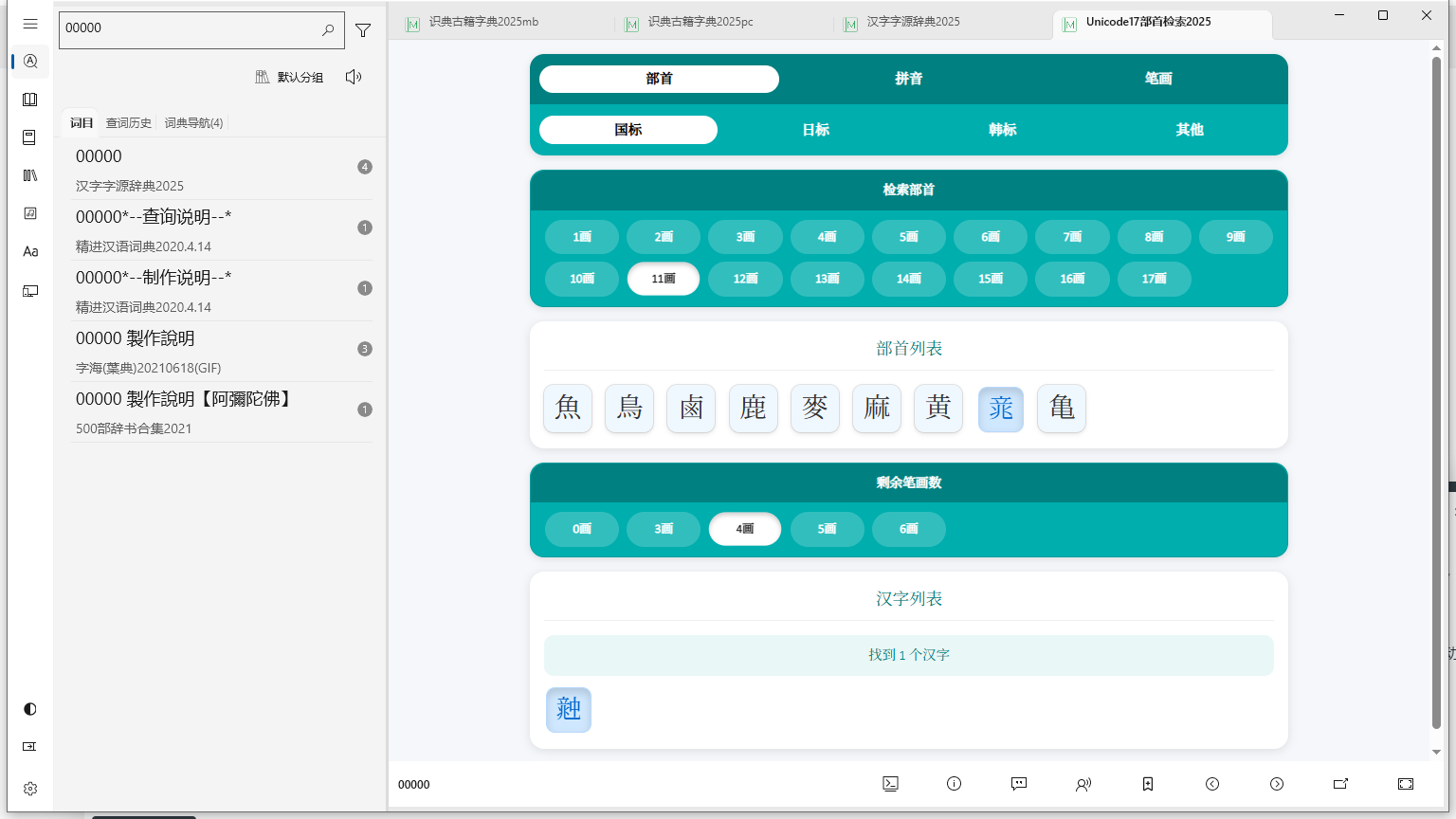
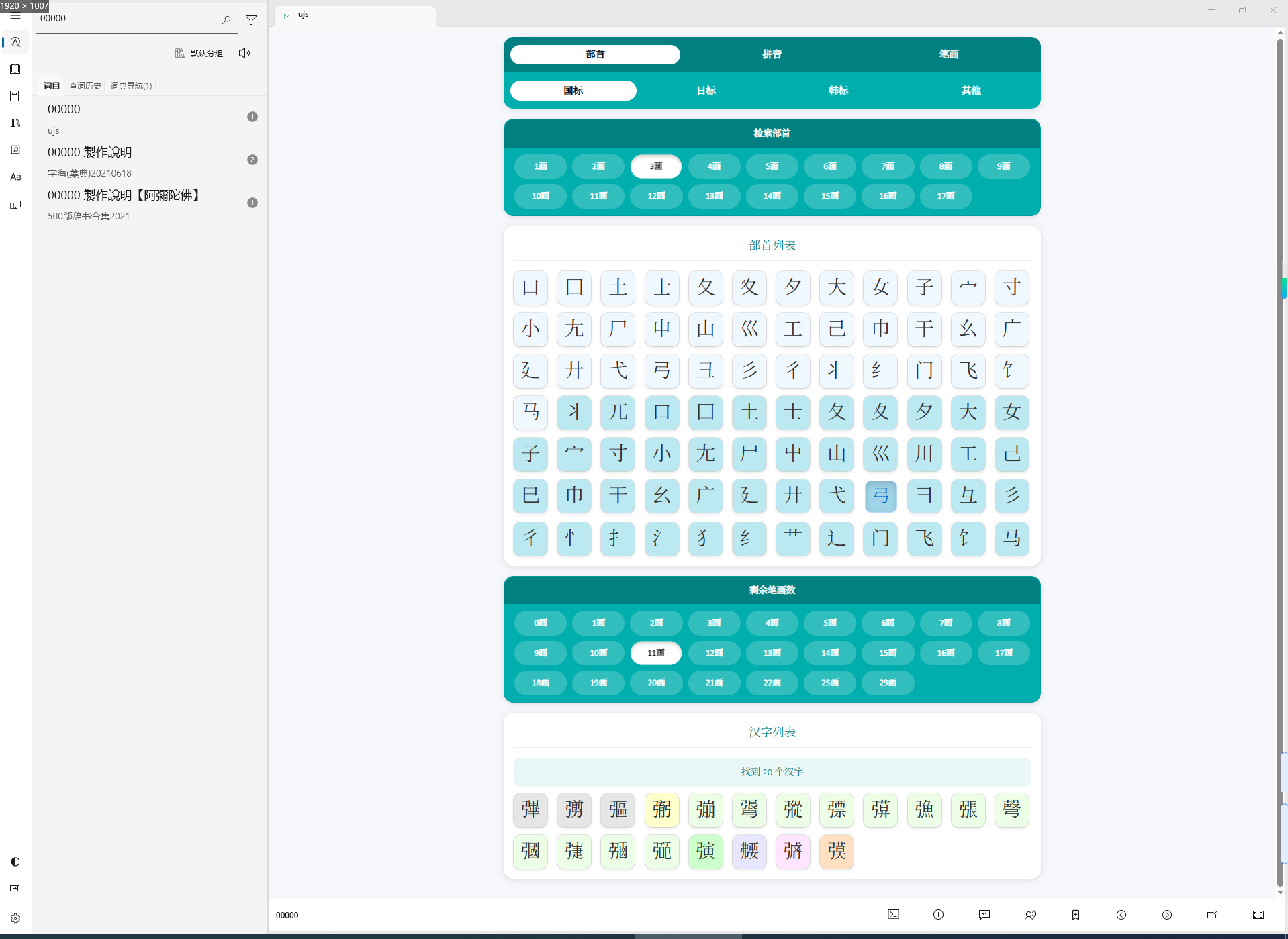
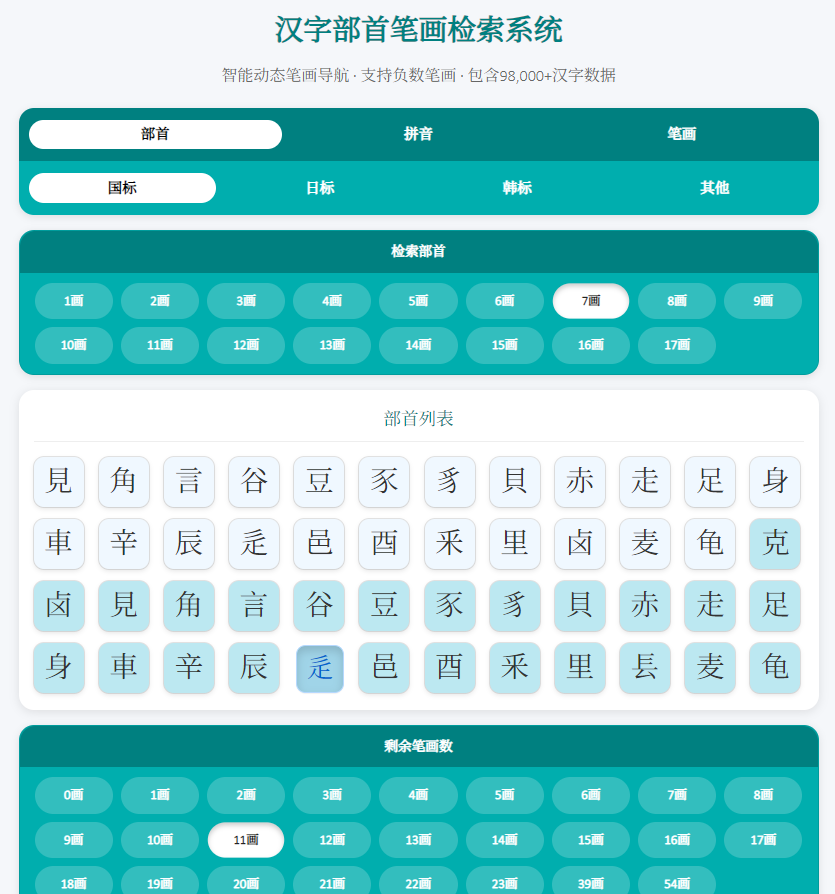
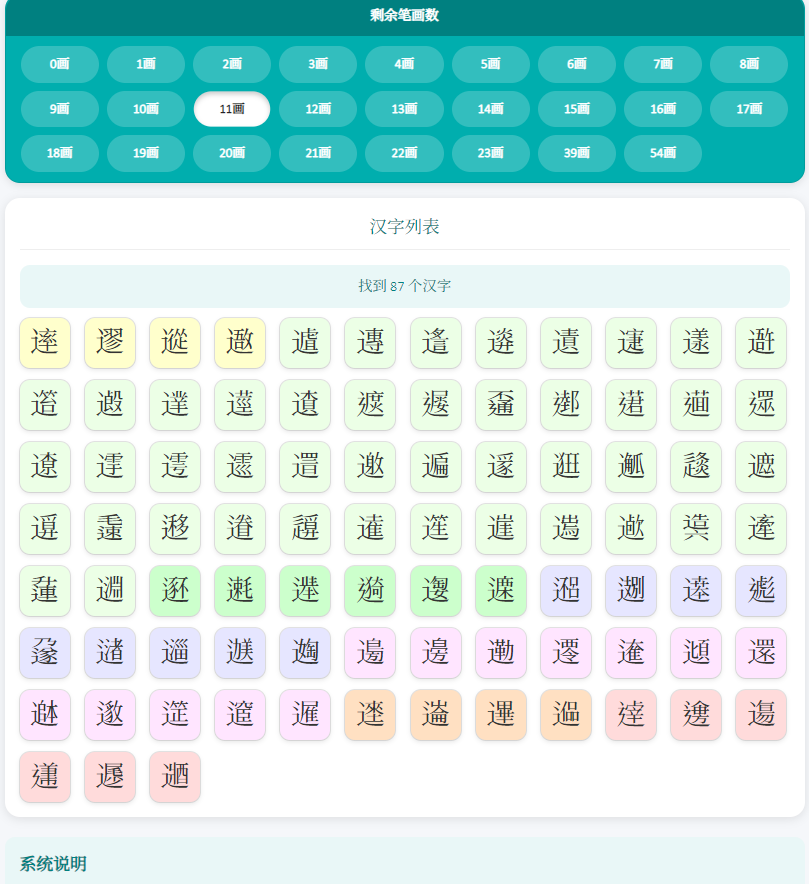
添加新的部首检索路径,部首深色色显示,来自国学大师部首方案,浅色为Unicode部首方案不变
高仿部件检索的异色区分扩展区,点击汉字自动复制
手机版的炸膛了,这个版本先不发了,等修复先,
下一步想从本义国标词典中提取拼音检索,但是不全,只有8.7w字的拼音,要是能从搜狗输入法中提取拼音就好了,随便抽的几个字都有拼音,出欠𠎤𲎯,𠎤昌𱍊,越南鼓风机 𫖽,有大佬会从搜狗输入法中导出拼音的数据吗
自从发现unihan.zip这个大宝藏,就拿着这98682个字头到处套,
分别套出了
更新:《Unicode汉字字典》完整收录并显示Unicode17正式版102998个汉字
【国学大师字典】2025.7.6
一直眼馋论坛完美版完美版的词典切换功能,最近又看到袖珍本袖珍本单页面检索6w字的神奇
加上unihan自带的部首笔画,直接“三张压成一张”

Unihan的部首笔画分类全保留,
无论是两种部首分法还是三种部首分法,
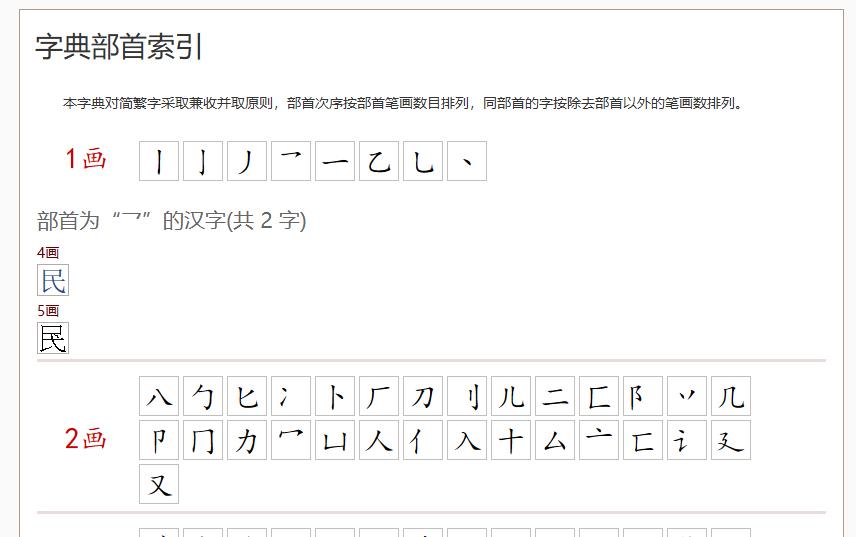
214个康熙部首,简体部首,变体部首,全保留,部首用部首字形展示,(除了三个没有部首字形的用同形字展示)
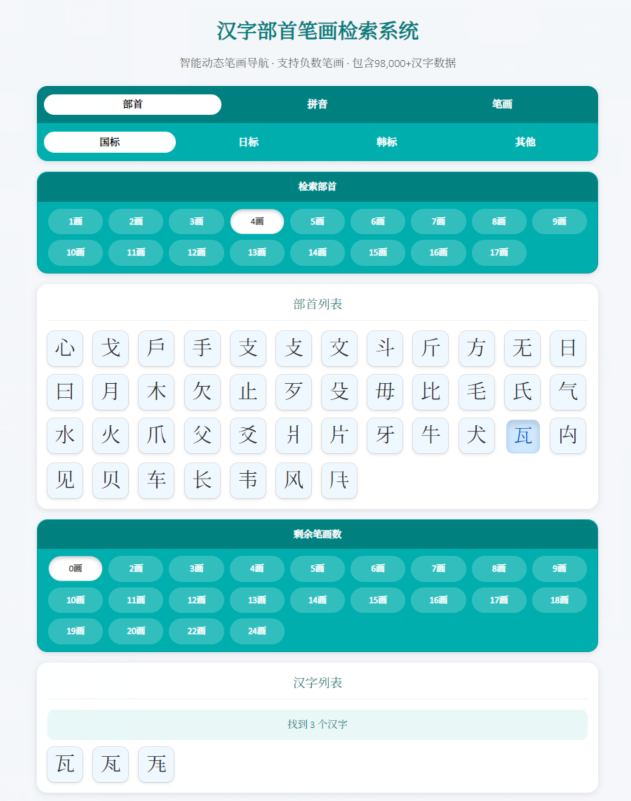
部首既保留康熙字典的原始笔数,也增添现代笔画数,例如“瓦”,康熙部首为5画,现代部首为4画,类似的还有
“⽡”“⾻”“⿁”“⿍”“⿔”
感谢 jcz777的指点
序号;部首;同形字.及笔画数有差异的部首,上康熙笔画数下现代笔画数
1; ⼀; 一 2; ⼁; 丨 3; ⼂; 丶 4; ⼃; 丿 5; ⼄; 乙 6; ⼅; 亅 7; ⼆; 二 8; ⼇; 亠 9; ⼈; 人 10; ⼉; 儿 11; ⼊; 入 12; ⼋; 八 13; ⼌; 冂 14; ⼍; 冖 15; ⼎; 冫 16; ⼏; 几 17; ⼐; 凵 18; ⼑; 刀 19; ⼒; 力 20; ⼓; 勹 21; ⼔; 匕 22; ⼕; 匚 23; ⼖; 匸 24; ⼗; 十 25; ⼘; 卜 26; ⼙; 卩 27; ⼚; 厂 28; ⼛; 厶 29; ⼜; 又 30; ⼝; 口 31; ⼞; 囗 32; ⼟; 土 33; ⼠; 士 34; ⼡; 夂 35; ⼢; 夊 36; ⼣; 夕 37; ⼤; 大 38; ⼥; 女 39; ⼦; 子 40; ⼧; 宀 41; ⼨; 寸 42; ⼩; 小 43; ⼪; 尢 44; ⼫; 尸 45; ⼬; 屮 46; ⼭; 山 47; ⼮; 巛 48; ⼯; 工 49; ⼰; 己 50; ⼱; 巾 51; ⼲; 干 52; ⼳; 幺 53; ⼴; 广 54; ⼵; 廴 55; ⼶; 廾 56; ⼷; 弋 57; ⼸; 弓 58; ⼹; 彐 59; ⼺; 彡 60; ⼻; 彳 61; ⼼; 心 62; ⼽; 戈 63; ⼾; 戶 64; ⼿; 手 65; ⽀; 支 66; ⽁; 攴 67; ⽂; 文 68; ⽃; 斗 69; ⽄; 斤 70; ⽅; 方 71; ⽆; 无 72; ⽇; 日 73; ⽈; 曰 74; ⽉; 月 75; ⽊; 木 76; ⽋; 欠 77; ⽌; 止 78; ⽍; 歹 79; ⽎; 殳 80; ⽏; 毋 81; ⽐; 比 82; ⽑; 毛 83; ⽒; 氏 84; ⽓; 气 85; ⽔; 水 86; ⽕; 火 87; ⽖; 爪 88; ⽗; 父 89; ⽘; 爻 90; ⽙; 爿 90'; ⺦; 丬 91; ⽚; 片 92; ⽛; 牙 93; ⽜; 牛 94; ⽝; 犬 95; ⽞; 玄 96; ⽟; 玉 97; ⽠; 瓜 98; ⽡; 瓦 99; ⽢; 甘 100; ⽣; 生 101; ⽤; 用 102; ⽥; 田 103; ⽦; 疋 104; ⽧; 疒 105; ⽨; 癶 106; ⽩; 白 107; ⽪; 皮 108; ⽫; 皿 109; ⽬; 目 110; ⽭; 矛 111; ⽮; 矢 112; ⽯; 石 113; ⽰; 示 114; ⽱; 禸 115; ⽲; 禾 116; ⽳; 穴 117; ⽴; 立 118; ⽵; 竹 119; ⽶; 米 120; ⽷; 糸 120'; ⺰; 纟 121; ⽸; 缶 122; ⽹; 网 123; ⽺; 羊 124; ⽻; 羽 125; ⽼; 老 126; ⽽; 而 127; ⽾; 耒 128; ⽿; 耳 129; ⾀; 聿 130; ⾁; 肉 131; ⾂; 臣 132; ⾃; 自 133; ⾄; 至 134; ⾅; 臼 135; ⾆; 舌 136; ⾇; 舛 137; ⾈; 舟 138; ⾉; 艮 139; ⾊; 色 140; ⾋; 艸 141; ⾌; 虍 142; ⾍; 虫 143; ⾎; 血 144; ⾏; 行 145; ⾐; 衣 146; ⾑; 襾 147; ⾒; 見 147'; ⻅; 见 148; ⾓; 角 149; ⾔; 言 149'; ⻈; 讠 150; ⾕; 谷 151; ⾖; 豆 152; ⾗; 豕 153; ⾘; 豸 154; ⾙; 貝 154'; ⻉; 贝 155; ⾚; 赤 156; ⾛; 走 157; ⾜; 足 158; ⾝; 身 159; ⾞; 車 159'; ⻋; 车 160; ⾟; 辛 161; ⾠; 辰 162; ⾡; 辵 163; ⾢; 邑 164; ⾣; 酉 165; ⾤; 釆 166; ⾥; 里 167; ⾦; 金 167'; ⻐; 钅 168; ⾧; 長 168'; ⻓; 长 169; ⾨; 門 169'; ⻔; 门 170; ⾩; 阜 171; ⾪; 隶 172; ⾫; 隹 173; ⾬; 雨 174; ⾭; 靑 175; ⾮; 非 176; ⾯; 面 177; ⾰; 革 178; ⾱; 韋 178'; ⻙; 韦 179; ⾲; 韭 180; ⾳; 音 181; ⾴; 頁 181'; ⻚; 页 182; ⾵; 風 182'; ⻛; 风 182''; ; 𲋄 183; ⾶; 飛 183'; ⻜; 飞 184; ⾷; 食 184'; ⻠; 饣 185; ⾸; 首 186; ⾹; 香 187; ⾺; 馬 187'; ⻢; 马 188; ⾻; 骨 189; ⾼; 高 190; ⾽; 髟 191; ⾾; 鬥 192; ⾿; 鬯 193; ⿀; 鬲 194; ⿁; 鬼 195; ⿂; 魚 195'; ⻥; 鱼 196; ⿃; 鳥 196'; ⻦; 鸟 197; ⿄; 鹵 197'; ⻧; 卤 198; ⿅; 鹿 199; ⿆; 麥 199'; ⻨; 麦 200; ⿇; 麻 201; ⿈; 黃 201'; ⻩; 黄 202; ⿉; 黍 203; ⿊; 黑 204; ⿋; 黹 205; ⿌; 黽 205'; ⻪; 黾 206; ⿍; 鼎 207; ⿎; 鼓 208; ⿏; 鼠 208''; ; 鼡 209; ⿐; 鼻 210; ⿑; 齊 210'; ⻬; 齐 210''; ⻫; 斉 211; ⿒; 齒 211'; ⻮; 齿 211''; ⻭; 歯 212; ⿓; 龍 212'; ⻰; 龙 212''; ⻯; 竜 212'''; ; 𱷥 213; ⿔; 龜 213'; ⻳; 龟 213''; ⻲; 亀 214; ⿕; 龠 <span data-id="98" data-stroke="5" data-char="⽡"></span> <span data-id="98" data-stroke="4" data-char="⽡"></span> <span data-id="188" data-stroke="10" data-char="⾻"></span> <span data-id="188" data-stroke="9" data-char="⾻"></span> <span data-id="194" data-stroke="10" data-char="⿁"></span> <span data-id="194" data-stroke="9" data-char="⿁"></span> <span data-id="206" data-stroke="13" data-char="⿍"></span> <span data-id="206" data-stroke="12" data-char="⿍"></span> <span data-id="213" data-stroke="16" data-char="⿔"></span> <span data-id="213" data-stroke="17" data-char="⿔"></span>
部首检索可用,拼音,笔画仅为占位,本来想用本B義Y國G標B字Z典D作为拼音检索的,连越南鼓风机 汉词宝𫖽都有类推拼音,但是好像这个词典编写的评价不高,小程序都无响应了,所以作罢
暂时都归类为国标,日标韩标仅为占位,以后也许用不同的字体或者色块来区分,
网页版点击直接复制字头
手机版点击直接跳转(仅手机欧路测试通过)
网页底部的系统说明为电脑AI自动生成的吹嘘,与作者无关 ![]()
此文本将被隐藏
链接:https://pan.baidu.com/s/1OA1vmUw0lOkKreYmbFYhMA
提取码:kkkk
Unicode16:demo6,手机版适用于欧路,demo7,mdx版适用于PC端tango
Unicode17:手机适用欧路,tango,MDict,(无限词典会闪退)电脑适用tango