感佩于各位先生在自制词典方面所做的探索,我等晚生有了宝贵的词典可用。虽然也买过词典,但有些词典若不自己做电子版,买也难得买到。所以,我正在从头开始学习制作自己的图片词典,预计时间为1~3个月。之所有选择做图片版词典,是因为想花不太多的时间解决一些词典从无到有的过程。
在此期间,我将发贴纪录一部词典制作的经过,大家可以批评指导我的过程与方法。期间,我可能要尝试写一点代码,来辅助这个工作。如果试制成功,我将把此代码和制作的一部词典开源分享。当然,我对该词典内容没有任何版权,提供出来,仅仅是为了交流词典的制作方法。另外声明一下,我已购买此词典的纸质版,制作电子版仅仅为了学习技术和方便自己使用。
需要说明的是,在我学习的过程中,发现Vim发布了极具价值的开拓性文章。我特别感觉 Vim 师所做的工作,我就是想照着他的图片词典的样子重造一个轮子。他总结了很多宝贵的经验,也分享了代码,甚至给我分享了用一本 vim 生成的文件,这样我可以节省不少时间,在学习的时候可以参照揣摩。但因为我不会用 vim,估计这辈子都难以学会,所以我选择学一门编程语言,Python。
最后,总结一下目标:从无到有,制作一个可用的图片词典数据 mdx。希望能达成!
如果有人和我一样在学习,有不明白的,请留言,我将直接扩充对应段落的文字描述。
11 个赞
第1步:扫描图片(已完工)
因为只是为了学习技术,所以没有真的亲自扫描,而是在网上下载了一本 PDF,能与我的纸质版对上。这本词典是《实用英语用法指南》(Practical English Usage),第3版。PDF是中英对照片。另外,还下载到了纯英文版的 epub, mdx。 这两个都有用, PDF 可以转出图片, epub, mdx 可以提供词头,免去我扫描的 OCR 的痛苦。但是两个词典因为版式不同,造成页码不同,所以还是需要一些人工解决一些问题,这个问题到需要处理的时候再说。
一些加工步骤:
(1) PDF 转出图片。使用的是 PDF 补丁丁这个免费软件,可以无损转出 PDF 中的图片。软件很好用,我为了表示对作者的感谢,曾捐赠过50元。不过现在起捐价提高了。
(2) 图片重命名。使用的是 Advanced Renamer,可以有很多种命名方法。
(3) 图片增强。用的是 ScanTailor。我主要是去了一下多余的白边,少量纠了一下偏。费时估计有 1~2 小时。也许可以用 ComicEnhancer 会更快一点。
以上软件都是免费的。做完这3步,就拿到了基本的原材料:可用的图片正文。
下面是所用到的PDF, 处理过的图片。一起制作的同志们可以下载原材料。https://pan.baidu.com/s/1YvdWNFYuYiiVEYQ7S_E9Eg 提取码: gyxf
正文图片:
正文之前的图片
因为我的图片转换不是一步到位的,先用 scantailor 搞成了放大版的 tif 文件,后来发现欧路不识别 tif 格式, 又用 comicenhancer 转成 png,结果数据的体积较大。这里有改进的空间。
总结:
图片的编号分两种,他们有相同的前缀(书名简写),但各自顺序编号。正文前之前的页面带一个负号,但编号长度为4位,从 -001 开始,一般指的是封面。不知道会不会留下什么坑。
1 个赞
第2步:整理词头
这步没什么难度,但很费时间,就是把词头整理出来。本来在 epub 中是有词头的,但是没有页码信息。既然不可避免,那只好硬着头皮上了。
为了使用的时间尽量少,我就直接拿条目的数字编号当成词头了。预计要好几个小时,或者要拖数周完成。
这一步用到的软件是 Excel,左边一列是词头,右边一列是页码,都是数字,所以打字输入还算不慢。关键是页码太多了。
可能会留下的问题:
本词头所记录的页码用的是书上的文字正文页码,不是图片的第多少张。后面在制作跳转时,需要注意。
上面的词头我目前只输入到100页,余下的以后再慢慢输入,我已经等不及,想看看自己能不能打包图片,并用上下页的方式浏览了。
第3步:图片打包上下页浏览
预计实现效果:制作一个只能通过上一页,下一页浏览的最没用的词典 mdx,后面在此基础上修改。
已制作完全,请稍等…
前面的都比较简单,是前几天所完成的结果,一起总结了。
方法:
(1) 将图片放在 img 文件夹;
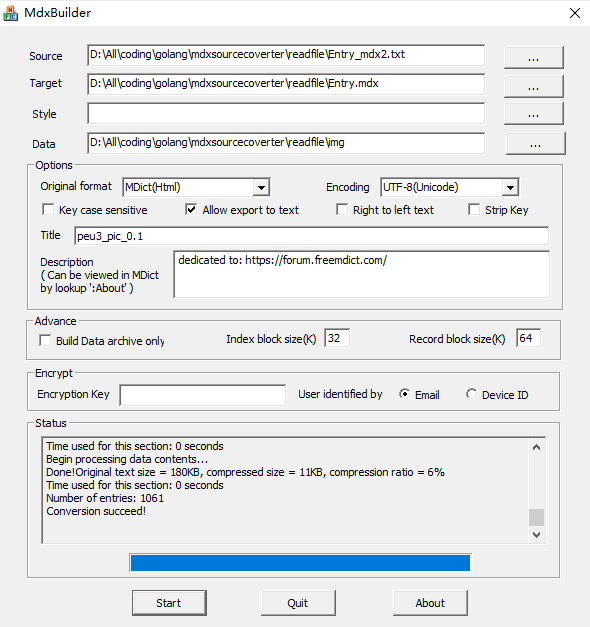
今天的成果:1个txt 文件, 1个 mdx 文件,1个 mdd 数据文件。后面这个 mdx 文件会进一步改进, mdd 数据文件将基本不变了。
链接: https://pan.baidu.com/s/1RNMRp_3ospterttzQCe73Q 提取码: jev2
总结:
(1) 图片尽量使用 png 格式,不要用 tif 格式;
2 个赞
西北风
2021 年11 月 6 日 14:10
5
smiling1384:
第3版
第4版文字版mdx都出来好几年了,还在这里折腾第3版图片版
此前误会了,不知第4版是否有翻译
2 个赞
的确如此,如果我有高质量的 第4版中英对照PDF和 英文epub/mdx,那我就从第4版开始了。
1 个赞
第4步 11-7
为前面的词典增加查词头的功能,当我输入一个数字,如 s30,它能找翻到第30条所对应的页面,不一定是第30页。
打包一个 exe 试试能不能工作。
具体工作:
# -*- coding: utf-8 -*-
import re
with open(r"Section13.xhtml", encoding="utf8") as fl_in:
text = fl_in.read()
pattern = r'<h3 class="hh\d+" id="sigil_toc_id_\d+">(\d+)(.*?)</h3>'
heads = re.findall(pattern, text)
for head in heads:
entry_id, head_word = head
head_word = re.sub('<.*?>', '', head_word).strip()
print(entry_id, head_word)
一次处理一个指定文件extract_headword.py (376 字节)
处理全部 xhtml 的版本extract_all_headwords.py (589 字节)
得到的原始结果为:
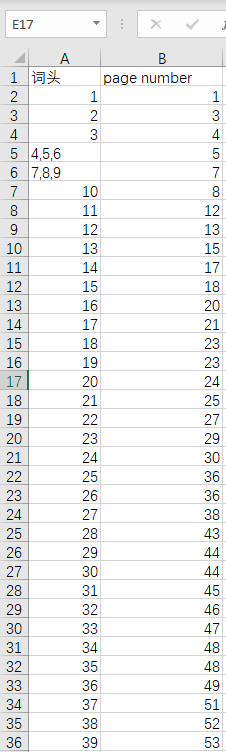
1 abbreviated styles
2 abbreviations and acronyms
3 [be] able
4 about and on
5 about to
6 above and over
7 accept and agree
8 according to
9 across, over and through
10 active verb forms
11 actual(ly)
12 adjectives (1): normal position
13 adjectives (2): after nouns and pronouns
14 adjectives (3): position after as, how, so, too
15 adjectives (4): order before nouns
...
head_word.txt (18.6 KB)
问题总结:
数字右边的词头基本都是短语,太复杂了,需要适当简化,例如展开,去括号等。主要问题是,怎么设计词头,才有最大的查得率? 大家说说经验看?
西北风:
第4版文字版mdx
那个是英文版。楼主制作的是中译本第3版,不矛盾。
从学习英语角度来说,中译本第3版完全够用。
不过楼主同时还要学习golang,感觉目标太分散了,坚持到底不易的。
我是希望找到划多条直线、一次性切割一张图片的工具,此外还希望合并图片工具希望能有顺手的。
2 个赞
不太懂,能不能解释一下,这是一个什么操作呢?
的确是有这个问题,但应该是可以坚持做出来。实在不行,中途换工具。
续 第2步 手工整理数字词头 (已完工,本回复尾部共享了文件)
硬着头皮,又花了一个小时,所有词头手工录入完毕,解决没有原材料(词头)的问题。共享录入完毕的 excel 文件,有兴趣的可以自己去改制,可以节省好几个小时的体力劳动。
词头
page number
1
1
2
3
3
4
4
5
5
5
6
5
7
7
8
7
9
7
10
8
11
12
12
13
13
15
14
17
15
18
16
20
17
21
18
23
19
23
…
practicle_english_usage3_headword_pagenumber.txt (5.4 KB)
1 个赞
第4步 续1
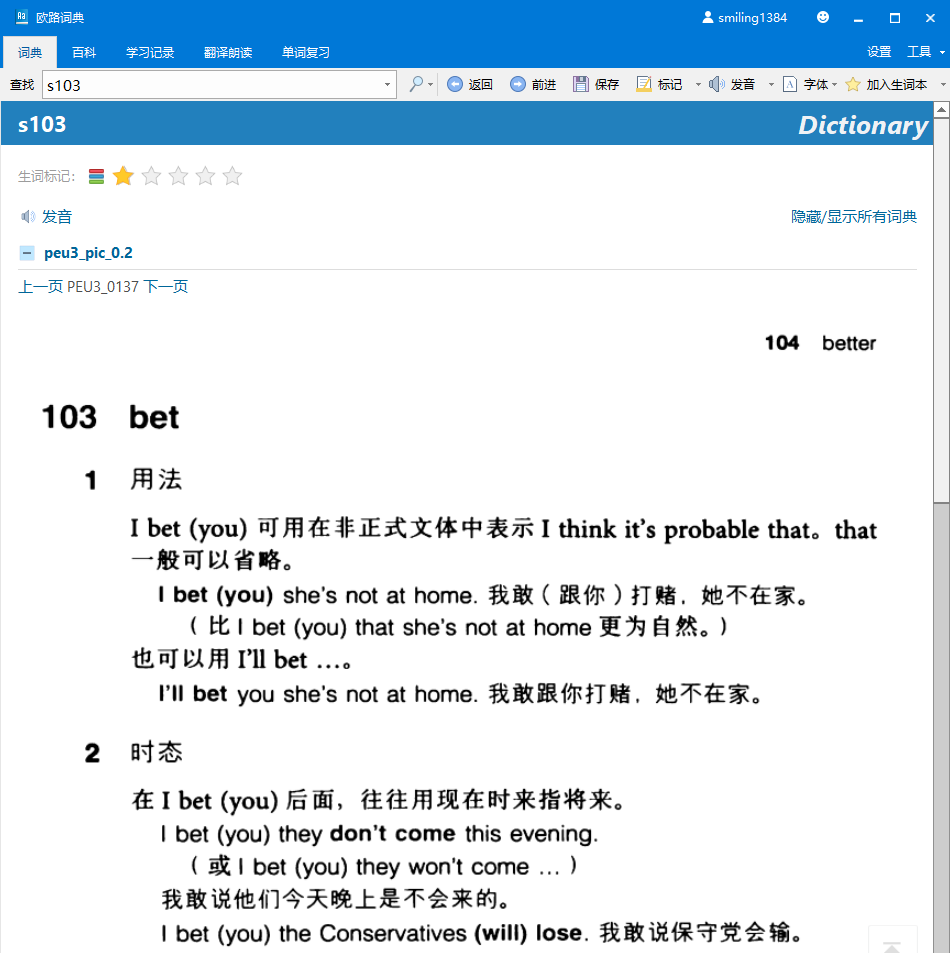
将手工整理的数字词头合并到第2步中的数据中,产生一个可以用数字编号(原词典条目编号,如输入 s103 可查得第103个词条)查词的词典。
# -*- coding: utf-8 -*-
item_tmpl = "{head}\n@@@LINK={page}\n</>\n"
with open("PEU3_headword_page.txt", encoding="utf-8") as fl_in,\
open("PEU3_headword_page_mdx.txt", "w",encoding="utf-8") as fl_out:
for kk, line in enumerate(fl_in):
if kk > 0:
line = line.strip()
entry_number, page_number = line.split("\t")
entry_number = 's' + entry_number
page_number = "PEU3_{:04d}".format(int(page_number))
item = item_tmpl.format(head=entry_number, page=page_number)
print(item)
fl_out.write(item)
为了快速出效果,暂时改用 python。因为这个程序有一定的通用性, 后期可能将这个程序改为 golang。
PEU3_headword_page_mdx.txt (18.5 KB)
将上面的跳转词条合并到 v0.1 中,即可得到一个最简单的词典,如下:
Entry_0.2.mdx (22.6 KB)
问题总结:
现在的词条只能按数字编号查询,对于该词典的阅读和跳转有一定作用,但对日常查词基本无用。下一步解决正常的查法。
第5步 将书的末尾的索引词做为词头
到了第4步的时候,实现了两种查询方法:
(2) 通过词条编号查词。因为 PEU 的语法条目带编号,正文中都是用编号跳转,所以该功能有一定的价值。这是在第4步续1实现的。
如果本词典的词头表是正常的单词,那么到这一步其实一部可用的词典已做完了。但是,这是本用法书,小标题作为词头并不方便查词。不过书尾有一个很不错的索引,大概一共有3000条,都用文字给出了跳转的条数。
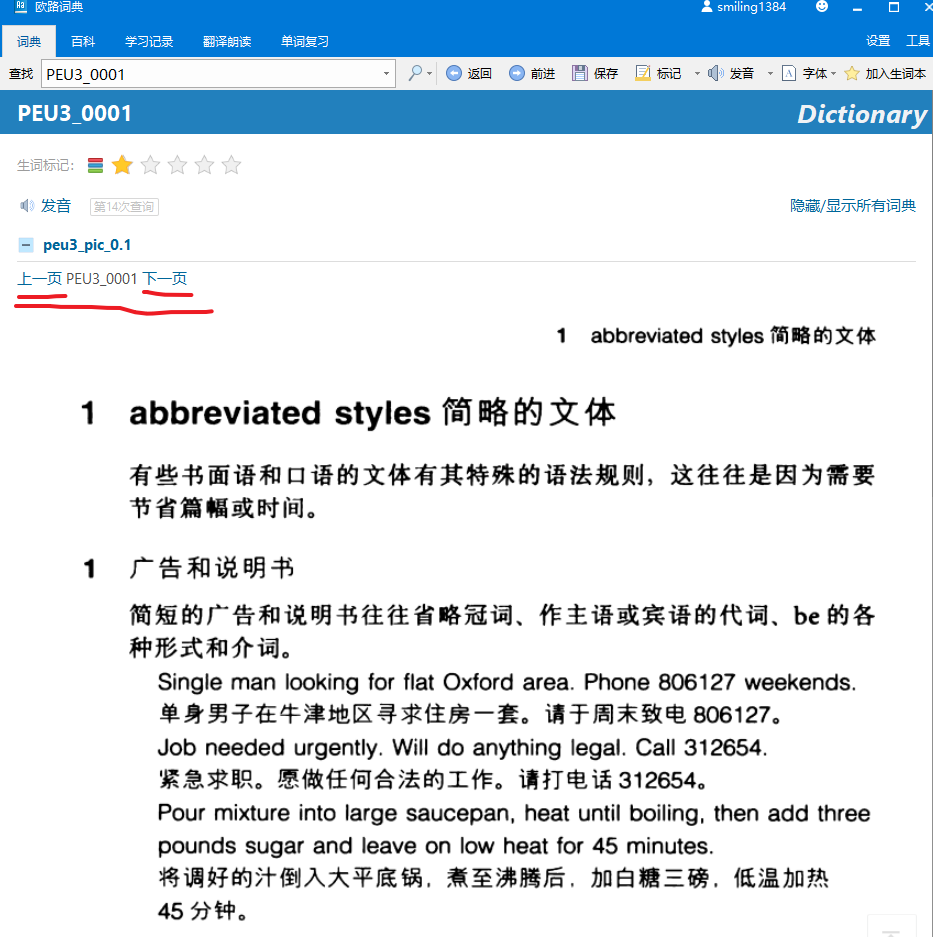
所以,接下来做索引跳转。思路很简单,就是用正则去发现所有带编号的条目,替换成词典能识别的链接。这里碰到了一个小问题,就是到底是跳转到该数字词条,还是跳转到相应的页码。因为前面只为每个页面图片实现 entry, 所以选择跳到页码。这个页码通过前面的词头表映射得到。
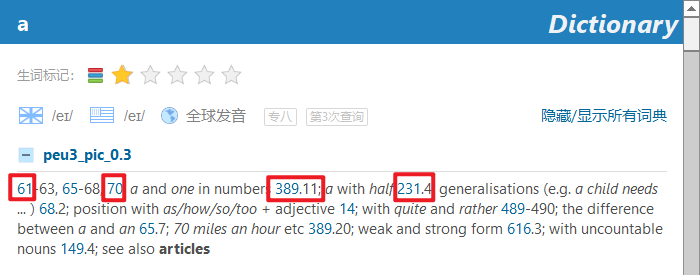
替换之后,查单词 a, 可以得到这样的文字结果:
然后点击数字,可以跳转到相对应的页面。似乎之前的 PEU 的纯英文文字版实现了该跳转功能,图片版一般没有实现该功能。因为我找到了 epub,所以顺便较该中英对照的版本也实现了该功能。
如果你要求不高的话,本词典基本做完了,后面,我将只做一些优化。
下面是本回贴所涉及到的全部代码,主要是链接转换,就一个小文件,为了快速完工,可读性较差。
get_index_word.py (1.1 KB)
Entry_0.3.mdx (79.0 KB)
总结
(1) 有些词的索引只有一个页码,对这种情况,应该直接跳到相应的内文,不再应该出现一个单独的中转页。这个问题是有办法解决的,等后面再说。
未完待续
因为收到你的回复说我可能不能坚持做出来,结果我没忍住,换了工具,改成 python 语言,用了半天(连带写贴子,总共应该花费了一天)基本完全做出来了,达到了预期目标。当然,如果改用 golang,需要的时候可能会长达1个星期。最后,这本词典能提前完工,首先得感谢你。
2 个赞
Vim
2021 年11 月 7 日 10:08
18
赞!
好的,我有搞不定的定当请教。不过我才入门水平,尽量百度
您好,hua 大, 我有一个 Golang 问题,就是希望将格式化的字符串并写到文件,中间有回车换行,可是它原样输出了。请问正确的做法是怎样的?
希望以下的代码将 a,b,c分别在三行输出
writer := bufio.NewWriter(file_out)
txt := `a\nb\n\c`
s := fmt.Sprintf(txt)
writer.WriteString(s)
写文件的结果是: a\nb\n\c ,它没有分成3行。
完整代码:
package readfile
import (
"bufio"
"fmt"
"os"
"testing"
)
func TestWriteFile100(t *testing.T) {
file_out, err := os.OpenFile("new_line_test.txt", os.O_WRONLY|os.O_CREATE, 666)
fmt.Println(err)
defer file_out.Close()
writer := bufio.NewWriter(file_out)
txt := `a\nb\n\c`
s := fmt.Sprintf(txt)
writer.WriteString(s)
writer.Flush()
}