“瘝”字頭(特製字型)

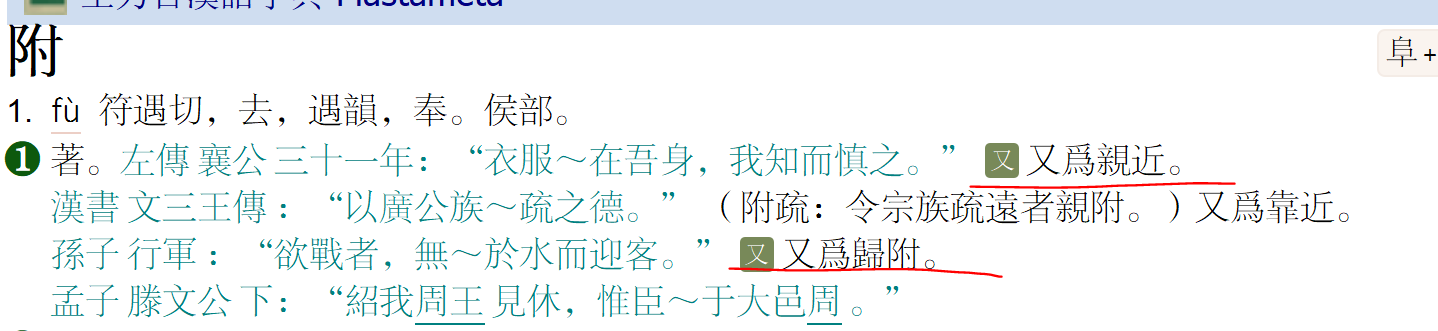
“備”字條(加上王力《同源字典》標題、王力《常用字字典》的“辨”)

整頁版:

模擬單欄切圖模式:

《同源字典》:

Mastameta 2021.10.20 首發
感謝 hua 分享數據。
綜合版加了:整頁圖像版;完善的拼音、部首索引;配合中華書局的特製字型;又添上王力《同源字典》標題與圖像、王力《古漢語常用字字典》的“辨”和“注意”內容。文字化了圖像,修訂了文字版,重造了CSS。
使用方式:
- 字條右上角標頁碼,能連接到整頁圖像版。若屏幕若放窄,會模擬(單欄)切圖模式。要翻頁,按頁面的左右邊緣。
注意:在MDict app 要關掉 Settings: View: Resize images to fit in window。在Dict Tango,勾選: Manage dictionaries: Edit detail: Disable image auto resize.(不能讓軟件強迫 100% 寬度,否則軟件不理CSS的指定。) - 釋義模仿《常用字字典》格式:標上“引[申]”、“泛[指]”、“喻[用]”、“又”義,讓釋文看得更清楚。
- 《常用字字典》的“辨”內容出現在相關字條之下(與字典正文隔開),增補了該字典缺的字組;內容方面有所不同,更強調簡化字與古代漢語的關係,例如:“在古代,‘广’和‘廣’是兩個字,意義各不相同。”
- 特製字型收了所有該字典用的特別字形和符號,避免了對ZhongHuaSongPlane15字型的需要,省了體積。
- 拼音索引不僅收了主要讀音,也收了舊讀、又讀、所有讀音。拼音索引也同時用部首排字。
- 同樣,部首索引也用韻母排列。
- 跳轉方面,除了舊體、新體、異體,也加了簡體跳繁體,但受限制:已有字頭則不另跳他處。因此“钜”會跳“鉅”,但“巨”不跳“鉅”(“巨”當字頭,已有目的地)。這樣給簡體搜尋提個方便,但繁體搜尋不受影響;這畢竟是正體字字典。再說,沒必要讓一個“干”字繁雜地冒出“乾”、“榦”、“幹”字條,因為《常用字》的“辨”內容已經提供了這些正體字的連接。
- 該字典的5,000詞目都加了跳轉,關鍵有800詞,難以預料相關的字條,不見得是復詞的第一個字,例如:“玪𤨙”居然在“瑊”字條,“𢖇𢖆”在“𤢒”字條,“踧沑”在“沑”字條。(釋義的“一作X”、“亦作X”、“又寫X”等等格式,盡量拿來增補跳轉。)
- 電子數據本來沒標出字頭的筆畫數;這種信息也不能隨便套上去的,因為各字典算法不同,而且收納的字形不同,筆畫自然也不一致。我增補的筆畫數是推論出來的,若跟頁碼排次出衝突,就手工校訂,應當反應該字典的索引說法。
特製字型與文字化的工作:
- 把200多圖像都文字化了,若中華字型有搭配的字形,就直接換成標準字;字形不合,就給它造字形,在特製字型掛在標準字上。所造的字形,都配合中華書局的規度、風格、比例佈局。真貨跟我的假貨,應當難以區分呵呵。
- 數據用了200多私有區字,若有標準字碼就直接替換,沒有的話就保持了字形而盡量掛在標準字上,用特製字型和CSS/HTML來顯示。例如,保持了私有區
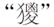 字形,而掛在“猣”字上(拷貝出來就是“猣”);保持了
字形,而掛在“猣”字上(拷貝出來就是“猣”);保持了 字形而掛在“㬥”字上。不用私有區字碼,文字才能正常使用,與其他字典通用,能繼續查字。
字形而掛在“㬥”字上。不用私有區字碼,文字才能正常使用,與其他字典通用,能繼續查字。 - 特製字型也增補了該字典用的而中華字型缺的G擴展區字碼、康熙舊體、和異體字。特製字型總共有300多字。增補了三個相容字(滋缾鉶)、兩個G擴展區字(𰮤𰮾)。最後有90私有區字:其中80個是小篆或甲骨文。
.1.MDD(整頁圖像版,291MB) 2022.12.28更新
.2.MDD(同源字典圖像版, 54MB)
- 潸字居然不歸潸韻,不合理,所以做了補充。
- 𧁾字條的反切沒有根據,所以加了案文。中古轉寫又改成 luw。
- 原來我把甲骨、金文掛在平面16 PUA,今挪到平面0 PUA,因為後來《部件檢索》也擴展到這區,最好不跟它重疊。又在“鼏”字條增補了段玉裁對“𪔃”篆的更改:
 。
。 - 《常用字》辨析,補了“言、語”。
- 以“朌”當字頭;增補“肦”來分義項。修了“㕒”字條的同源字有格式問題。
- 給 夐、胊、脧字目加了異體字,為了分辨義項,和解除電腦漢字方面的疑惑。(“夐”字,字形與部首出矛盾:王力字典依《說文解字》,把“夐”歸“攴”部;但又繼承《康熙字典》說法,把字形定成从“夊”。“遠”的義項从“夊”;“營求”的義項从“攴”。Unicode 胊、朐、朘、脧 的分辨都來自《康熙字典》。)
- “典”字條:𢼰 是錯字。 改成
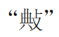 (敟)。
(敟)。 - “笇”字條:
 ,最後字的編碼改成(字形相似的)“𬙬”。(部件檢索:)
,最後字的編碼改成(字形相似的)“𬙬”。(部件檢索:) - “𣎅”字頭(从月)改成“𦝲”(从肉)。兩個字的部首、意義不同,為康熙字典所分辨,因此Unicode分配不同字碼。容易混合,所以加了跳轉。在#174樓,我對這個現象有詳細說明。
- “鬬”字頭,中華書局字型缺乏王力字典用的字形。中華採用 Unicode 9B2C 之陸源字形 GE-5563,而王力字典採用 9B2C 之台源字形 T3-612E:

所以我手工製造出來了,按照中華規度與風格: 。現在兩全:字碼正確,字形準確。字形相近的“鬭”(9B2D),似而非。
。現在兩全:字碼正確,字形準確。字形相近的“鬭”(9B2D),似而非。

2022.2.24

- 字條讀音的韻“部”,連接到王力上古韻部索引。索引按現代韻尾分組,各組又按聲符排次(實際上用四角號的右上右下角碼,一般指偏旁相對的聲符,排次效果不完美但能用)。韻部索引,可以檢查先秦押韻、查尋聲符相同的字(上古音學的基本原則:聲符相同,理應原為同音)。
- 王力韻部索引之下,又陳列白一平的上古擬音。上古擬音標朱色;中古音標青色。注意:白一平韻尾分得較細,推測出59韻尾,相較於王力的30韻部:王韻之於白韻,有一對多的關係。
- 我寫了個700行的程序,讓反切音韻信息輸出中古音,呈現《廣韻》代表的隨朝唐初音韻系統。這樣方便認識入聲,讀詩詞,而且聯緜詞要知道聲音才有感覺。有趣,值得玩玩。
採用白一平的中古音轉寫(Baxter 2014);不選用王力的中古擬音,因為當時沒特別分辨重紐。所謂“轉寫”,目的在標出《切韻》《廣韻》所分辨的音韻(聲母、韻尾、等呼),跟“擬音”有所不同:擬音是解讀轉寫的音值;轉寫是中性的,可以包容不同擬音說法。對於白一平的轉寫符號,我寫了些筆記可以參考:Notes on Baxter transcription.zip
王力字典 12,421 字條有 14,780 帶反切的讀音;我總共加了 14,068 條中古音轉寫,主要針對《廣韻》反切。(2,478 條只標《集韻》反切,80% 符合《廣韻》反切系統,也標了中古音。)沒有《廣韻》或《集韻》的反切,一般是後起字,則不標中古音。 - 音韻信息改成《漢語大詞典》的簡略格式:[聲調] [韻目] ,[聲母]。例如“止”字條:“上,止韻,照三” 寫成 “上止,照三”。(原來字典把“止”字歸“紙韻”,謬。)韻目本身包含聲調,所以止韻必定是“上止”。例如《辭源》“蕩”字條:“去,蕩韻”,謬。蕩韻為上聲。
- 整理過程中翻出了200多反切、韻目、聲母的問題,包括實在錯誤(使信息出矛盾);有的只是字上的差異,不影響音韻的理解。
WL edits - rimes.zip (4.0 KB)
更新記錄
- “榝"字頭,原來字形是對的(由於特製字型),但字碼不對。今改成舊字體“樧"(U+6A27)。
- 現在簡體字也會跳到相關的《常用字》內容。
- 改了“衍”字條的衍文呵呵。(重複內容:【奂衍】叠韻聯緜字。見“奂”字條。)
- fixed a formatting error in “際” entry. adjusted CSS for underlined proper names.
- 蹲字條:説文士部引作“墫墫”(从土)➔壿壿(从士);坎字條:墫墫➔壿壿。
- alexpeng提出的部首總論錯誤,都修了。又分析了總論數據,字方面的問題應當都解決了;補了字型。
- 在拼音索引和釋文加了“倩”的舊讀。
- ⼑部:總論 “説文作𣦃”
- 帽字條:“説文作曰”➔冃。
- 潮字條:“説文潮作淖。説文:淖”➔𣶃。
- 胄字條:“與冃部的‘胄’同音不同義”➔冑。
- 䩜字條:“同胄”➔冑;“説文䩜作胄”➔冑。
- 鞧字條:“説文輶”➔鞧。祅字條:“説文祆”➔祅。篪字條:“説文箎”➔篪。
- 給“說文 [字頭] 作 ”模式加了300個鏈接。
- 加了王力《同源字典》圖像層次;標題融入文字版,出現在3,000多字條。點擊右下頁碼會展開圖像在主界面;翻頁則進入圖像板。
- 王力字典的“辨”條、兩字典的“同源字”條,都徹底加了字頭鏈接。
- 崗:拼音qāng➔gāng。卯:mǎ➔mǎo。(原來是藉合網的錯誤。拼音索引也糾正了。)
- 蘤:增補了“⿱⺾㬙”字形。
- 用“俗稱X”格式加了詞目跳轉;這不是普通跳轉,更像是把俗稱翻譯成古漢語:山藥@薯, 香菜@芫, 小茴香@蒔, 土茴香@蒔, 等等
- 從王力《同源字典》加了100多字頭跳轉。 躚:亦作“躚”➔蹮。贛:字本作“贛”➔𥫔。
- 全:“説文作仝”(tóng,从人)改成“㒰”(quán,从入)。據《說文》:从入从工。全歸入部。跳轉:㒰@全
- 譌:增補“⿰訁為”字形。給 “[字]也作X” 的格式加了100多連接(href)。增加100多詞目跳轉;字目跳轉,調了些目的地,例如:㩅@抽 改成 㩅@㨨。
- 刪了不妥的跳轉(只是關聯字而不是異體字);改了些跳轉的目的地。
- “朌”(从月)改成“肦”(从肉)。“朘”(从月)改成“脧”(从肉)。
- 改了“臭”字條,辨。“矜”字條,按。“執”頁碼。
- 原來上引號和下引號的比例不是一對一,是紙書原有的問題,所以修改了引號的錯誤和遺漏,例如:薧隉殑佻洌里佻𦅷㝅尚𤿡箠䐜蹂辱鏌隔風俘斷宸耳等等字條。這問題也影響分辨引證的標籤,都改了。
- 增補了“部首總論”文字,放在部首索引頁。(“總論”題目能連接到圖像板。)這大概是OCR數據,不少錯字、衍字、不該有的簡體字。
- 既然完成了“部首總論”的工作,我才有機會關注手機使用。在Android MDict app,行為正常。
- 中華兩個字型(平面00、02)共有90,000字,佔 32MB,但該字典僅用其六分之一。為了減少體積,尤其配合手機,把所用的15,000字抽出了,包在MDD:現在中華字型與特製字型,總共只佔 5MB哈哈!兩個禮拜前有這個念頭,昨天才想通具體的處理方式。
- 原初的修改記錄更長,收藏在這裡:
WL edits - rimes.zip (4.1 KB)