这里原文就是死板板
3 个赞




usetherightword.txt (21.7 KB)
html 标签有缺失的部份,211条
2 个赞
哭了…这么多
谢谢。请问是用什么软件或者程序找出来的?
between 6515…6521是什么意思?如果是列数,这一行没有这么长啊
自己写的,还不完善
类似下面这种跨标签的情况,会多报一次,实际数量会少一些
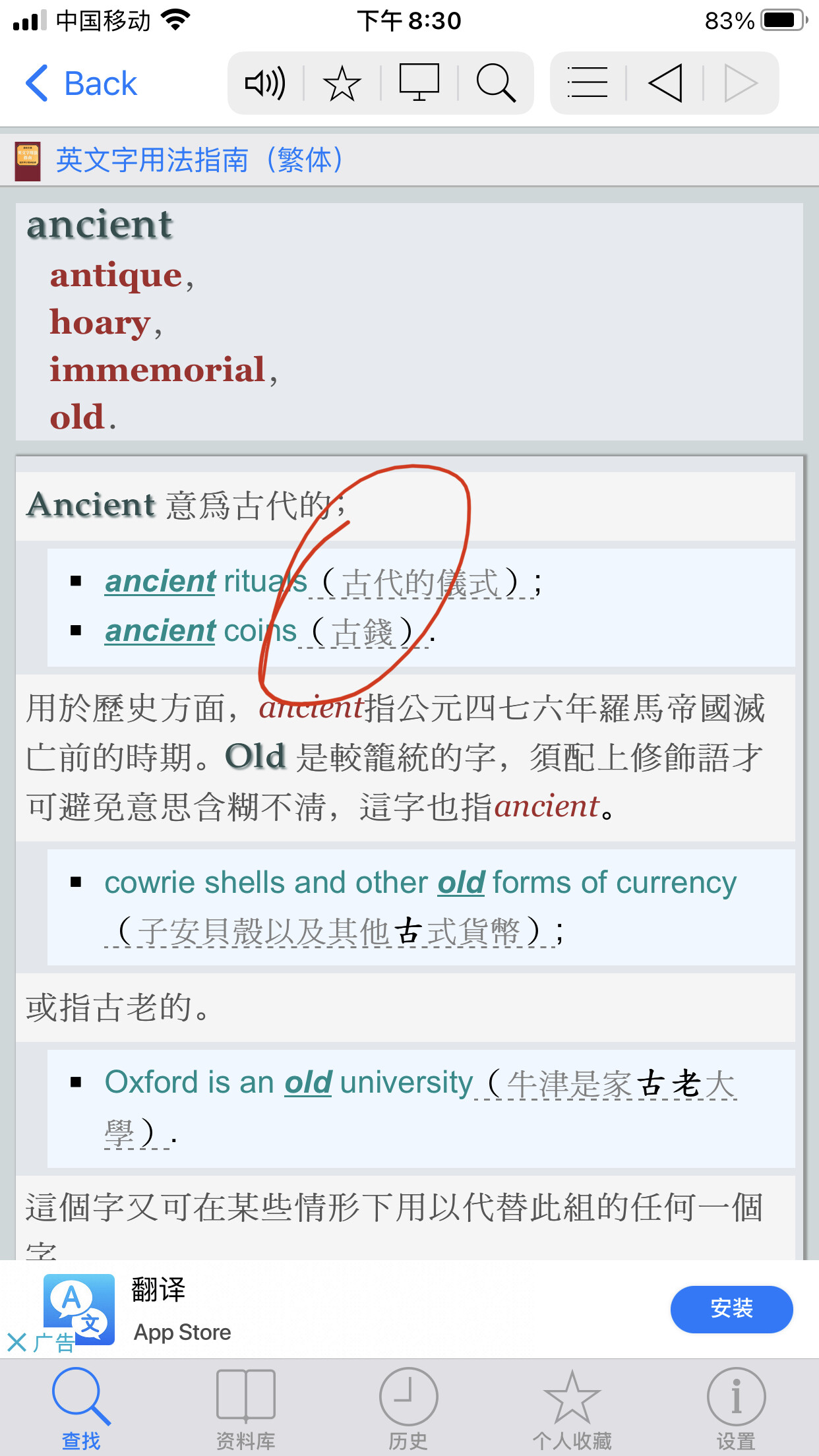
<zh>正确的格式是在信的开头用
<span class="bd">Dear Sir/Madam</span>(即不认识收信人),则信末用
<span class="bd">Yours faithfully</span>, 而在信的开头用
<span class="bd">Dear Mr/Mrs/Miss/Ms Smith</span>(即知其名而不熟悉者)则信末用
<span class="bd">Yours
sincerely/truly.
</zh> </span>
1 个赞
厉害了!
如果能像消消乐一样,有个按钮点一下即标记出HTML文档中最底层的、中间没有任何标签的完整开闭合内容,(人眼判断没问题后)再点一次可把这些内容消除掉。如此继续。
这样子查找标签闭合问题就方便多了
between,是字符位置,就是编辑器里的列数。我更新了,之前中文没考虑,现在应该准确了。
2 个赞
之前是想自动补全来着,类似gd那样处理,但实际补全后,还是会有错误,不适合文本修订的阶段
<div><span>aaaa<i>bbbb</i></div>
自动补全的</span>,不知道应该放在<i>之前,还是放在</i>后
1 个赞
</i> 后
用 stack 来做这个
统一一种处理方法来解决这个问题就好了吧。。
对,是用 stack 处理的。这个文本嵌套情况很多,还是让作者自己判断好一些。
1 个赞
看使用场景和需求吧。
想快速、基本能用的,自动化处理。可以用python实现,然后命令行
要精确完美的,可能还是需要人工干预、消消乐找出问题,毕竟原来HTML的嵌套关系可能非常乱。就是需要GUI,可能用JavaScript来实现方便一些。
看来JavaScript我还是要学一下
1 个赞
如果要用工具,那么就统一种处理方法,至少保证了一致性。。
需要人工干预的,人力判断是必须的情况,哪个语言都一样。不过你学 JS 还是有好处多多的。
3 个赞
建议输出结果txt的编码与原来文档编码保持不变,现在输出结果txt默认保存为ANSI。
我原来文档编码是utf-8,输出结果txt中文变成乱码
1 个赞
usetherightword.txt (29.3 KB)
补充文档行数,编码是 utf-8
1 个赞
2021-05-04:
- 根据 @last_idol 提供的清单,大致解决约200处标签闭合问题。
- 根据 @W2K 提供的清单,大致解决约200处例句的关键词高亮问题。
- 改正approximately/ brusque/ consult/ cheat/ denomination/ forsake/ summary/ wind等词条问题。
- 文本中的
.应为分隔号·或逗号,—已替换
英文字用法指南2021-05-04.zip (2.2 MB)
4 个赞
这个mdx的标签基本上是按字符类型强行加上标签,不考虑结构嵌套关系的。所以检查程序有无可能把AI算法引进来呢?从使用者的调整标签操作中学习。不知道是否是飞机打蚊子,哈
再反馈个小小bug:检查程序的列数起始编号是0,而大多数文本编辑软件的起始编号是1。
4 个赞
附件是老帖mdx中所有的HKSCS 清单,要EditPlus类似的专门文本编辑器打开,否则可能乱码。
这些是我手工逐个找出来的,仅限于出现在老mdx中的,不是完全清单。
list.txt (1.3 KB)
不是字体专家,能解决手头问题我就止步了。
如需要完全清单我贴一些线索供参考:
香港增补字符集(HKSCS) 背景介绍
香港增补字符集HKSCS的源起–百度百科
https://baike.baidu.com/item/香港增补字符集/
1980年代中期, 台湾的中文电脑的通行内码为 Big5 编码。1990年代初期,香港电脑应用逐渐普及,而政府各部门也电脑化。和台湾一样,香港也是使用繁体中文的地方,是故也采用了 Big5 编码。可是 Big5 码本身没有收录香港常用的广东字、一些人名地名用字、一些学科用字,于是香港政府各部门使用 Big5 的外字区,自行补上这些字,并在政府内部使用。香港业界也不断要求政府,本地需要一套标准字符集来作电子文件来往。到1995年,互联网在香港起步,而政府也推出了自己的网站。各人电脑的中文系统虽然都用 Big5 编码, 但都没有政府用的外字,更可能用了自己的外字,使在浏览网页时不能显示正确的字元。香港政府于是把内部使用的 Big5 外字集公开,让各界可以下载安装这批字,使电脑能显示正确的字元,并把这套字命名为「政府通用字库」。
1995 年的政府通用字库本来是内部使用的,到 1999 年才成立中谘会专门去负责增收及审核字元的工作,并与 ISO 10646 接轨。中谘会的成员会把香港增补字符集交到 ISO 的表意文字小组中,尽量让其所有字元纳入国际标准。表意文字小组会定期开会审议汉字的收纳等工作, 成员是来自世界各地的专家。
香港增補字符集(HKSCS)可以被視為政府通用字庫的第二版。香港字在 Big5HKSCS 内的码位,都能对应到 ISO 10646 中日韩汉字区段中的码位,或 Private Use Area(用户造字区,简称 PUA)内。随著版本的更新,造字区的字会逐渐搬到中日韩汉字扩展区内。将所有已纳入的 HKSCS 字元搬到正式中日韩汉字扩展区段(非 PUA 区段)的工作在 2005 年完成,对应于 ISO 10646:2003 的第一修订版,相应的 Unicode 版本为 Unicode 4.1。
不过,因为目前流传极多使用旧版 HKSCS 的系统产生出来的文件,为了方便过渡,在 HKSCS 的定义中,在 Unicode PUA 所分配的字元位置会予以保留,不会给新加入而且未分配正式 Unicode 位置的字元使用。
最初的香港字,是由早期的台湾厂商 (像倚天等) 和用户自行造字所得。因为大部份都不合标准和没有流通,所以没有沿用至今。後来,Truetype 字体盛行,中文字的厂商都开始加入香港字,但因为是商业性质,没有足够的流通量。另外,在支援超大字库的字体方面,因为 HKSCS 某些字和大陆 GBK 码有冲突,厂商经常会因市场关系舍弃一些香港字。香港政府的「数码 21」网页 (详见下面的外部连结) 有提供由华康授权的香港字参考宋体,但一来是使用条款苛刻而不可能广泛使用,二来是没有推广,致使政府内部人员也不知道这套字体的存在。目前由商业主导的情况渐有改变,近况如下:开放源码字体文鼎在 1999 年捐了四套字体 (繁简明体和楷书) 给自由软体界,但当中没有香港字。後来高盛华 (Arne Götje ) 发起计划将繁简体合并,称之为 CJK Unifonts。当中,Akar、Zunix 等人在 2004 年末另外发起香港 freefonts 计划,将香港字加入CJK Unifonts之内,到了 2005-09-01 完成将 HKSCS 2004 加入 CJK Unifonts 的工作。目前 CJKUnifonts 已被收录在各大 Linux distribution 之内。商业字体最早一套宣称支援 HKSCS 2004 的字体,是华康「金蝶 2006 H.K. Edition」,在 2005-11-14 推出。增收字元「中谘会」会让各界申请新字元,不过要经过审核批准,才会给字元编配码位。而用户自造的字,可视乎需要加入,特别是一些人名地名等会经过互联网传送的字。另外,这些增收的字元不一定能够收录在 Unicode 之内,例如一些能够表示成 Unicode 复合字元的字或符号,便不会收录。另外因为现在馀下的 big5 相容码位不多(2005 年 9 月为止只剩 487 个未用),中文界面咨询委员会暂定打算在 2007-08 年停止为字元提供 big5 码位,并在之前尽量协助业界和一般用户过渡至 Unicode。
香港增补字符集当初因为是补充 Big5 的收字不足,使用其外字区而发展的,所以受制于 Big5 的编码架构,外字的总数最多只能到 6217 个(每区块 157 字,有 39 区块半)。除去已用码位,剩下千馀个码位,其中有部分会保留给用户造字。
早期的倚天中文系统、国乔中文系统等对造字缺乏管理,而又没有文字专家的审定,因此当时造字很是混乱,有些甚至可能只是临时使用的「错字」(寻遍各大字典、专书也查不到的字);制作这些中文系统的厂商又对字形、字体缺乏认识,有些字会因为字体不同而字形稍有差别,分别编进了两个码位中。又有同一字有系统区及造字区两个码位,有些联绵词只收其一不收其二;这个问题带到了政府通用字库和香港增补字符集中,字集因要反向相容而跳过了一些码位。
Big5 原来的编码,只有汉字、标点、注音符号等字元及少数图形,後来经过台湾厂商的增收,多了 7 个「倚天字」(如里、恒)及日文的假名,最後这批字元又被香港增补字符集收入。
香港增补字符集所使用的 Big5 的外字区分几个区段:
「造字区一」(FA40 — FEFE):早期的 GCCS 字符集已经填满这一段。
「造字区二」(C6A1 — C8FE):倚天用了这段来放日文假名等符号。这些符号在 HKSCS 1999 年的版本被收纳。
「造字区三」(8140 — A0FE):香港增补字符集把这段开头的 (8140 — 84FE) 保留给用户,新增的字元只用其馀的码位。
「厂商造字区」(F9D6 — F9FE):这段开始的七个码位用来存放里、恒等「倚天字」,之後的码位被微软的繁体中文 Windows 用来存放制表符号。後来 HKSCS 1999 年版本将之全部收纳。
可是一般提及 HKSCS 的文件,包括来自香港政府的,都没有注明 HKSCS 以外的一般繁体字编码(即是 Big5 本身)使用哪个版本。Big5 在 2003 年前就只有一个版本,不会造成混淆,但 HKSCS-2004 的文件仍没有指定 Big5 部份是 2003 年之後还是之前的版本,虽然到目前为止并没有任何系统使用 Big5-2003。
1 个赞