英汉版的能把What is添加进来吗?
理论上是可以的当然实际上也可办到只是需要些时间。不如等等?或许网站以后改版又加回来呢?
好的,谢谢!
英汉双解版更好
现阶段还有种折中的方法,那就是把所有What’s的内容都提取出来,单独列为词条
1 个赞
可以尝试一下
1 个赞
这不巧了不是,
whatis.mdx (5.0 MB)
但是有问题,解包英文版的mdx,会报错,53,747条词头,只解包出53343条词头,只成功解包到wrong horse,
提取词头和whatis栏目,保留css和样式,但是不知道为什么显示没样式
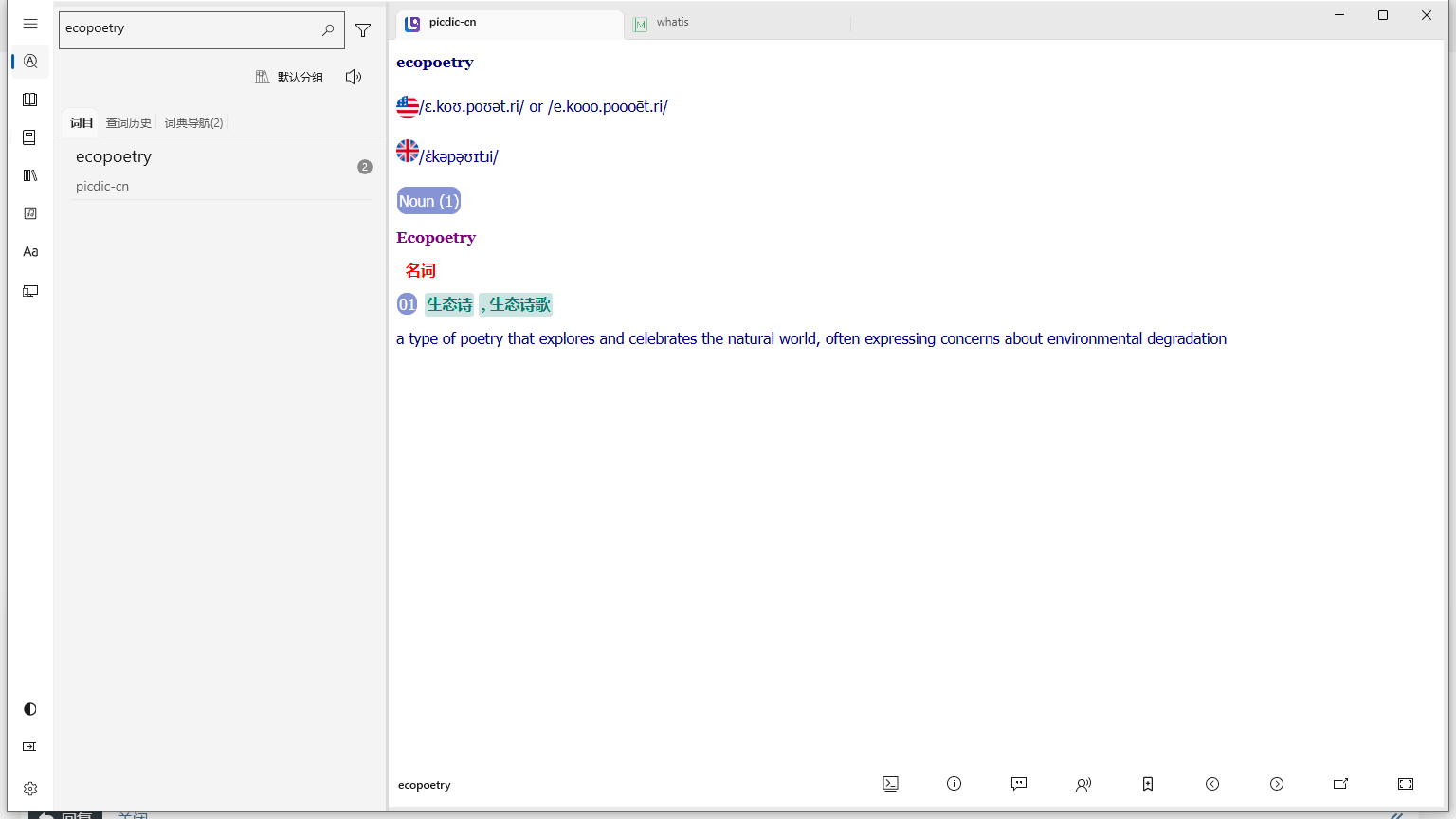
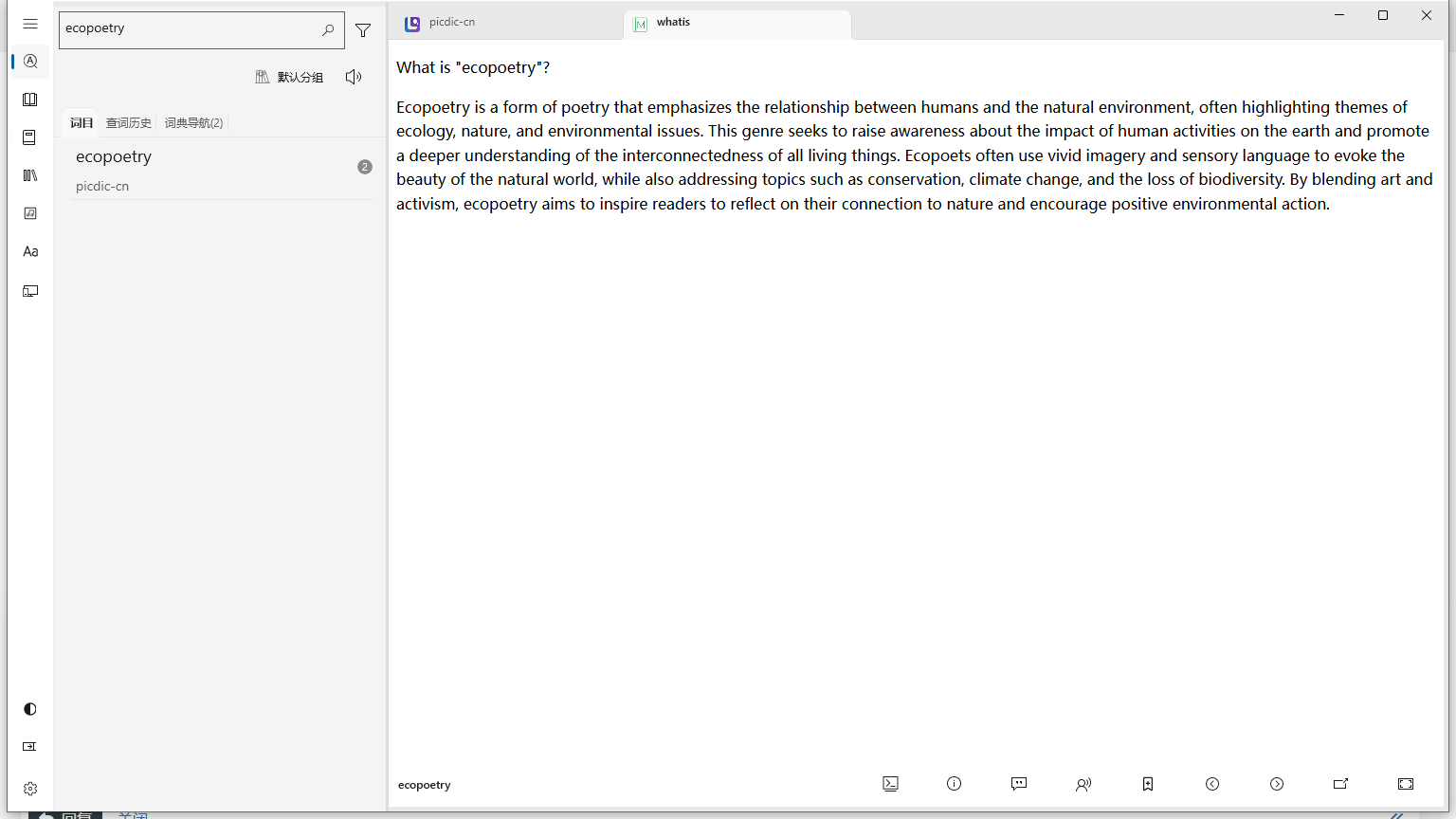
等以后再说把whatis翻译出来整合进来什么之类的
来吃瓜
我有方案了,将词典合并,27国释义(含英语)用css和js实现显示和隐藏,实现英语翻译为26国语言,26国语言反查为英语,或者互相反查
可以勾选你要的语种,例如中英,日英,中日,或中日英,日语只是代表非中非英的任意语种
勾选中英,不显示日语释义,则中英反查,
勾选中日,不显示英语释义,则中日反查,
勾选日英,不显示中文释义,则日英反查,
双击展开所有例句义项,单击显示/隐藏你所勾选的语种,类似完美版的功能,理论上可以27国语种相互反查,
以中文日语举例,
中文反查英语时,隐藏日语,
中文反查日语时,隐藏英语,
日语反查中文时,隐藏英语,
日语反查英语时,隐藏中文,
英语词头:
fork
释义:
01叉子, 餐叉
01フォーク, 叉 (さし)
01an object with a handle and three or four sharp points that we use for picking up and eating food
02叉子, 园艺叉
02フォーク, 鍬(くわ)
02a gardening tool with a handle and three or four sharp points, used for digging or moving hay
反查词头
叉子:
Fork
01叉子, 餐叉
01フォーク, 叉 (さし)
01an object with a handle and three or four sharp points that we use for picking up and eating food
Fork
02叉子, 园艺叉
02フォーク, 鍬(くわ)
02a gardening tool with a handle and three or four sharp points, used for digging or moving hay
餐叉:
Fork
01叉子, 餐叉
01フォーク, 叉 (さし)
01an object with a handle and three or four sharp points that we use for picking up and eating food
园艺叉:
Fork
02叉子, 园艺叉
02フォーク, 鍬(くわ)
02a gardening tool with a handle and three or four sharp points, used for digging or moving hay
フォーク:
Fork
01叉子, 餐叉
01フォーク, 叉 (さし)
01an object with a handle and three or four sharp points that we use for picking up and eating food
Fork
02叉子, 园艺叉
02フォーク, 鍬(くわ)
02a gardening tool with a handle and three or four sharp points, used for digging or moving hay
叉 (さし):
Fork
01叉子, 餐叉
01フォーク, 叉 (さし)
01an object with a handle and three or four sharp points that we use for picking up and eating food
鍬(くわ):
Fork
02叉子, 园艺叉
02フォーク, 鍬(くわ)
02a gardening tool with a handle and three or four sharp points, used for digging or moving hay
我是解包柯林斯反查想到的,
之前无法解决多语种反查,一直局限在以单词为锚点,做反查,但是无法解决单词多义的匹配
看了反查词典的做法,才明白,反查是以义项作为词头,
正好这个词典是以单词为锚点,单词各义项都做了26国翻译,所以可以,以单词义项作为映射来做多语种反查,
当然27国语种词典的,抓取,洗版,合并,然后再提取26国义项作为反查词头,这工作量就不谈了,不如去翻译OED,哈哈哈
还有这词典的准确性值不值得也是一个大问题,尤其是小语种,
中间上传的whatis的mdx,欢迎下载使用,
1 个赞
你这大餐不错,餐叉园艺叉的都摆上桌了。
查了一下,看到有what’s栏的词条有22050条,此前没注意到有这么多。单独列有好有不好。我两这天尝试一下。
import re
import tkinter as tk
from tkinter import filedialog, messagebox, ttk # 修复ttk导入问题
from bs4 import BeautifulSoup, Comment
import threading
import os
def extract_whatis_content(html_content):
"""精确提取What is栏目内容,保留原始样式"""
try:
soup = BeautifulSoup(html_content, 'html.parser')
# 查找What is栏目 - 使用多个特征确保精确匹配
whatis_div = soup.find('div', class_=lambda x: x and 'tw-bg-orange-light' in x and 'tw-mx-4' in x)
if whatis_div:
# 移除所有注释
for comment in whatis_div.find_all(string=lambda text: isinstance(text, Comment)):
comment.extract()
# 返回原始HTML字符串
return str(whatis_div).strip()
return None
except Exception:
return None
def process_mdx_file(input_path, output_path, progress_callback):
"""处理MDX源文件 - 三行格式处理"""
try:
total_lines = 0
with open(input_path, 'r', encoding='utf-8') as f:
total_lines = sum(1 for _ in f)
processed = 0
with open(input_path, 'r', encoding='utf-8') as f_in, \
open(output_path, 'w', encoding='utf-8') as f_out:
for line in f_in:
# 跳过空行
if not line.strip():
continue
# 分割词头和内容
parts = line.split('\t', 1)
if len(parts) < 2:
continue
word, content = parts
# 提取CSS链接 - 修复缺少>的问题
css_match = re.search(r'<link\s+rel=[\'"]stylesheet[\'"].*?href=[\'"][^\'"]+\.css[\'"]\s*/?>', content)
css_tag = css_match.group(0) if css_match else ""
# 确保CSS标签正确闭合
if css_tag and not css_tag.endswith('>'):
css_tag += '>'
# 提取What is内容
whatis_content = extract_whatis_content(content)
if whatis_content:
# 构建新词条(三行格式)
f_out.write(f"{word}\n")
f_out.write(f"{css_tag}{whatis_content}<br></>\n")
f_out.write("</>\n")
processed += 1
# 更新进度
if processed % 100 == 0:
progress_callback(processed, total_lines)
return processed, None
except Exception as e:
return 0, str(e)
def process_file_thread(input_path, output_path, status_var, progress_bar, result_label, process_btn):
"""在后台线程中处理文件"""
process_btn.config(state=tk.DISABLED)
status_var.set("处理中...")
def update_progress(processed, total):
progress = int((processed / total) * 100) if total > 0 else 0
progress_bar['value'] = progress
status_var.set(f"已处理: {processed} 个词条")
root.update_idletasks()
try:
processed_count, error = process_mdx_file(input_path, output_path, update_progress)
if error:
messagebox.showerror("处理错误", f"处理过程中发生错误:\n{error}")
else:
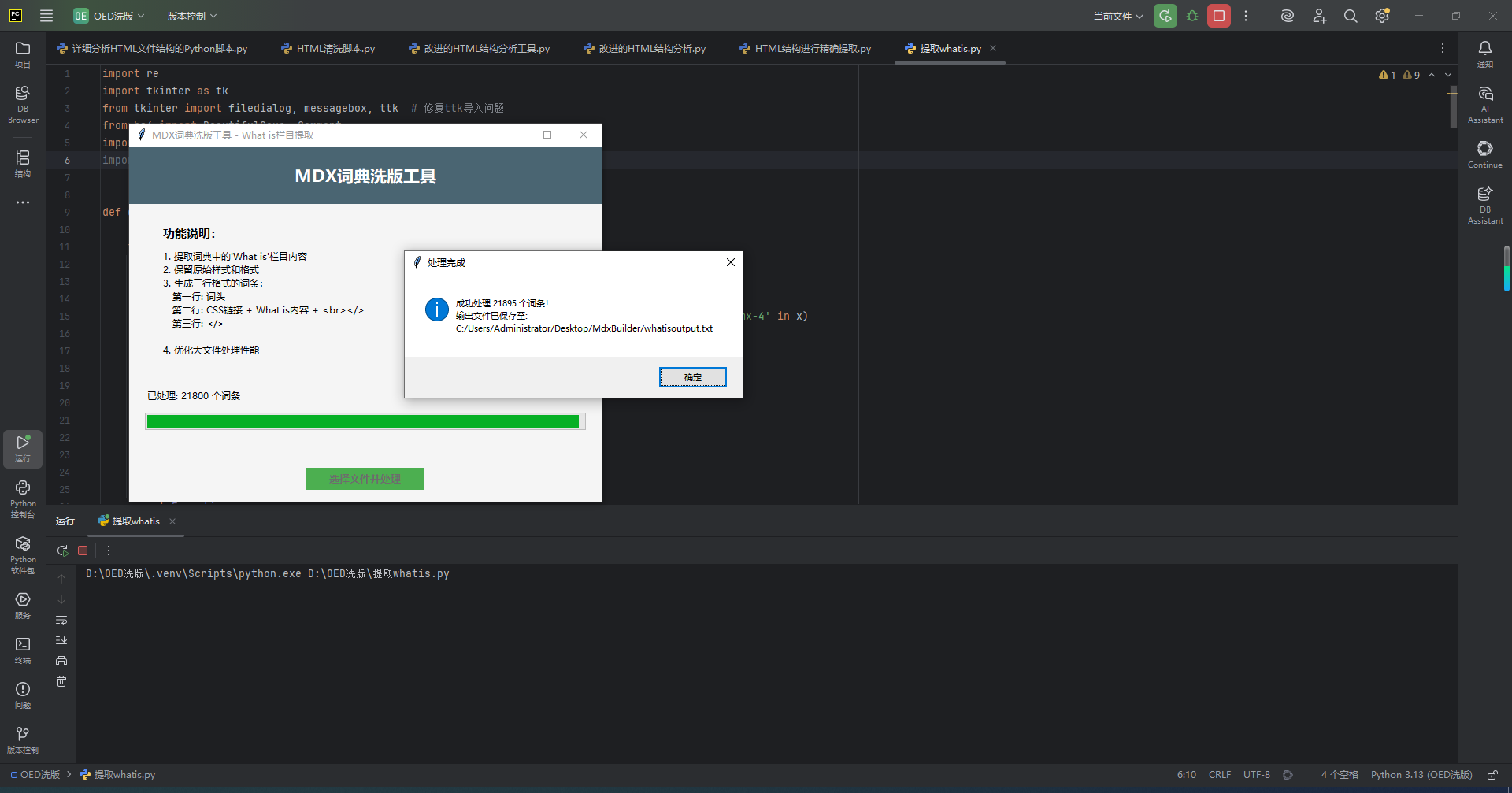
messagebox.showinfo(
"处理完成",
f"成功处理 {processed_count} 个词条!\n"
f"输出文件已保存至:\n{output_path}"
)
finally:
status_var.set("准备就绪")
progress_bar['value'] = 0
process_btn.config(state=tk.NORMAL)
result_label.config(text="")
def select_and_process(status_var, progress_bar, result_label, process_btn):
"""GUI文件选择和处理函数"""
input_file = filedialog.askopenfilename(
title="选择原始词典文件",
filetypes=[("Text files", "*.txt"), ("All files", "*.*")]
)
if not input_file:
return
output_file = filedialog.asksaveasfilename(
title="保存处理后的词典文件",
defaultextension=".txt",
filetypes=[("Text files", "*.txt"), ("All files", "*.*")]
)
if not output_file:
return
# 在后台线程中处理文件
threading.Thread(
target=process_file_thread,
args=(input_file, output_file, status_var, progress_bar, result_label, process_btn),
daemon=True
).start()
# 创建GUI界面
root = tk.Tk()
root.title("MDX词典洗版工具 - What is栏目提取")
root.geometry("600x450")
root.configure(bg="#f5f5f5")
# 标题
title_frame = tk.Frame(root, bg="#4a6572", height=90)
title_frame.pack(fill="x", side="top", pady=(0, 10))
tk.Label(
title_frame,
text="MDX词典洗版工具",
font=("Microsoft YaHei", 16, "bold"),
fg="white",
bg="#4a6572",
pady=20
).pack(fill="x")
# 说明区域
info_frame = tk.Frame(root, bg="#f5f5f5", padx=20, pady=10)
info_frame.pack(fill="both", expand=True, padx=20, pady=5)
tk.Label(
info_frame,
text="功能说明:",
font=("Microsoft YaHei", 11, "bold"),
bg="#f5f5f5",
anchor="w"
).pack(fill="x", pady=(0, 5))
info_text = tk.Label(
info_frame,
text="1. 提取词典中的'What is'栏目内容\n"
"2. 保留原始样式和格式\n"
"3. 生成三行格式的词条:\n"
" 第一行: 词头\n"
" 第二行: CSS链接 + What is内容 + <br></>\n"
" 第三行: </>\n\n"
"4. 优化大文件处理性能",
font=("Microsoft YaHei", 9),
bg="#f5f5f5",
justify="left",
anchor="w"
)
info_text.pack(fill="x", pady=(0, 15))
# 进度条
progress_frame = tk.Frame(root, bg="#f5f5f5")
progress_frame.pack(fill="x", padx=20, pady=5)
status_var = tk.StringVar(value="准备就绪")
status_label = tk.Label(
progress_frame,
textvariable=status_var,
font=("Microsoft YaHei", 9),
bg="#f5f5f5",
anchor="w"
)
status_label.pack(fill="x", pady=(0, 5))
progress_bar = tk.ttk.Progressbar(
progress_frame,
orient="horizontal",
length=500,
mode="determinate"
)
progress_bar.pack(fill="x", pady=5)
result_label = tk.Label(
progress_frame,
text="",
font=("Microsoft YaHei", 9),
bg="#f5f5f5",
anchor="w"
)
result_label.pack(fill="x")
# 处理按钮
btn_frame = tk.Frame(root, bg="#f5f5f5")
btn_frame.pack(pady=15)
process_btn = tk.Button(
btn_frame,
text="选择文件并处理",
command=lambda: select_and_process(status_var, progress_bar, result_label, process_btn),
font=("Microsoft YaHei", 10, "bold"),
bg="#4CAF50",
fg="white",
padx=25,
pady=10,
relief="flat",
cursor="hand2"
)
process_btn.pack()
# 提示信息
tk.Label(
root,
text="输出格式:三行格式,不添加额外空行 | 修复CSS链接问题 | 优化大文件处理",
font=("Microsoft YaHei", 8),
fg="#666666",
bg="#f5f5f5"
).pack(side="bottom", pady=10)
root.mainloop()
1 个赞
这个工程有点大了,如果能成,真是利国利民
这么多技术大佬来参与,词典会越来越棒,英汉双解加上what is就完美了 ![]()
感谢啦啦啦老铁
1 个赞
本站云盘上传,感谢
感谢大佬,最近在背诵词表,这款词典很有帮助!
Bravo bro, efficient and effective ~ ![]()
网站还在持续更新中(我觉得),迟早会完善的。
1 个赞
Collection 没有 what is