在论坛里下载了《二十五史》词典文件,用goldendict-ng无法读取。又下载了mdict,仍然读取不了。今天我重新下载了新的mdx文件,都来自s*ol网盘。但是仍然无法使用。请问是怎么回事呢?自己平时使用二十五史比较多,翻pdf比较慢,希望能够用上mdx版。自己知识有限,不知要怎么破解。恳请各位赐教,不胜感谢。这是文件来源百度网盘 请输入提取码 ;Index of /100G_Super_Big_Collection/汉语/历史/[汉-汉] 二十五史+正续资治通鉴【2011.10.10】/
我所见过的《二十四史》mdx,没一个是详细分传分人的,资料通通堆在一起。很难用的。除非你有时间、心情和技术去改编。
不是需要破解,是没有东西可破解,不值得用。
假如你能找到《汉籍全文检索系统》,可以用那个东西。
网站这么多,随便找一个用吧。
虚阁网
或者去找个epub用。
Chinese [zh], .epub, ![]() /lgli/zlib, 44.9MB,
/lgli/zlib, 44.9MB, ![]() Book (fiction), lgli/Unknown - 二十四史.epub
Book (fiction), lgli/Unknown - 二十四史.epub
二十四史
1 个赞
分类错误,此帖分类应该是:资源求助。
“汉汉”是分享mdx词典时用的。
建议自己修改分类。一直弄错会被禁言。


由于维基文库没有目录,导致两个问题:1、不知道这么大的文库到底收了哪些书?2、即使想检索,因具体名称不清楚,往往导致检索不到。基于此,我用了点时间,制作了一个“维基文库篇目索引”。首先,我对2019版维基文库做了一些“手术”,删掉了收录的绝大多数现代文本,主要是法律法规、政治性文件等,个人不需要这些,由1.9G缩减为1.4G,即删掉大约500M现代文本。删减采用了最笨的方法:手工删除。然后根据删减后的维基文库,提取了目录,按音序排序,以方便查找。提取目录后才发现还是残留了一些现代文本,不过也不想再修改了。根据目录可知,维基文库确实相当丰富,绝大多数的古籍都包括在内了,文本质量优于“殆知阁”,而且很多文献是具体到篇目的,怪不得这个篇目索引也如此庞大。这个“索引”没有添加跳转,个人以为没有必要,想根据目录查找到原文,采用GD-ng的“发送到输入框”的方式即可快速找到原文。在此分享一下,供有缘人下载试用。目录制作很不完善,勉强可用吧。
文库目录.rar (1.3 MB)
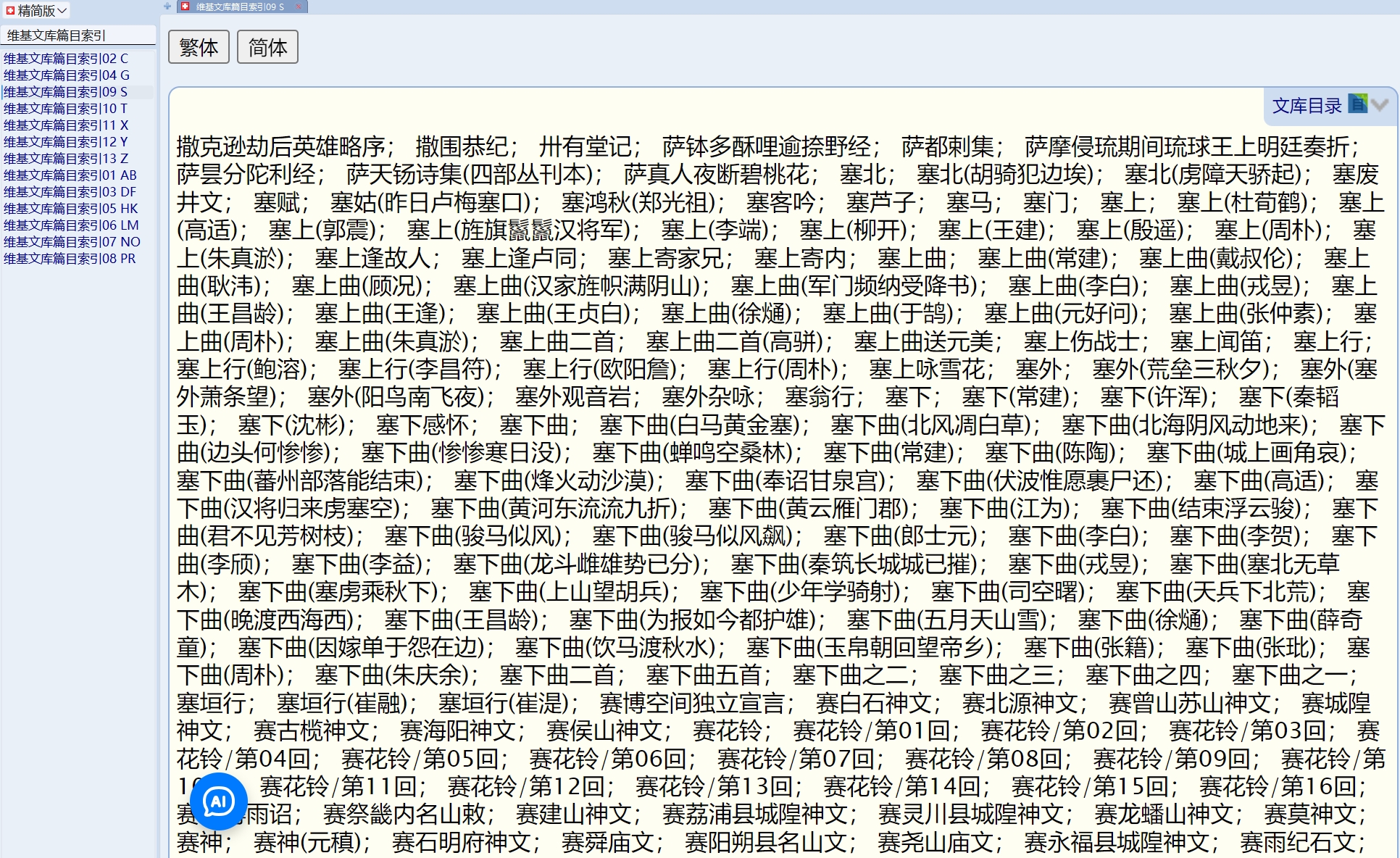
3 个赞



何以见得Goldendict不能用?
键入:
000总目录
由目录进入相关书。
或者这样检索:
三国志001
呃,别想检索具体的人物或字句了。当然,真有需要,设置全文检索吧。
mdx就是这样,因陋就简,自行车水平。免费的东西只能这样。还能希望有豪华轿车吗?

1 个赞
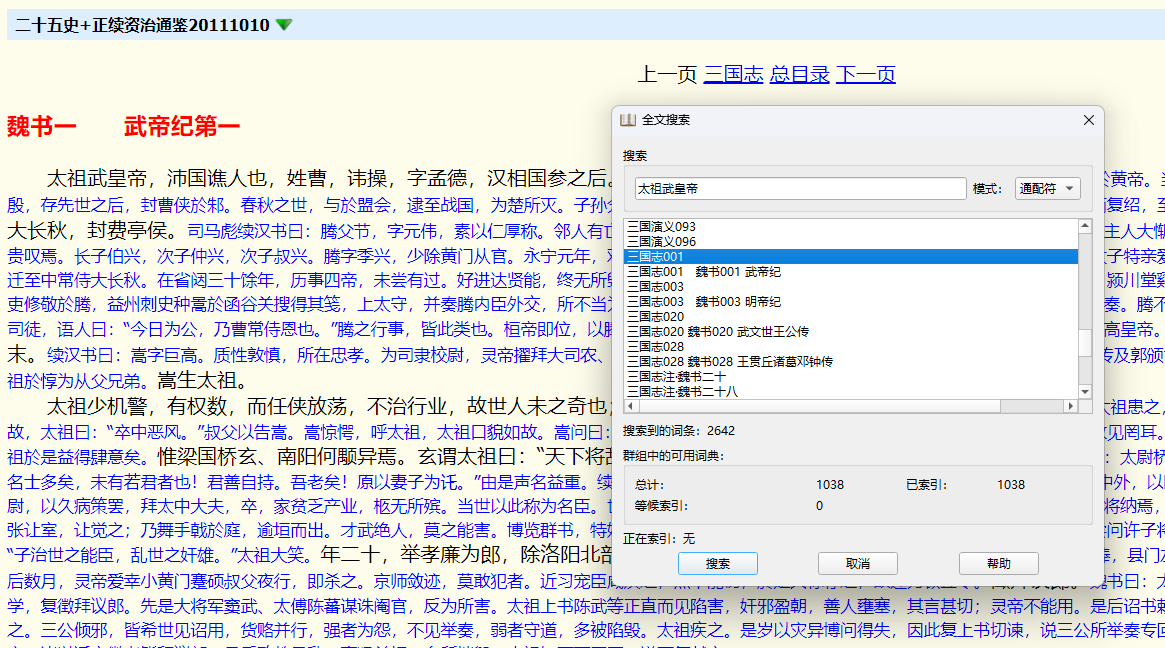
二十五史全文检索的资源多得是,早就解决了,无论是线上还是线下的资源,shaoshi兄在2楼已经讲得很清楚。楼主看来是不会搜索也不大理会别人的意见呀。
还在改问题分类。暂时没读到那儿去。谢谢您赐教。
我因为几种大型mdx文献库中都包含了二十五史,就没下载网站上的二十五史+资治通鉴.mdx。刚刚好奇也下载看了一下,在GD-ng上完美使用,跳转功能等很方便准确,应该说这个版本制作得已很不错!那就在GD中保留此文档了。

我只说这个mdx没有可检索的人物名词头,不能在顶部的检索框里检索,但是mdx都可以全文检索的,需要设置,在另一个地方检索。
《二十四史》的电子版太多了。还有一种chm版,也是可检索的。
Chinese [zh], .chm, ![]() /lgli/lgrs/nexusstc, 40.6MB,
/lgli/lgrs/nexusstc, 40.6MB, ![]() Book (non-fiction), lgrsnf/二十四史+资治通鉴+清史稿.chm
Book (non-fiction), lgrsnf/二十四史+资治通鉴+清史稿.chm
二十四史+资治通鉴+清史稿
中国大学里有特制的网页版可检索《二十四史》,那种版本专业度当然比较高。但是羡慕别人的资源有何意义?自己动手,丰衣足食。我都用自制的Access数据库。
我的版本是在资源库下载的。今天动手改了改。
Index of /100G_Super_Big_Collection/汉语/历史/[汉-汉] 二十五史+正续资治通鉴【2011.10.10】/
https://downloads.freemdict.com/100G_Super_Big_Collection/汉语/历史/[汉-汉]%20二十五史+正续资治通鉴【2011.10.10】//
呃,在Emeditor里检查,有1万多个私用字。
find - regular Expression
[\x{E000}-\x{F8FF}]
你那个版是否也有那么多私用字?
我也是在那里下载的,是的,一个版本。毕竟制作得太早。存一个备用吧。说明一下,我不喜欢文件名弄得很冗长,一般下载后会简化文件名,反正也是自己用,自己知道就行了。 ![]()

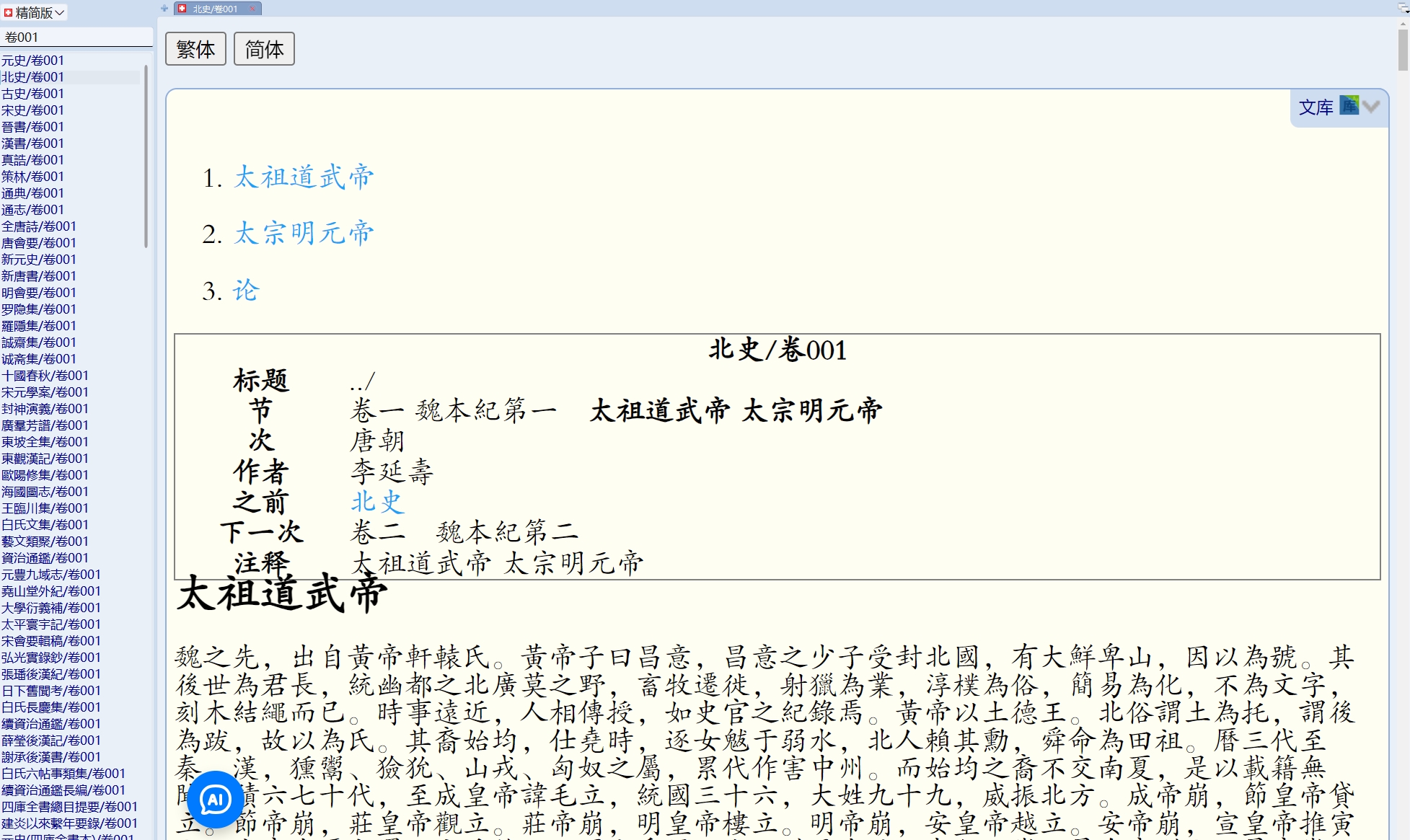
我今天才把《维基文库》mdx版搬出来用。
发现有个诡异的掉字现象。你用的是简体字版吗?是否有这个问题?
繁体mdx版《维基文库》
黃帝
者,之子,姓,名曰。生而神靈,弱而能言,[1],長而敦敏,成而聰明。
《维基文库》的网站,文本完全正常。
黃帝
黃帝者,少典之子,姓公孫,名曰軒轅。生而神靈,弱而能言,幼而徇齊[1],長而敦敏,成而聰明。
https://zh.wikisource.org/wiki/史記/卷001
本来想把《维基文库》的二十四史抽出来做单独的mdx,发现这个残缺问题后,就兴致索然了。
资源库这个mdx有可怕的简繁转换残留痕迹。
丹硃–>丹朱
尧曰:“谁可顺此事?”【正义】:言将登用之嗣位也。放齐曰:“嗣子丹硃开明。”
我真是希望做古籍电子文本的人不要自作聪明乱转换啊。
但是没办法,自作聪明的人实在车载斗量。
显然有人将简体文本转为繁体:
丹朱–>丹硃
然后有人看不顺眼,又把这个转换过的繁体文本再转换为简体。
“丹硃”不会再变为“丹朱”啊。
一失足成千古恨,再回头已成残缺本。
这种文本,只能用来做检索用,按图索骥,找到篇目后,去查原版图像比较可靠、
呵呵,才发现,我用的这个维基文库应该是将《史记》误删除了,二十五史大多数都有,但没有《史记》的文本。所以这个维基文库也是个残缺本,我大多是用来查一些小说和笔记(比较全)。不过可以肯定这个是繁体版,绝大多数文字是繁体的,没有经过转换。
2019年版维基文库确实缺陷也很多,收书太杂,没有边界。很多书有目无书。个人感觉其《全唐文》《全唐诗》等制作不错,可具体搜索到任何一篇诗文;小说文本比较多,古典小说应该基本齐全了。可惜近年的没人再做更新了。
资源库只有2016版。
Index of /100G_Super_Big_Collection/百科/邱海波维基更新到20171009/中文维基文库/20161201文字正式版/
https://downloads.freemdict.com/100G_Super_Big_Collection/百科/邱海波维基更新到20171009/中文维基文库//20161201文字正式版/
tmzn过去有2019版,已经消失无踪。
真想要最新的数据,自己动手吧。
Help:下载维基文库
https://zh.wikisource.org/wiki/Help:下载维基文库
《维基文库》网站的单页是可以下载epub或pdf的。
如《史记》,一卷是一页,逐页下载是可能的。
全站都可以下载的。下载后要怎么弄成mdx,是另一个问题。
Index of /zhwikisource/latest/
https://dumps.wikimedia.org/zhwikisource/latest/
参看:
是的,我是在这里下载的2019版,而且当初好像还是您告知的信息。