已知问题:
- pua 字未替换 puas.txt (287 Bytes)
- css 调整中
下载:
- qq_hy_dcd.css (2.9 KB)
- ⿱人王⿰𤣩求⿱化十⿰⻈吾大⿰⻈司⿱册𠔀.mdx (12.5 MB)
预览:

感谢:
- amob 分享
- bud 分享
已知问题:
下载:
预览:
感谢:
感谢楼主辛勤制作。
供参考。
全球华语大词典
主编:李宇明
出版时间:2016年04月
读者对象:世界各地华人,华语使用者、学习者、研究者等
本词典是在《全球华语词典》的基础上编写的,不仅收录条目更多,篇幅更大,信息也更全面,是一部反映世界主要华语区当代华语词汇面貌的语文辞书。
作者简介
李宇明,北京语言大学党委书记,教授,博士生导师,曾任教育部语言文字应用研究所所长、教育部语言文字信息管理司司长、国家语委副主任。
邹嘉彦(港澳组主持人),香港大学语言和亚洲语言讲座教授。
竺家宁(台湾组主持人),台湾中正大学中文系教授。
汪惠迪(新加坡组主持人),新加坡报业控股华文报集团前语文顾问。
庄晓龄(马来西亚组主持人),马来亚大学教授,语言学系主任。
内容简介
本词典是在《全球华语词典》的基础上编写的,是一部反映世界主要华语区当代华语词汇面貌的语文辞书。注重实用性,力求促进不同华人社区之间的交流, 在华语使用中起协调作用。编写过程中充分吸收现有学术成果,反映当代学术研究的最高水平。充分利用了计算机和互联网等现代化手段,提高了辞书编纂的技术水平。
收录华语通用词语和特有词语约88400条
https://www.cp.com.cn/book/302a4a6d-f.html
Chinese [zh], .pdf, /duxiu, 56.3MB, Book (unknown), 12596495.zip
全球华语词典
北京:商务印书馆, 2010
李宇明主编
参看:
商务说有88400条,计算mdx “</>”有88940个。这次商务说少了吗? ![]()
啊,我忘了放词头数量简介了。源数据 88636 条,通过括号、逗号的处理,增添词头到88940。其他词头类型还没来得及处理、代码跑的慢,正在重构中。
请问阁下发的这一系列词典用的是什么字体
您好,在下没设置用哪个字体,系统默认的是全宋体,可以优先使用 vdict 官网的字体或本论坛的全宋体。
PUA字已录入。
puas.txt (348 字节)
你搞这么快,会显得我很慢 ![]()
有四条有"■"
这本的私有字比较少。不用着急,慢慢搞 ![]()
这本《全球华语大词典》相比《全球华语词典》条目增订幅度不小,但是其中很大一部分是照搬《现代汉语词典》,参考价值没有提高太多。
这本在第9页,不过中华科技大词典、新华词典的工期应该是排在它之前。 这两本前者只是词头翻译,后者和现汉7重合较多,排后。
收到,搞其他的了。
没看到过《全球华语词典》,请问楼主方便分享么?
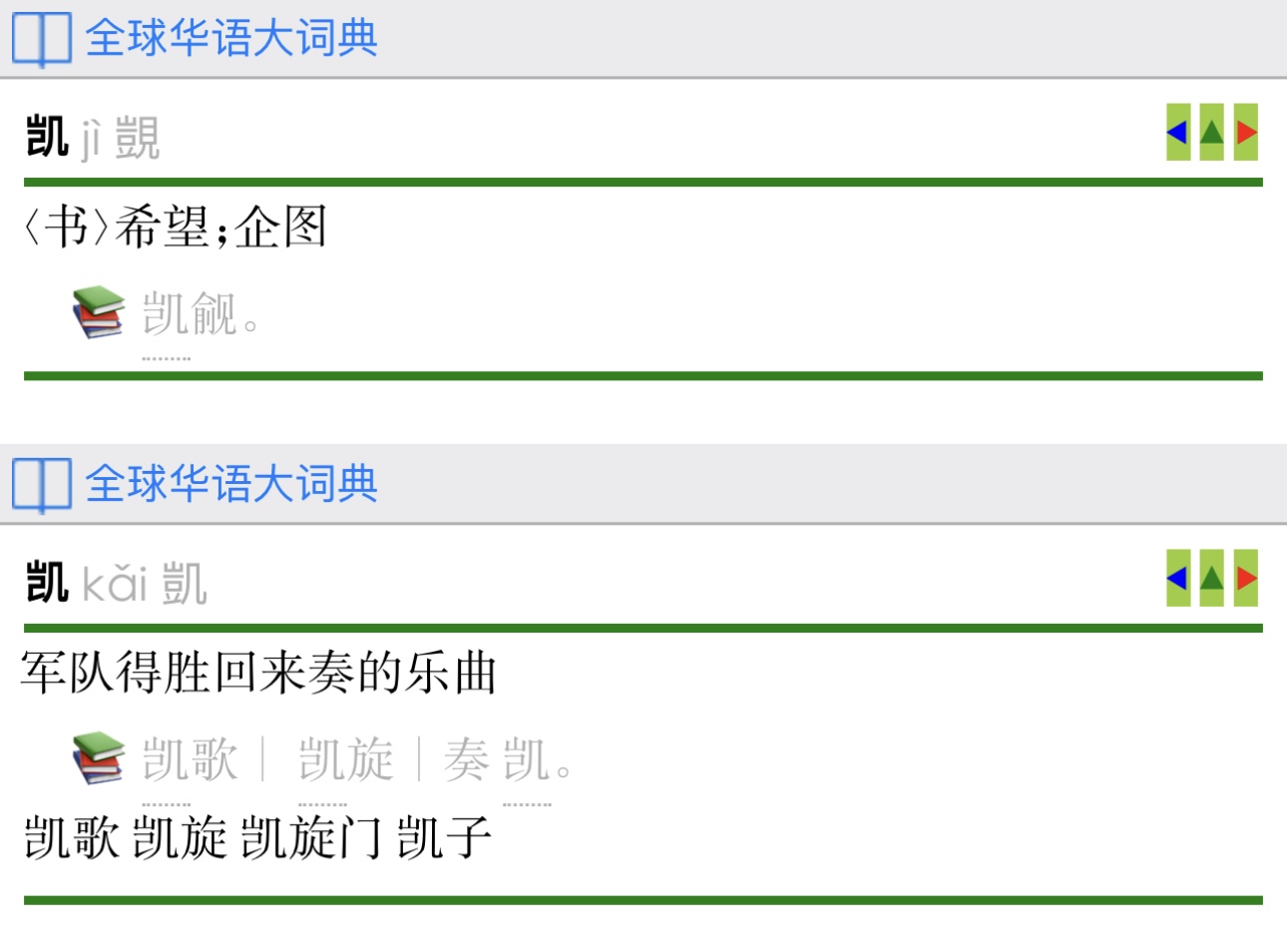
该典,有词头【觊觎】,无字头【觊】。
而有字头【凯】,其繁体、释义都是【觊】的,打错字的可能性很大。
我手里有2010《全球华语词典》和2017年《全球华语大词典》的纸本,和12楼的贴图相同。
《全球华语词典》有“知识窗”,《全球华语大词典》删掉了“知识窗”。也许是为了要节省篇幅?不过有“知识窗”,会比较像百科词典。假如要更像语文词典,删掉“知识窗”是对的。
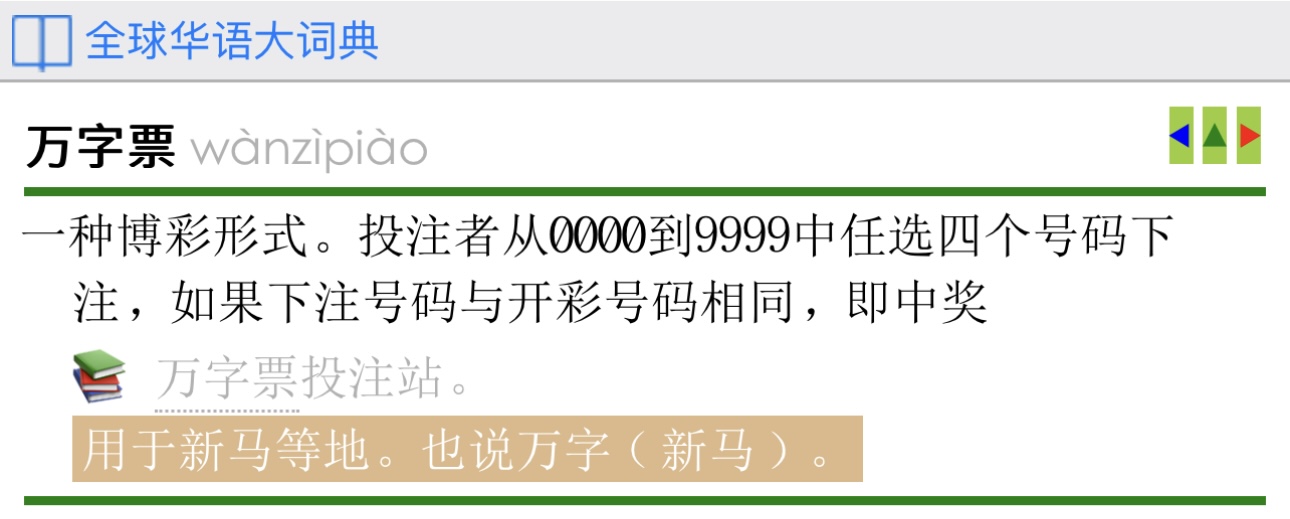
至于例句,别的词头还是有例句。删掉“万字票”的例句,也许考虑到这是赌博,不要说得太多?
不过名词一般上是不需要给例句的。《现汉》的名词似乎都没有例句。删掉“万字票”的例句,不能算是退步,只是使它变得更像正规的语文词典。
凯(覬)
我对了纸本,确定是错字,或者转码错误。要注意有没有类似情况——不排除可能是数据保护手段。
把这个“凯”改成“觊”就行。
啊,不过下面的结构数据也错了。所以也许确实是打错字。
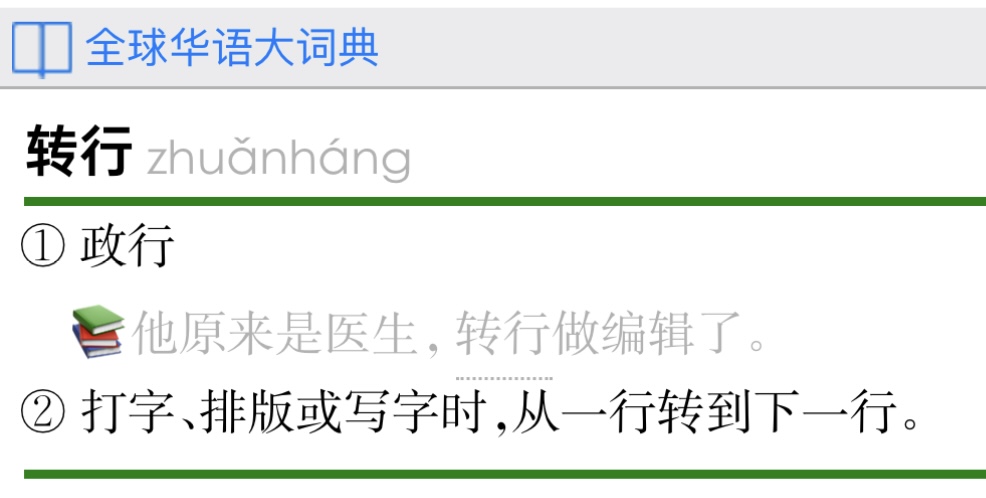
20楼的“政行”当作“改行”。
本坛的某成语源流辞典文字版里也有凯觎,可见OCR致误的可能性较大
![]() 官方这么搞吗,那这词典没啥用了啊,准确度都打不过百度。
官方这么搞吗,那这词典没啥用了啊,准确度都打不过百度。