有这个想法是 @Vim 在掌上百科发的新时代开始的。
软件是百科前一阵子 @chigre 本人发出的,不会用。
@chigre 做过的词典大家都看过就不介绍了,好多人现在还在找他切的词典。(有的玩多谢百科的 @chigre ![]()
![]()
![]()
![]()
![]()
![]() )
)

下面记录下过程,和遇到的问题。
问题最多的是经常是 忽略继续or退出 也就是说使用不对。
目前还真没碰到是软件的问题,都是设置参数或文件不规范造成的。
数值不要照抄,都是参考,因为屏幕分辨率不一样所填入的参数也不一样。起始软件里有说明,都写得很细了,不懂还有 @ Arlin帮忙,剩下的也就是动手了。(对了,多说一句,要是 @Vim 的软件和使用方法先发出来我会先用他的方法做图片词典,因为没有头绪弄图片词典不知无从下手)
进度:
(1)图 完成
(2)词头是@ Arlin帮忙做完了传给我的。(page_words,wordslist)
(3)划线填词 完成
(4)从PDIC导出切图信息调整切词坐标 完成
(5)在excel里改完数值,另存成.bat文件切图 (这一步不是必须的,根据词典来,改完的安装ImageMagick Display,把。bat文件放到图片文件夹双击他就自己干活了) 完成
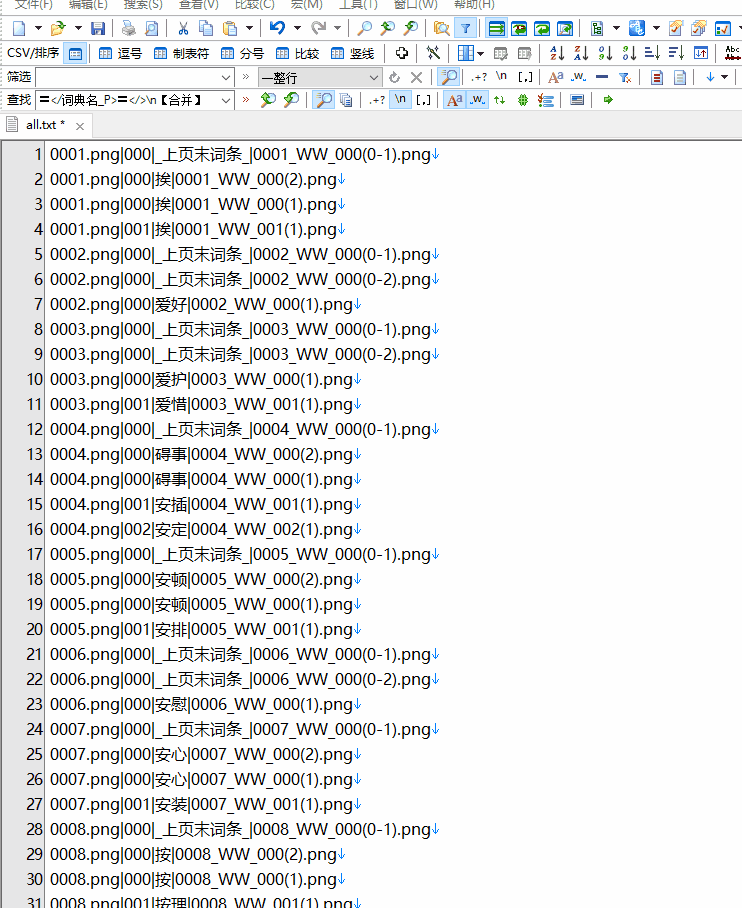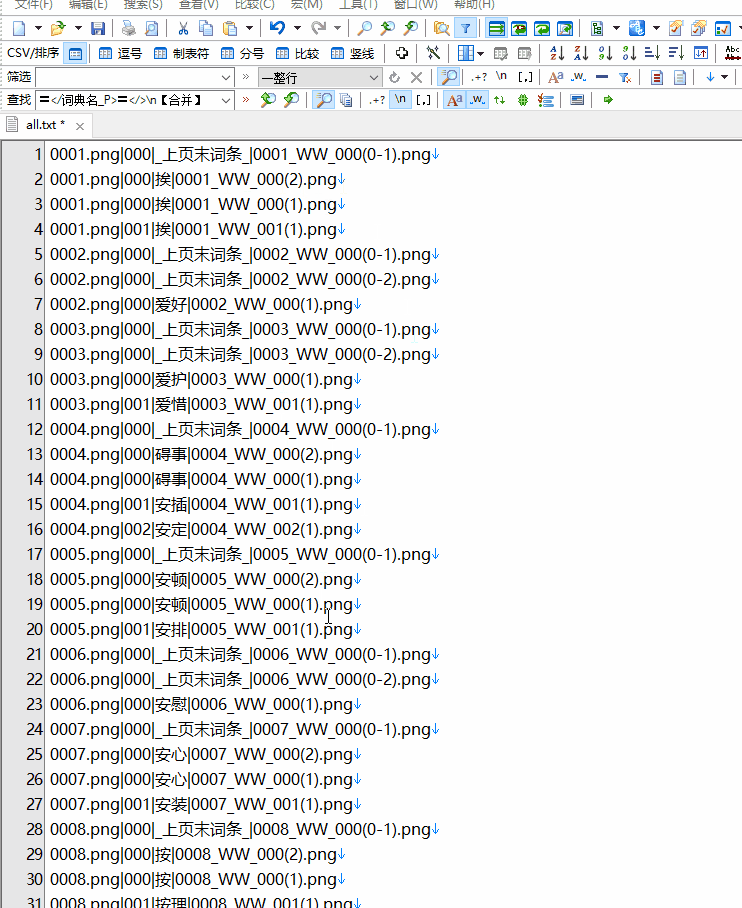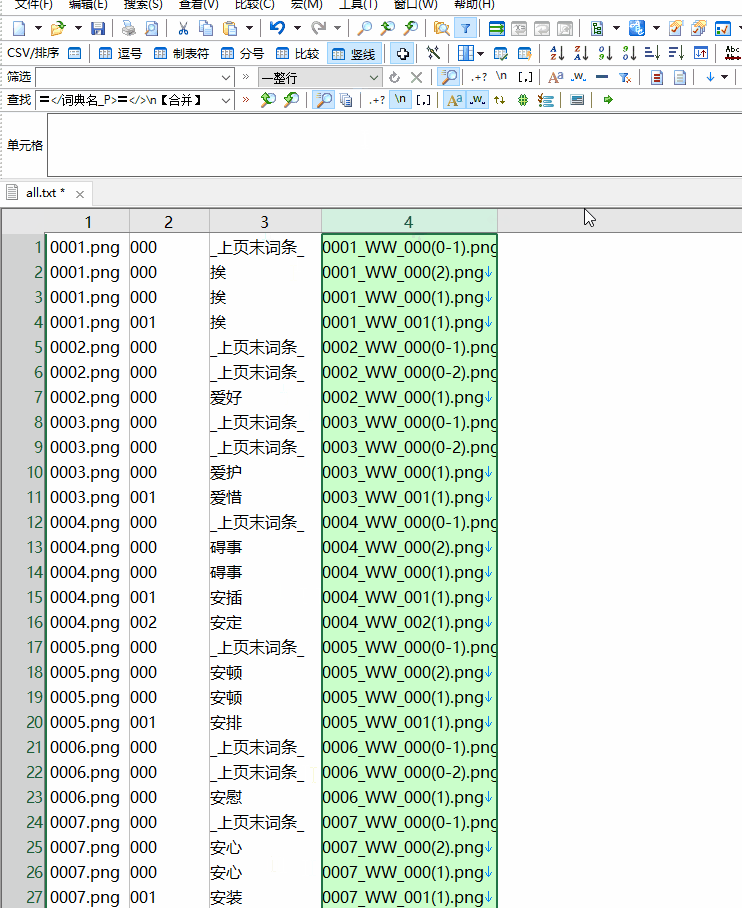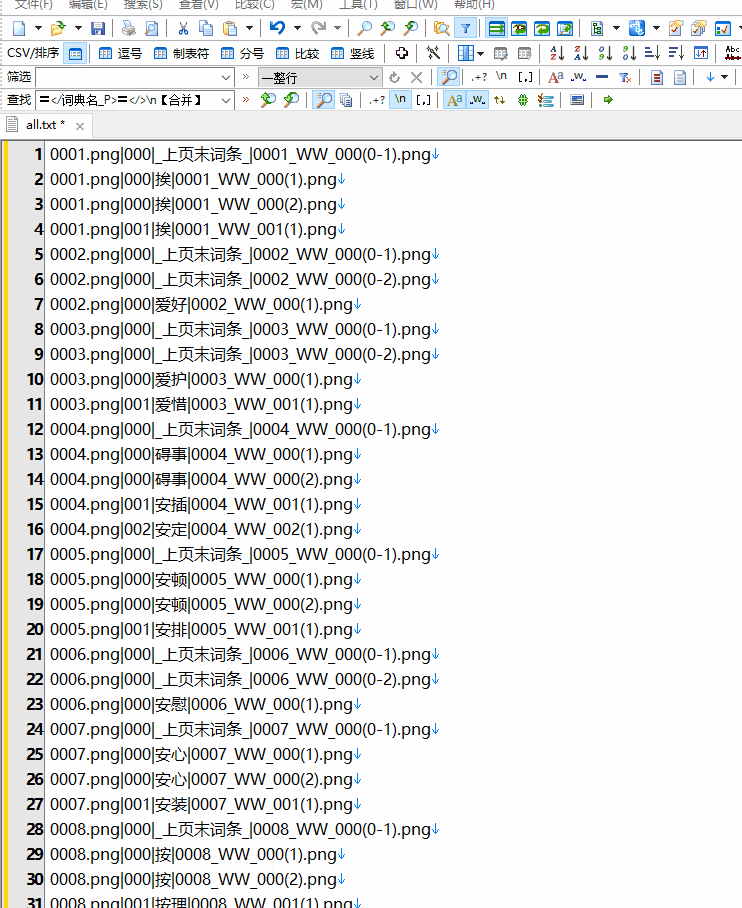
(6)合并.pdic数据倒进模板copy出文本,替换 完成
(7)合并.PWWords文件转txt完成,切词的txt替换,怎么替换不会 正看着弄呢 算完还是不算完呢
(8)解决问题中 解决 完成
(9)查找疏漏,总结。
(10)此图片词典制作方法成熟,喜欢切图词典的都可以上手制作。
以下问题都是 @ Arlin帮忙解决的,在此感谢!
1)准备图略过,相关的图片词典很多看看就知道了。
2)上来划线就频频出问题,解决方法是:单栏宽距,间隔数值的搭配,间隔数值比实际大些,单栏宽距比实际小些。
3)图片名先不要加,不然校对时无法识别页码,按下一页不跳页。
4)从PDIC导出切图信息失败,_SpecialPages里面手敲输入不规范。按照_SpecialPages示例填写 解决。
下面的可能要返工。
词头y整体要加55px,@Arlin 告诉我测试得数值*缩约比(55*缩约比)。Excel不会,百度完了怎么弄回来不会。这时呼 @dqg,解决了(EmEditor里CSV选项里点制表符,剩下的就和用Excel一样操作了,完事了再点标准模式还原初始状态,另存为.bat格式文件)。双击没变化,找帖子无解。看chigre软件使用说明,安装ImageMagick Display开切,结果是整体全往上提了相应的数值,显然不对。这时观察切出的图片单更改第二排数值还是不对,相应的第四排也得更改才是我要的切图(二排数值减多少四排数值就加多少)。测试还是不对,就改的只有词头图片的数值,其它切图保持不变才是对的,不是每张切图都要改。观察图片名字找出词头命名特点带(1)是词头文件名,剪切出去改完粘贴回来,排序。这里和软件说明不一样,@Arlin 给的:查找:^(.?)\t(.?)\t(.?)\t(.?)\t(.?)\t(.?)$ 替换:magick \1 -crop \5x\6+\3+\4 -transparent white \2 。存成.bat文件放到图片文件夹里双击。
要往上提高切图位置

导出的_file_log.txt打开处理要改的数值
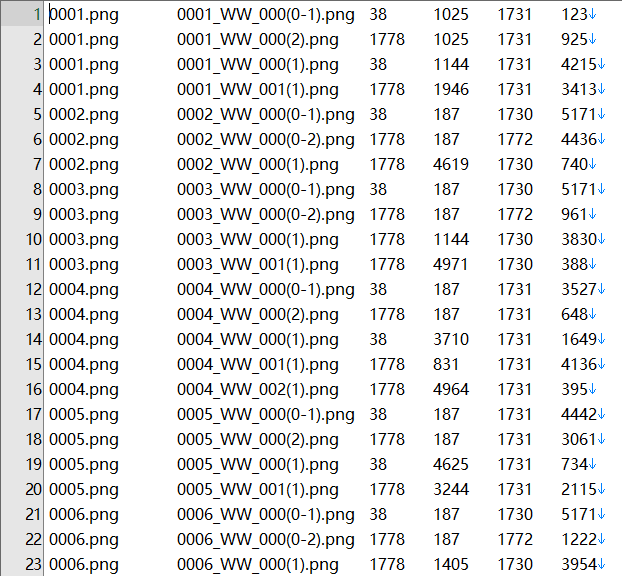
改完正则替换后保存.bat文件

要是熟练的话会很快,excel加减再粘贴回来3-5分钟可能都用不了,我却耗了一晚上。
Picture_Capture_Chigre软件导出所有图片切图信息失败找原因找了一个半小时。
导入数据至模板得文本:
打开CMD命令行, 合并所有的.pdic。
20161017_图片版词典万能模板文件夹里有说明。我只是复制出来了,还没有替换。
盘符:
cd 文件夹名
copy *.pdic all.txt
打开图片版词典万能模板.excel。导入合并的数据all.txt。
当单元格右下角出现+时双击
1)填充序列:[1]→[2]→……[9]→……[12]→[13]→[14]
这里是刷新:[9]选中W2单元格→【右键】→【刷新】
2)[13],[14]两列数据【复制】到新建文本文件,保存格式为“UTF-8无签名。
感觉在学excel表格软件,新东西上手真不快,和词典无关。最后操作了下实际时间一根烟都用不了。
又发现新问题,还是在excel里的,核对A12单元格(页数差: -X)。如果某页面无任何词条,则在[14]中不会出现,需要手动添加页码及其文本内容。要费点时间了 空白页问题解决。
也许我excel用得不对,总之复制过去的内容不对,但A列是无词条页面所缺的页码。复制出来改造好后复制到14下面(13,14已万能模板_替换步骤替换完),整页版的完成(压mdx前词典名统一替换下字母缩写)。实验品初步做出来了

无词条页面所缺的页码

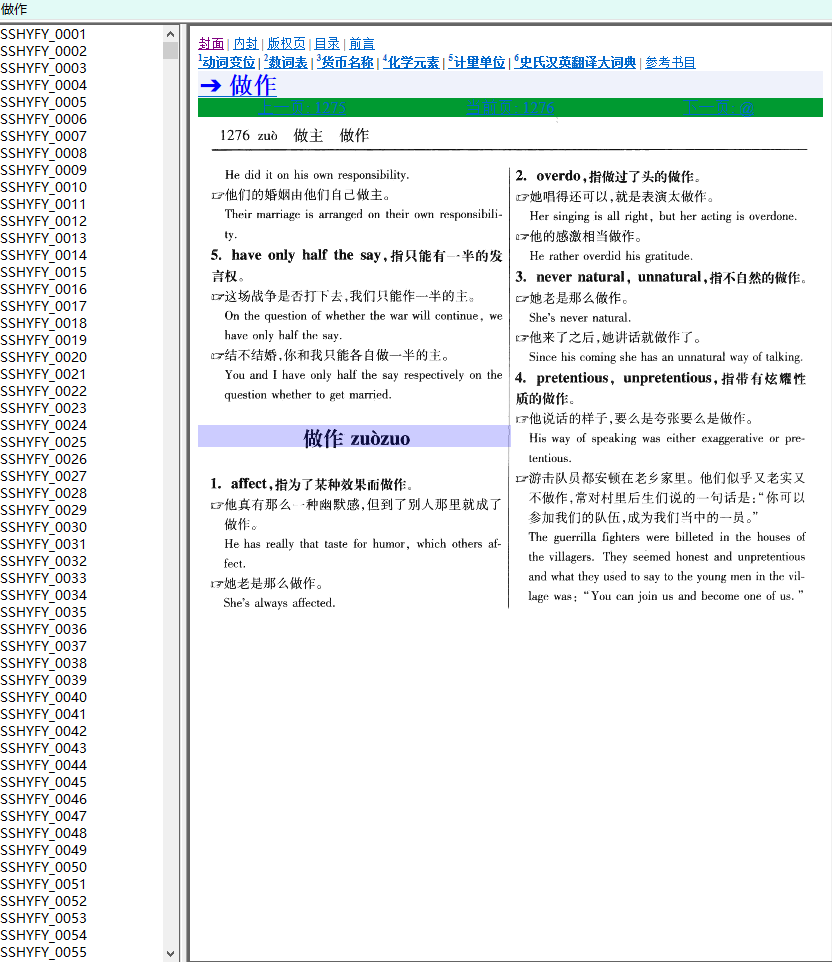
粗糙版完成,切词有问题,顺序不对,看不懂。正了解中。 已解决
@Arlin
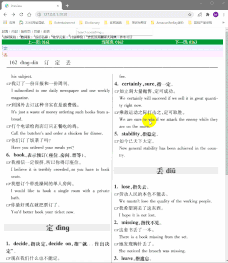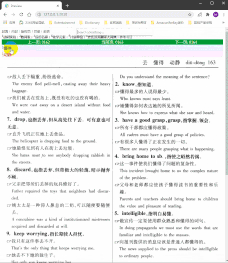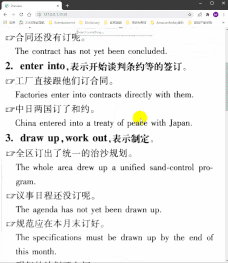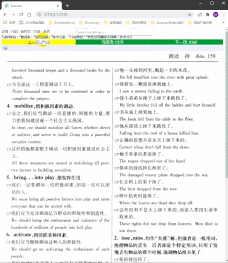
Q:如何按词目整合切片? ( dqg)
A :我的做法是,将页码结合切片类型数字作为排序依据按照数字升序排序,除(1)外的并入(1),即可与词目一一对应。无插图、重复词目不合并的情况下,双栏词典切片顺序为:
(1)(0-1)
(1)(0-1)(0-2)
(1)(2)
这些东西是神马玩意呢,再看看想想吧。


原GIF挺清晰的,不知道传到这咋就这样了。
看图吧,但雏形已经全在了,整页版无问题。单双栏大小屏切换无问题。
切词的顺序无问题(如何按词目整合切片?)
最后问题还是出在切词的_MDX.txt里。
最后的问题我又按说明里替换了下切词的_MDX.txt。问题依旧在。

GAME OVER
@Arlin 告诉按模板正则替换(切词txt和复制出来的13去重词头,内容合并就完事了),太晚了,明后天有时间替换完,就差最后还有1/3没替换完,怪不得给我的模板是一直行的,替换方便,模板断行的看着方便,直行的用着方便。
2020/08/20下午开始PDF导出图,到今早上把昨晚剩余的替换完,调整下多义词。到今天早上也就是25号早上基本完成。
词头(1985个,其中含14个多义重复的)
本贴为练习帖子,熟悉全部流程。目前发现问题是首页多义字“挨”切词再切换整页高亮页面不灵,漏划线“编”。这个切图软件使用还未试过抠图这个功能,有时间周末看看怎么使用。其余的如何使用基本都走了遍。挺好用的制作图片词典工具。
漏划线的

其它的使用无问题(只指制作出来使用上)。
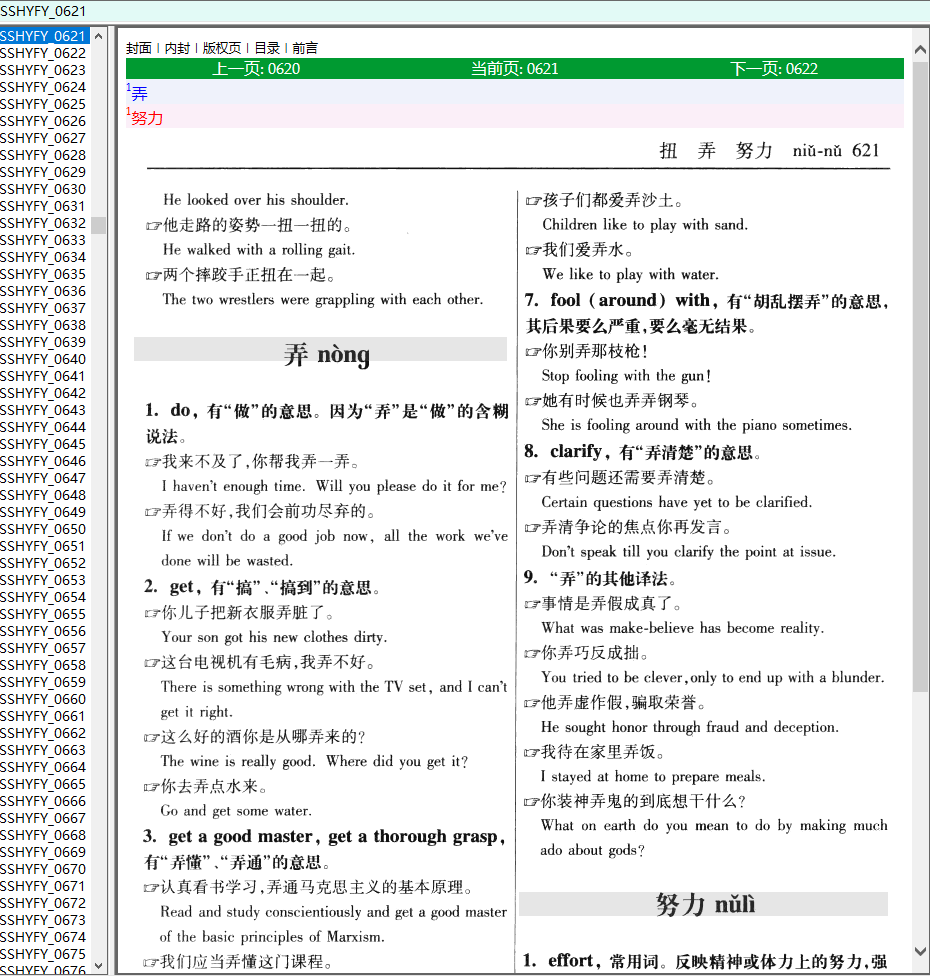



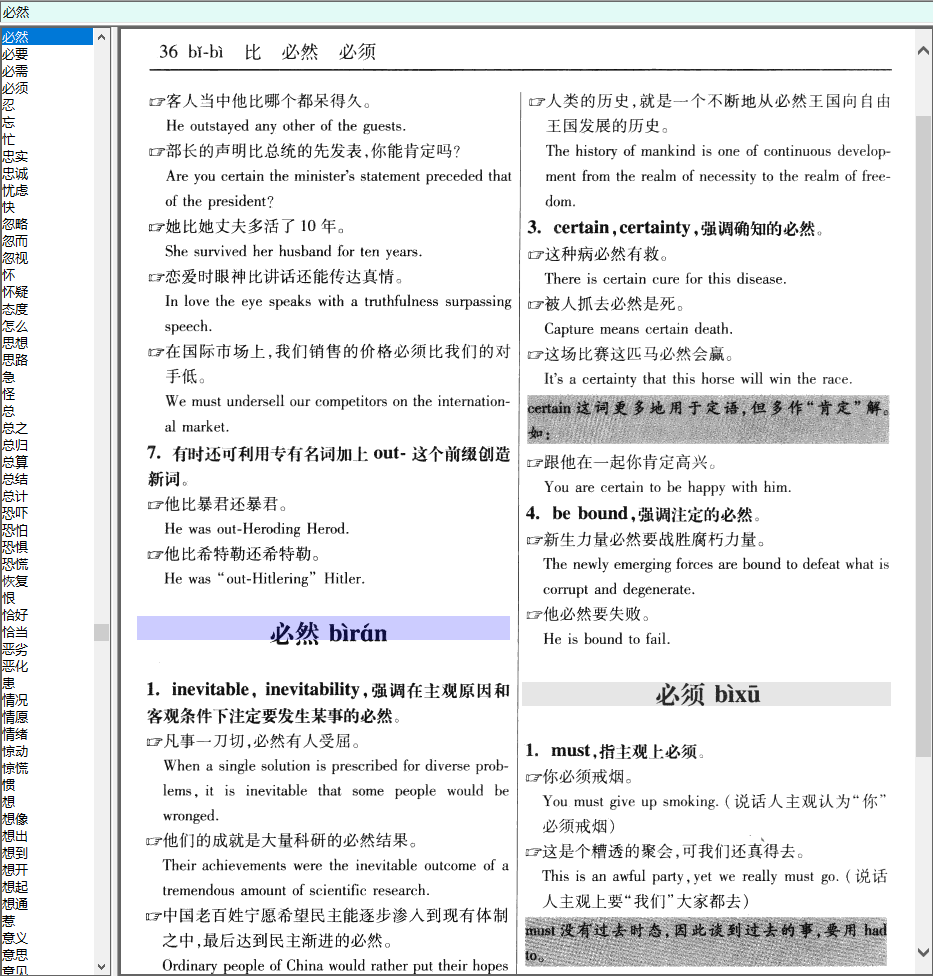
本实验制作贴到此结束,感谢过程中解惑,答疑的论坛小伙伴们。
发布初试版,已知问题:
1)由于手摘多义词“挨”字有些问题
2)就…而言(语)这种词头是作为@@@LINK处理(未处理,@Arlin建议,我想了想才明白啥意思)
3)漏划线字”编“等。因为没有进excel表格校对。
以上问题周末有时间再完善。
纠正制作中问题
编 0039
当中 0143
挡住 0143
发表 0188
发生 0196
掠夺 0547
*怕 0627
要紧 1067
要命 1067
要是 1067
漏划线词头,带星号的是划线了没有填词。
在合并pdic时就可以发现问题。漏划线的问题一目了然。
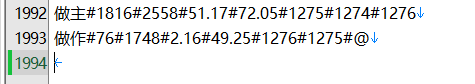
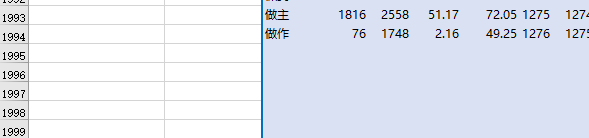

词头完整版,(就…来讲(说))吧,弄成@@@LINK)手摘后更新mdx。
链接更新于9/9号