喜欢该词典的可以
- 写写 css
- 找找图片地址(官网、app、pdf), 更多信息查看 Vdict 图片数据的地址
<span class="zgysbkcd_img">TP077.TIF</span>
- 核对pua
{
"": "",
"": "",
"": "",
"": "",
"": "",
"": ""
}
mdx.txt (16.6 MB)
zgysbkcd.css (362 字节)
中国艺术百科辞典.mdx (6.1 MB)
感谢:
更新 css :
zgysbkcd.css (835 字节)
css 问题,这两个语义不明,可能跟图片上下位置相关:
- .zgysbkcd_pUpper
- .zgysbkcd_pLower
乱码问题,除了上楼提到的五个 PUA,还有标签形式需要转换的错码,共 189个,喜欢的可以玩善 extCodesTodo.txt (3.0 KB)
感谢提醒 pdf 数据源,方便校对。
更新 mdx,现共23606条内容。中国艺术百科辞典.mdx (6.1 MB)
优化了105个含括号词头,方便搜索,如
- 女飐(zhǎn) => 女飐
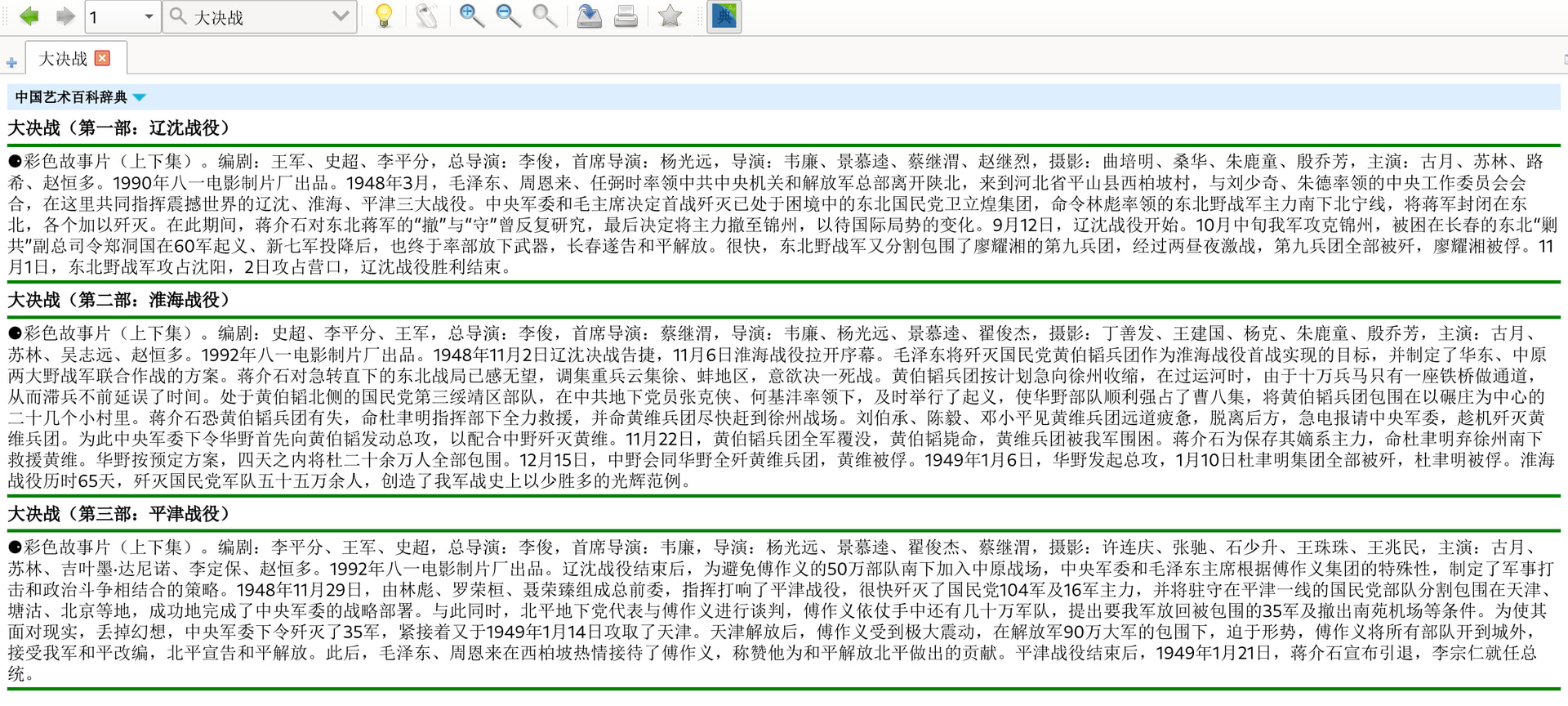
- 大决战(第二部:淮海战役) => 大决战
- 中国古代音乐史料辑要(第一辑) => 中国古代音乐史料辑要
你的私用字解决了吗?
我可以看一看。
顶楼的mdx文本是旧的吗?是否得解开底下新的mdx来看?
假如问题已经解决,我就不看了。
我不擅长做研究,新旧 mdx 都是对的数据,新的只是添加了词头方便搜索。
上面俩文件:一个是源数据、一个是错码替换表。这个核查要盯着屏幕好半天,听很多人说挺费眼的  。
。
slgns
7
多年前收到过这本辞典的文字版mdx,当时也尝试把PUA字变成Unicode,发现其中有一些无法输入的字。很可惜,貌似现在还是不行。例如这个

或许是我能力有限,只会用部件检索,不知道有没有高手可以找到。
extCodesTodo.txt中的错码字已输入,见附件。
extCodesTodo.txt (3.8 KB)
其中:
20AD1、E101、E34D原书所用类推简化字未找到,暂用繁体字。
E392、5795在原书中为同一字的不同字形,前者上下结构,后者半包围结构,现录入为同一字,实际呈现字形将随设备字体变化。
10个Unicode未收入汉字,用“字形描述符+部件”的方式表示,并以方括号区隔出来,如“[⿰赤曷]”
在处理PUA字时发现有漏掉的错码字。PUA字情况如下:
{
“”: 应删除,
“”: 应删除,
“”: 应删除,
“”: “䥽”,
“”: 在extCodesTodo漏收错码字前,
“”: 在extCodesTodo漏收错码字后
}
匿名1722
11
没错,目前我发现的就是这个情况,希望没有其他漏网的
匿名1719
12
第一批错码中,这三个好像用的PUA
"E345": "",
"E35B": "",
"E35D": "",
匿名1684
13
这三个确实是PUA,眼花了。
按照之前的处理原则,应该是:
“E345”: “[⿱大夕]”,
“E35B”: “䌳”,
“E35D”: “鑃”,
匿名1719
14
哈哈,让你干这么多活。
更新,合并第一批错码处理:中国艺术百科辞典.mdx (6.1 MB)
第一批错码合并,方便有人需要核对,感谢 匿名1684 已核对。extCodes_o2n copy.txt (3.8 KB)
现在未解决问题
匿名1684
15
对照实体书找了之前贴出的第二批乱码,情况如下,碰上硬茬了。
"NBD6E": 原书第633页“花衣”条内容为:参见”吉服“,未见乱码所在的这段释文。
"NB044": 原书无该乱码所在“南宋纹绫”条,
"NF8BC": 原书无该乱码所在“明洒线绣金龙百子戏女夹衣”条,
"NB55D": "𫔎",【注意】该乱码所在文字段落与前段重复,后面多的一句“图19朝鲜民主共和国古乐浪遗址出土汉代带扣”为原书插图说明(数据缺)。
"NE2B3": 原书无该乱码所在“东汉织锦”条,
"NE067": 原书无该乱码所在“丝绸”条,
"NFEC1": 原书无该乱码所在“丝绸”条,
"NC728": "纻",【注意】原书无该乱码所在“明代纻丝”条,此处据条目推测。
"NB24B": 原书无该乱码所在“明代织花纱”条,
"NFEF7": 原书无该乱码所在“织金绢”条,
"NB073": 原书无该乱码所在“南宋纹绫”条,
"ND047": 原书无该乱码所在“南宋纹绫”条,
"NBB7D": 原书第558页“麻布”条释文中,无该乱码所在的这一句话,
"NE158": 原书第558页“麻布”条释文中,无该乱码所在的这一句话
手头的书是2004年1月第1版,2009年12月第2次印刷的。不知道其他印次的是不是不一样
匿名1719
16
意思是 纸质书 缺失了私有字的的句子或词条?是因为不好打印吗
从阅读的角度看,可以根据语义替换字。比如头两个字。
从整理商务印书馆私有字符的角度,这样替换有些粗糙。
{
"NB044": "",黄【NB044】墓出土的衣物中, => 百度得福州【黄昇墓】
"NB073": "", 淳【NB073】三年(公元1243年)=> 百度得【南宋淳祐】
"NB24B": "",
"NB55D": "",
"NBB7D": "",
"NBD6E": "",
"NC728": "",
"ND047": "",
"NE067": "",
"NE158": "",
"NE2B3": "",
"NF8BC": "",
"NFEC1": "",
"NFEF7": ""
}
南宋淳祐
{
"NB044": "昇",
"NB073": "祐",
"NB24B": "",
"NB55D": "𫔎",
"NBB7D": "",
"NBD6E": "",
"NC728": "纻",
"ND047": "",
"NE067": "",
"NE158": "",
"NE2B3": "",
"NF8BC": "",
"NFEC1": "",
"NFEF7": ""
}
匿名1719
17
为了可阅读性,暂时替换未知错码字为问号。
中国艺术百科辞典.mdx (6.1 MB)
暂用错码字映射表
{
"NB044": "昇",
"NB073": "祐",
"NB24B": "🯄",
"NB55D": "𫔎",
"NBB7D": "🯄",
"NBD6E": "🯄",
"NC728": "纻",
"ND047": "瑀",
"NE067": "🯄",
"NE158": "🯄",
"NE2B3": "🯄",
"NF8BC": "🯄",
"NFEC1": "🯄",
"NFEF7": "🯄"
}
与隔壁《新华惯用语词典》冲突,两个词典包相互覆盖。。。
没查到《中国艺术百科辞典》有别的版本。
我猜测是商务为了数据库本而做的少量内容增订。
没几条,可以研究推定内容,在词条最下方加校记。
大臣在此期内亦停止递遣疏及请NBD6E等事,
清稗类钞/104 - 维基文库,自由的图书馆
Wikipedia
https://zh.wikisource.org › zh-hans › 清稗類鈔
2016年12月28日 — 】〉花衣期内,官署皆停止刑事。大臣递遗疏及请恤等事
NBD6E=恤
我推测是“恤”的异体字“䘏”。就用“恤”字可以。
匿名1719
21
两词典相同的词头有
担担子
搭架子
跑龙套
挑大梁
喝倒彩
七郎八虎闯幽州
龙虎斗
借东风
鸡毛飞上天
闯江湖
没看到冲突,用的隔壁帖的 新华惯用语词典 版本,不清楚其他版本的冲突情况。