想通过百度OCR制作这个词典的文字版和图片精准定位版(类似OCR后的PDF,可以通过ctrl+f定位词头位置)。
参与方式:私信提供百度OCR免费500额度的API Key和Secret Key,用于制作mdx
分享方式:制作完成先在提供api key的同好之间小范围试用,1个月后公开分享
2024.6.2 初步测试:
想通过百度OCR制作这个词典的文字版和图片精准定位版(类似OCR后的PDF,可以通过ctrl+f定位词头位置)。
参与方式:私信提供百度OCR免费500额度的API Key和Secret Key,用于制作mdx
分享方式:制作完成先在提供api key的同好之间小范围试用,1个月后公开分享
2024.6.2 初步测试:
你先PDF文档正文部分进行分栏裁切,用ABBYY编辑器擦除天头地脚边栏等等无关部分,我用夸克扫描和扫描全能王帮你导出简单文字txt
我这边不需要分栏裁切哈,页眉页脚也不需要擦除的,会自动屏蔽掉这些内容
相信我,同行不同栏的文字内容会羼乱在一起,到时候白辛苦一番了,后面要分拣归整也不好做
测试了6页,暂时没发现有这个问题
有四五处这种情况,手动修改了下
文本质量看着很好,只用的百度吗?
嗯,用的百度高精度位置版
这就已经很说明问题了。不多一道工序进行分栏裁切,得出的ocr识别文本很难真的按栏线截然区隔开来。而且之所以言之再三需要用多个识别工具进行同异互校,就是为了能尽可能地把ocr错讹字符筛滤出来加以订正。慢工出细活,不用水磨工夫做出来的半成品就像白石皓皓君说的徒然诖误来学罢了。另者,精校文本还有一个好处就是可以进行二次利用,就比如作为训练语料挂载模型进行类义成语划分。
制作文字版切分栏后OCR肯定是最佳方案。不过也意味着 extra work,比较繁琐。p.s. 三栏怎么切我还真不知道用什么工具
两边测栏切掉大约可以用老马的工具。
p.p.s 切分栏以后图片数量暴增到6000多,接近7000
这得花多少OCR费用 ![]()
分栏裁切用金山pdf,我用着挺顺手的。就看你是抱持什么心态做这个项目的,你用的百度高精度位置版调用api按量给费小文本量还可以,需要识别的页面多了还不如用商业APP嘞,更为上算。时间都花出去,不追求效果还不如不做。
一键 ocr 的 umi-ocr 、 easyocr ,每个人都可以切,用每行四个角坐标统计出分栏坐标。
还可以分类成奇偶页,指定 1x+2y 最多6个值,硬编码切栏(有风险)。
问题在于,谁有空做呢。 楼主做了,很棒了。![]()
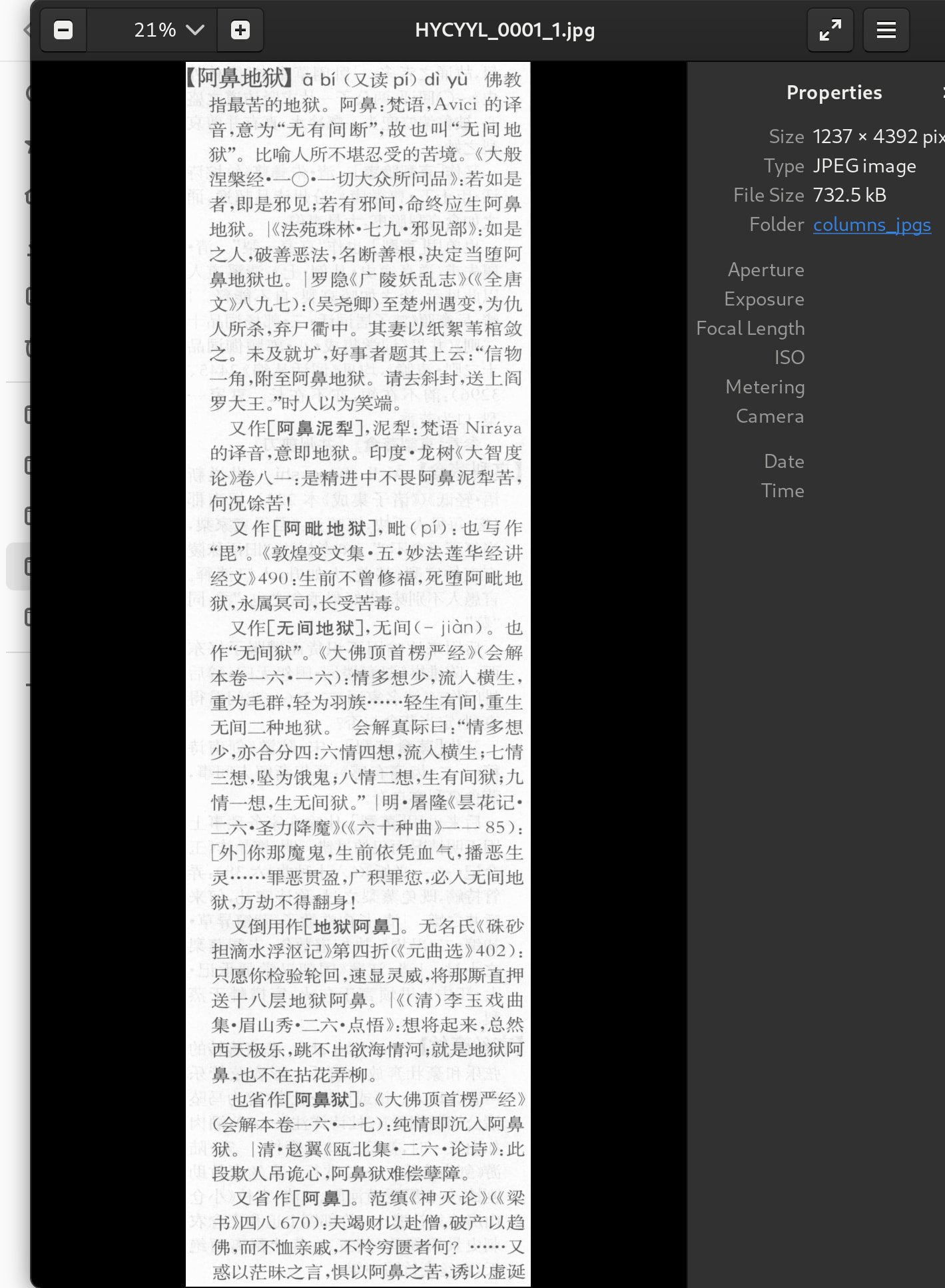
已完成分栏切图,部分页面天头有遗留(笔画索引、征引书目没有),请注意检查有无错切。
我之前做过现代汉语词典,就靠手动裁切,一页一页搞,那么才算是费了姥姥劲儿。现在都依赖半自动化、自动化工具,快是快了,但没认真复核一遍,真不敢用
今晚或明天我解压瞅瞅
特点:切掉正文四周、页中竖线、章节ABC
用处:进一步制作准确文字版的OCR;制作干净切词版对照。
下载地址:Gofile - Cloud Storage Made Simple
缺点:
切栏代码、源材料:
你这是哪里来的图源,为什么总体积这么大,比我解压的上楼匿名老哥的图片文档压缩包大了很多。合合的扫描全能王现在应用起来限制很多,图片还得转成pdf拼接在一起,一次扫描页数上限原则上是100页,但是如果PDF文档过大也会强退导致任务失败
图片原材料来自 该帖 汉语成语源流大辞典 修订版 一楼 mdd.1 + mdd.2 的6楼转载,大小为4.6G。
处理图像时没有指定额外参数,全是最简单的默认调用,py pillow 读入数据后切割后应该是默认输出没有压缩的太狠,导致比原体积大,比原来 4.6 G大了 0.8 G。 觉得体积会有影响 OCR 的话,可以选自己熟悉的工具再压缩、二值化、像素转svg等减小体积。
实际上两种图源的图档OCR扫描文本差异可能不会很大。如果仔细对照一下,会发现各有优缺点。哥你裁切的很完美,边栏、天头、侧边的一些ocr干扰元素诸如页码、拼音、字头、分隔线都妥为切除。美中不足的是纸背透字,显得纸面字体有点发虚 ![]() 总归而言,就是图源、图档体积上有点缺憾。不过利用编程工具进行页面裁切倒是一大创举,感觉比手动裁切会省力方便许多,所需的就是人工复核的一点时间。
总归而言,就是图源、图档体积上有点缺憾。不过利用编程工具进行页面裁切倒是一大创举,感觉比手动裁切会省力方便许多,所需的就是人工复核的一点时间。