前段时间接触了一点CAT(计算机辅助翻译)的技术,试着做了一些tmx(翻译记忆库)文件,用Xbench来检索,体验非常不错。
快速参考见:https://download.xbench.net/ApSIC.Xbench.3.0.UserGuide.ZH-CN.pdf
详细一些的见YouTube上的官方教程,这里推荐优先看看高级搜索(Power Search):https://www.youtube.com/watch?v=UuqJDVWF9Bk
它的搜索功能最大的优点是能够同时设定源文和译文之间的搜索条件,对各种搜索语法如或(放在引号内用or分隔),且(空格分隔),非(-号)的支持也很棒。其高级搜索大致说来就是检索词不必连贯出现,可以说是模糊搜索?
举例说说消极搜索。写作和翻译的时候经常会需要替换用词,丰富表达。最简单的做法当然是找thesaurus。
但如果手头有tmx格式的例句库的话,其实可以用xbench自己做一个:
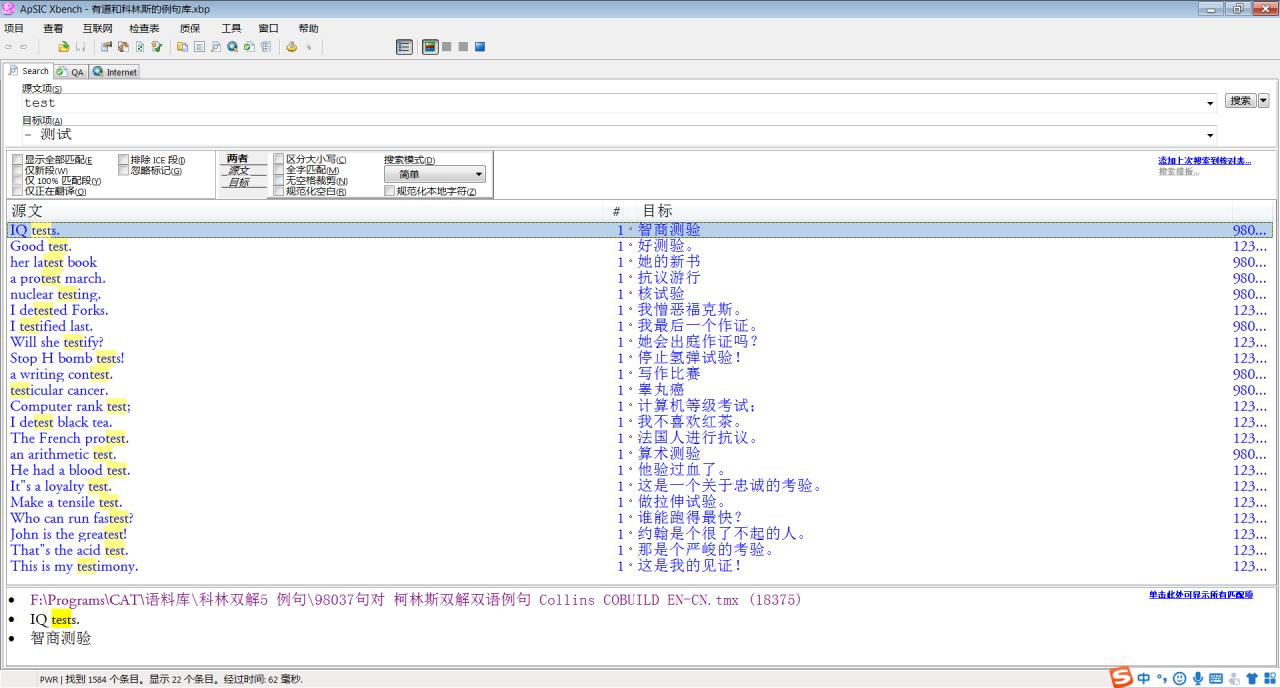
已知test一般翻译为测试,那么我要找“测试”之外的可能性。那么先在源文项输入test,在目标项输入测试,然后在前面添加 - 这个符号。“-”和“测试”之间的空格可以省略。然后点击搜索处的高级搜索,得到以下结果:
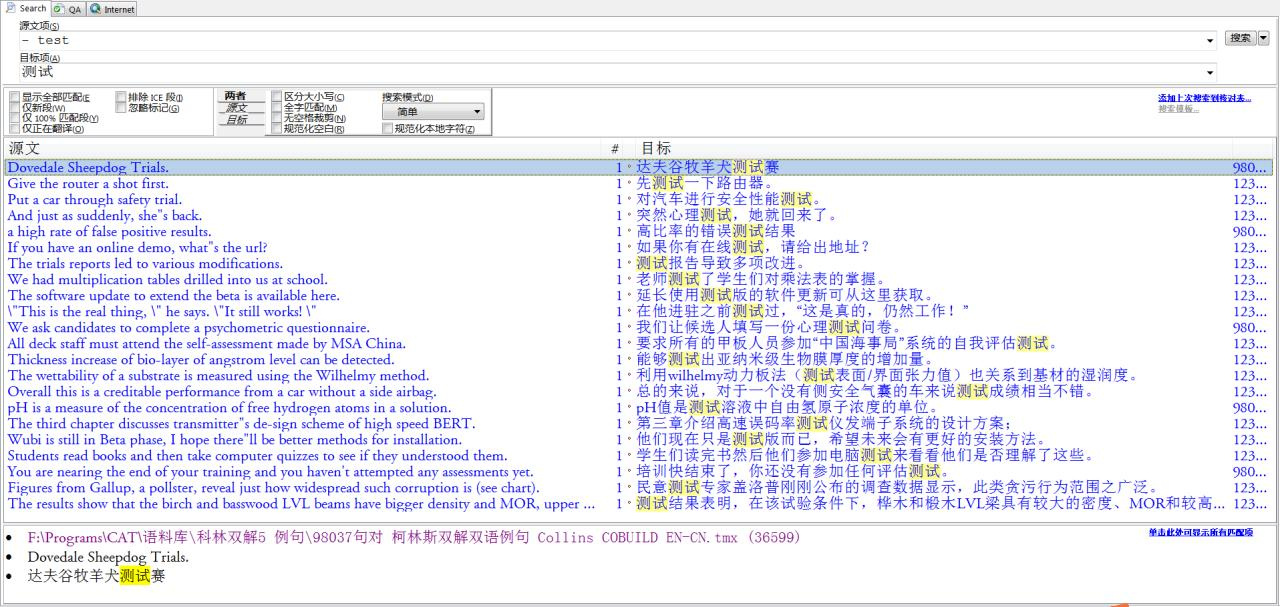
反过来,如果我想知道能够翻译为测试但原文并未出现test这个词,也可以反向操作:
其他诸如搜索多个词汇同时出现的情况,也可以用高级搜索完成,只要检索词之间用空格分开。
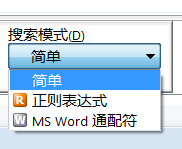
除了高级搜索,“搜索模式”还支持正则和通配符:
搜索的结果可以按ctr+q导出。
GoldenDict支持全文检索,但不能支持词头和词条同时设定搜索条件。
一个想法是:只要能把mdx转化为tab分割的文件(词头一栏,内容一栏),就能把它转化为tmx的格式——从这种格式到tmx,只需要用GlossaryConverter转化一下就完成了。
不知道有没有脚本能实现这种转换?可能这也是个异想天开的想法,期待讨论。
也欢迎提出任何强化mdx词典检索可能性的想法。
放上有道的中英英中tmx文件供大家探索:
Uploading: 123450句对 有道词典例句记忆库 CN-EN.rar… Uploading: 123494句对 有道词典例句记忆库 EN-CN.rar…