常见的 PDF 有两种,一种是文字版 PDF ,是矢量的,这种 PDF 在使用上可以无限放大,都不影响清晰度;另一种是扫描版/图片版PDF ,是由纯图片生成的,PDF 中的每页的构成元素就是一张大图(当然也有可能OCR加了文字层),就是普通的图片,和在图片浏览器中看图基本是一样的。
文字版PDF尽管使用很方便,但有时候我们也想把它转换成静态图片导出来,做成词典或重新封装成图片版PDF来防篡改。
文字版 PDF 要导出成图片,需要经过一道转换,按我的理解是“打印法”——也就是先按某一分辨率渲染再按像素点转换成图片,自然这种方法一定是“有损”的。
对于文字版PDF转图片,各种导出工具都差不多,没什么特别的,导出的图像质量主要取决于 DPI 参数,也就是渲染的分辨率高低。
图片版 PDF 由于每页中的元素直接就是图片,因此要导出图片很简单,就是把它们“提取”出来,这也正是图片版 PDF 导出图片的最佳方法,因为没有经过转换过程所以是可以达到无损的。
当然图片版 PDF 同样也可以按“打印法”的方式导出图片,这样导出的图片就不是原来的图片了,是有损的,图片质量大概率下降,但也有可能保持原来差不多的清晰度,那就是尽量加大导出图片的 DPI,只要超过原图的 DPI,那就可能保持原来的清晰度,但这带来的后果会是导出的图片体积大幅膨胀(可以做二值化等二次加工来重新降体积)。
所以,对于扫描版/图片版PDF,建议优先使用“提取”的方法。提取还原图片的过程中可能还会经历解压缩过程(生成PDF时有压缩图片减小文件体积),主要是 png/tiff 格式的图片,jpg/jpeg 一般则不需要解压缩直接提取。最常见的两种无损压缩算法分别是 CCITT G4 和 JBig2 ,其中 JBig2 对于黑白图片的压缩率很高,因此常用在扫描版 PDF 中 ,它是 Adobe 的独家算法,不过后来似乎开源了(或是被逆向了?),有个叫 jbig2dec 的项目(MuPDF所有)也可以实现这种压缩和解压缩。
除了 Adobe Acrobat 外,目前个人已知使用了 jbig2dec 从而支持 JBig2 算法的软件有:MuPDF (解压、压缩),FreePic2Pdf (压缩),PDFPatcher (解压),PdfToy (解压、压缩)
FreePic2Pdf 没有从 PDF 导出图片的功能
其中 PdfToy 是付费软件,因此 PDF 导出图片优先推荐免费的 PDFPatcher 、mutool (MuPDF)。
由图片合成 PDF 得到的自然是图片版PDF,要想合成 PDF 的文件小,除了图片本身要尽量小外,另一大重要的就是压缩算法,CCITT G4 和 JBig2 都是无损压缩,对于黑白图片,后者压缩率更高,使用广泛。
Adobe Acrobat 的“合并文件”功能默认使用的应该是 CCITT 压缩算法,而没有用 JBig2,不清楚怎么开启
因此,要从图片合成 PDF,同样也推荐上述三款软件 FreePic2Pdf、PDFPatcher、-PdfToy
PDFPatcher 合成 PDF 似乎没有去使用 JBig2 等高压缩的算法,导致生成的 PDF 体积较大
其中 mutool 、PDFPatcher 均无法指定压缩算法,而 PdfToy 是付费软件,因此合成PDF优先推荐 FreePic2Pdf (压缩后的pdf还可无损还原成 pdg)。
目前仅知 Pdg2Pic 支持这种转换。
非专业人士,水平较低,仅个人经验总结。有不错的工具或方法,欢迎大家留言补充,集思广益
6 个赞
leoleo
2023 年11 月 17 日 16:33
3
写错了,才看到。是 mupdf。
2 个赞
指的是 mupdf 吗,也是有命令行工具 mutool
查了下,还真有 mdpdf
PDF补丁丁,提取结果我测试倒没出现问题,并且由于纳入了 jbig2dec 的原因提取 jb2 压缩的 PDF 的话,效果是很不错的,这一点可以媲美 PdfToy
1 个赞
对于读秀 pdg 来源的扫描书,pdg → jpg/png → PDF 以及逆向还原 PDF → jpg/png → pdg 这整个循环,用老马的工具 Pdg2Pic+FreePic2Pdf+PdfToy 可以完美满足;但如果没有 PdfToy 的话,用 Pdg2Pic+FreePic2Pdf+PDFPactcher 也可以替代(只有 jpg/png → pdg 最后这一步无法实现)
如果非读秀来源的扫描书,灵活性则更高些,都可以尝试
1 个赞
对哦,我记错了,是把 jpg/png 转回 pdg
random
2023 年11 月 21 日 03:58
10
pdftoy导出图片的时候,可以指定图片格式吗?它经常自动导出为tif格式,但想让它导出png格式。pdf patcher 就可以指定导出的是png
Vim
2023 年11 月 21 日 04:03
11
我猜测pdftoy的默认模式是,判断原始的图片,选择最佳的格式。
但也是可以指定格式的:
1 个赞
hkcn
2023 年11 月 21 日 07:10
12
PDF提取成图片个人只用过PDFPatcher和PDFxchange,前者用不惯已删,后者操作比较方便。
1 个赞
random
2023 年11 月 21 日 10:28
13
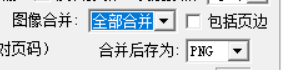
设置了“全部合并”后,还是导出了tif图片,不知道什么原因
我是用 xpdf 内的 pdfimages.exe 导出图片。
1 个赞
Vim
2024 年1 月 8 日 09:00
16
Mandolin:
mupdf 吗,也是有命令行工具 mutool
还有同一家族的 PyMuPDF ,用python就方便了。
OCRmyPDF + img2pdf 也可以实现将多个图片合成PDF,并OCR嵌入文字层。使用下来,比FreePic2Pdf + MODI_Engine 组合更好,而且可以与其他python组成新工作流。
OCRmyPDF 还可以直接在图片PDF中添加文字层,比传统的先解包pdf为图片、再OCR并重新生成带文字层PDF的方法更简单。
3 个赞
目前 automdxbuilder 里有集成 pymupdf。OCRmyPDF 看上去不错,后续有机会研究一下
random:
准确率如何?与abbyy,acrobat比的话
使用的引擎是 Tesseract OCR ,应该可以调教
2 个赞
Vim
2024 年1 月 8 日 15:36
19
random:
准确率如何?与abbyy,acrobat比的话
没对比过,从没用过abbyy和acrobat的OCR;我自己使用,感觉足够强了。
关键不是一个层面的东西,免费、开源、可编程,这就让我们有各种可能的应用,基本可以嵌入我的每日工作中。
2 个赞