由于本人和同学工作都比较繁忙,又同时都在国外,网络很差,近来才把词典搞完。特把资源分享给大家,因为阿语本身语料库就少,又没有相关词典,真的挺折磨的,不知道那位大佬会不会介意 ![]() 因为他真的很久没出现了…而且应该不会有人再拿去又搞注册码再转卖吧…
因为他真的很久没出现了…而且应该不会有人再拿去又搞注册码再转卖吧…
链接:https://pan.baidu.com/s/1bhtxbEeW9i4gj1go_G7CHA?pwd=5678
提取码:5678
然后有一个技术问题不知道论坛内有没有大佬能够解决,有一本阿汉高阶词典,根据本人的经验,这本词典才是使用率最高的,其他的我其实都没咋用…这本是mdxbuilder4.0创建的文件,我和同学把mdx文件的注册码消除后,发现这个mdd文件解压不了,我在网上搜了搜解决办法,找到某论坛的一位仁兄让他看看,他说解压的时候显示内存不够,不知道论坛里有没有大佬能帮帮忙 ![]()
![]()
这是阿汉高阶词典的资源链接:https://pan.baidu.com/s/1vsxqoamH_MbiLUwhS-x0Ww?pwd=1234
提取码:1234
本人设备码C8922438-B07DC00B-7557358E-63E1C1A9
5 个赞
读取 v3 格式的代码有问题,阿汉高阶词典的 mdd 可以提取文件,但从 mdx 的文本看解压出来的文件数量不完整,需要找 xiaoqiangwang 这个作者反馈,我不知道如何联系。
很感谢楼主可以提供这么珍稀的资源,冒昧地想请求下词典图标,多谢!
好可惜,只有mdict可以用,解包出来的文本能否用mdxbuilder3.0打包呢?可以兼容更多软件。
抱歉,这个我好像没有…
我是完全看不懂的 ![]()
![]()
![]() 只能求个大佬解决问题,造福阿语圈了
只能求个大佬解决问题,造福阿语圈了 ![]()
MDict v3 格式我没有看过,这个问题必须联系 mdict-analysis 的原作者 xiaoqiangwang ,他亲自来才能解决,除了他之外,我不知道还有谁分析过这个新格式。
总共 1.68G 的图片只提取到 32M 就报错了,没什么用。
data.zip.001 (4.8 MB)
data.zip.002 (4.8 MB)
data.zip.003 (4.8 MB)
data.zip.004 (4.8 MB)
data.zip.005 (4.8 MB)
data.zip.006 (4.6 MB)
隔壁标题:MDict MDXBuilder 4.0 格式词典解压,里面的作者就分析过;深蓝作者在mdxbuilder 4.0 rc1出后第一时间解析过mdict V3 RC1的格式(深蓝词典app支持),后来rayman在mdx v3 rc2及以后版本换了uuid,深蓝作者就不想玩猫捉老鼠的游戏了。可以在github的pyglossay项目找到xiaoqiangwang: Update readmdict to support MDict V3 fomrat:https://github.com/ilius/pyglossary/pull/385
1 个赞
大佬 这个是解析方法吗
可以有偿解析吗
Xiaoqiang Wang之前已经公开mdxbuilder4.0的解析了:https://bitbucket.org/xwang/mdict-analysis/src/master/,用python解析就行了。你要是发现mdict v3格式提取有bug,可以在github上“Update readmdict to support MDict V3 fomrat”的帖子当中提出来,看作者有空解决没有,没有的话也不用强求
可是我一点都不懂如何解析…
不用知道解析啊,学一下python和cmd一些用法,拿现成的代码去解压mdx和mdd即可
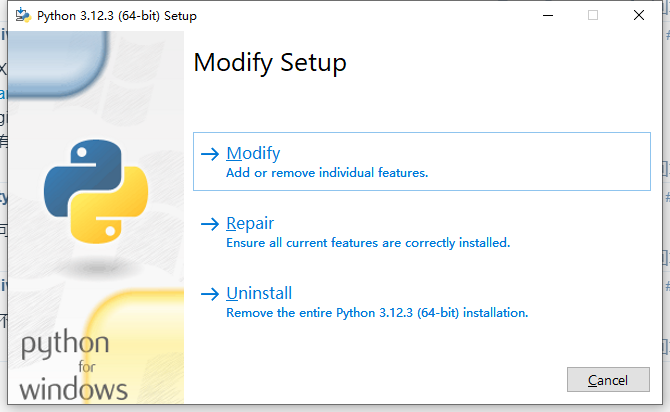
z选择哪一栏 哥
可以参考这个:# 全网最详细的Python安装教程(Windows)https://zhuanlan.zhihu.com/p/344887837
看不懂 完全看不懂 唉 看来这本词典注定与我无缘了
这个词典在其他帖子不是说导出有bug?图片有损坏
欧陆无法加载显示,安卓+欧陆,有什么办法吗?
@匿名1541 @tyl-123 @asiald 我用 MdxBuilder 3.0 RC2 重新打包了一下,阿拉伯语汉语高阶词典 - FreeMdict Cloud
我本地用 GoldenDict-ng 测试,加载和图片显示都正常。链接里有个 rtl 文件夹,里面是开启了 Right-to-Left 的版本 mdx。我不清楚要不要开所以两个都传了。
1 个赞