首先说明一下哈,我非IT相关专业,纯个人的观察,MdxBuilder 3.0 RC1(不记得哪来的还是谁发给我的)上验证有效。若有不对,请自行纠正哈
车祸现场:
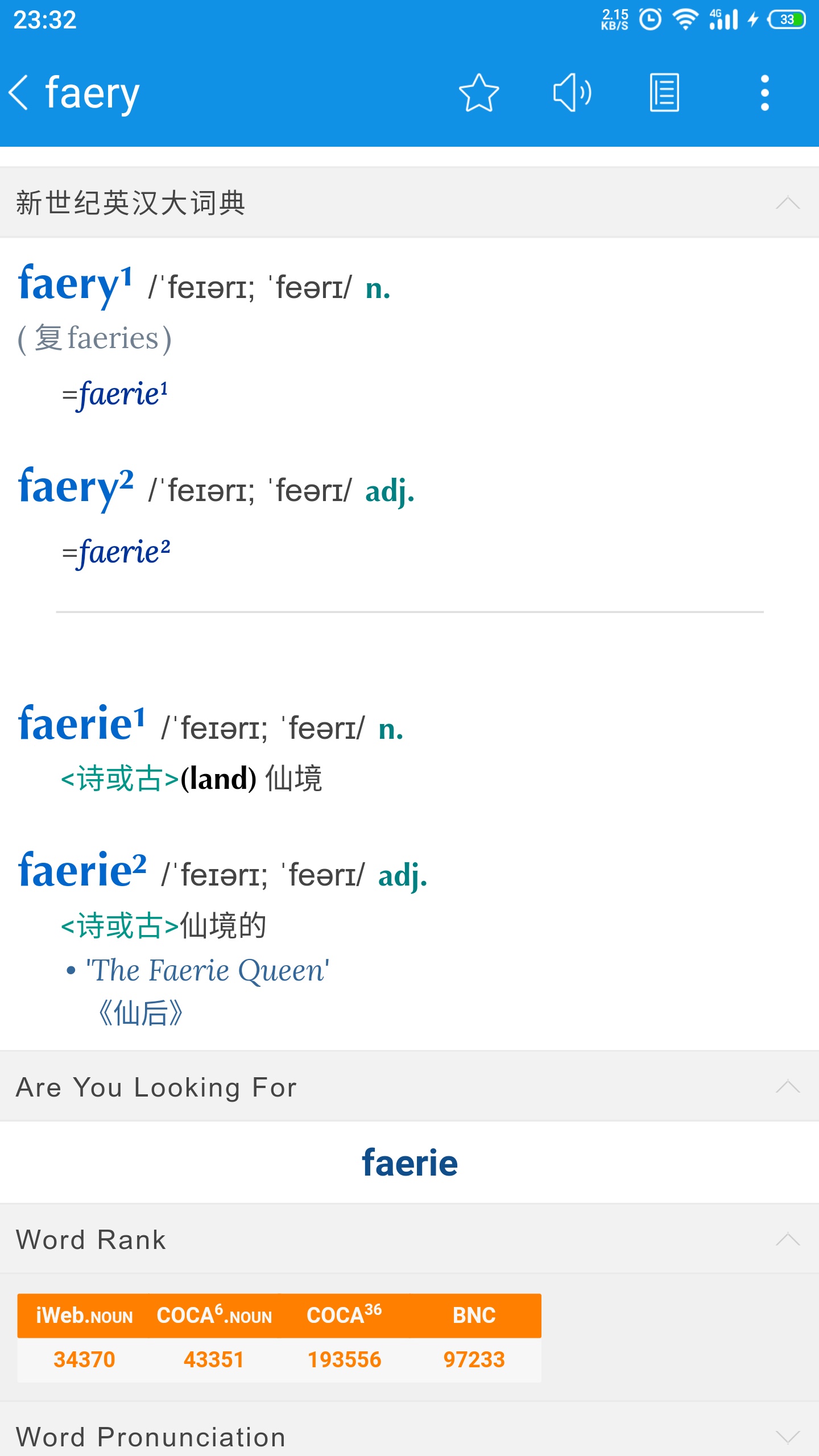
微信好友里的一位小仙女改了ID含Faery,我想在Mdict里查查什么意思,一查就崩,厉害呀!?看来查人家是不对滴
转跳原理:
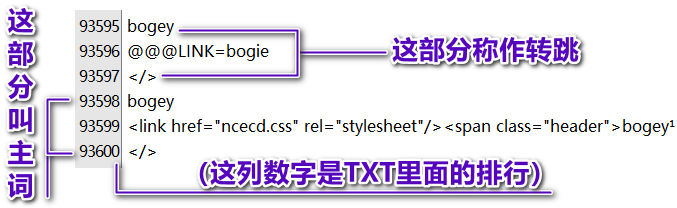
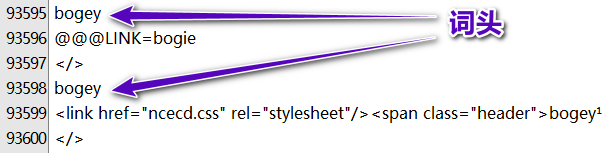
@@@LINK=后面作为词头转跳,会转跳至(转MDX前的)TXT里的第一个该词头所在的位置。
举个例子,词头aaa,其字典内容为@@@LINK=bbb,会转跳到(转MDX前的)TXT里的第一个词头为bbb那里:如果(转MDX前的)TXT里的第一个词头aaa就是@@@LINK=bbb,且该TXT里第一个词头bbb刚好是@@@LINK=aaa,则查词aaa或bbb均会死循环;如果如果(转MDX前的)TXT里的第一个词头aaa或第一个bbb,有实质性的内容(<span>…</span>等,不是转跳的),那么之后的aaa的@@@LINK=bbb、bbb的@@@LINK=aaa放在任意位置均不会死循环。
结论:
如果要扩充词头,我建议,转换MDX前的TXT里面,尽量把@@@LINK=的排在主词头的后面(譬如,全部的@@@LINK=作为一个整体,加入至原TXT的末尾),除非确定不会死循环。
这是我按照@last_idol给的统计手工修改的(把有实质内容的主词往前排了排):
外研社新世纪英汉大词典.mdx (22.8 MB)
(@atauzki原帖:新世纪英汉大 191008 改版)
我搜索“新世纪”找不到,搜索“新英汉”才能找到原帖,吐槽一下
@Arlin@hahaya@loner
好了,我发神经完了,散啦
xjw
6
mdx link的设计不是一般的糟糕,现在也没有工具去检查这些重复和循环的link
如果是原博中的图片这种情况,不是很简单的一个脚本就能排除吗?
复杂点的也有,a-b,b-c,c-a,我以前在某柯林斯词典里见过,现在程序兼容性好看不出来,但这种循环确实有算法是可以找的
Vim
10
但有时这是合理的需求。不知道,其他软件或方案是如何解决这种需求的?
不合理啊,让不该循环的程序陷入死循环在任何情况下都是不合理的,比如网站有这种重定向早超时了。欧路会显示一个空白词条,深蓝直接显示@@@LINK,goldendict我不知道,好像直接就忽略了,检测方法网上搜“有向图环路检测”
编译前文本的检查估计不好办。还是得mdx软件端进行设置,限制跳转的层数/次数(比如4、5层)
好办啊,最简单的办法,所有link提取出来深度遍历,就是费时
那还是得有一个层数/次数的限度?
理论上,跳转循环可以是乱七八糟的,a-d,d-f,f-b,…,c-a,绕一大圈才回来、或者分叉又合一的
(计算理论中的halting problem,抬杠一下哈)
我以前制作的一个mdx自作聪明搞了很多@@@link,结果大家都反应死循环,哈哈
这和停机问题不是一回事,有分叉不影响检查环路是否存在,你说都会死循环恰好证明了mdx的link设计有多差
Vim
16
现实中,A引用/参见/相似/同义/近义B,B引用…C,C又引用…A,这不是很正常的需求吗?
A 引用/参见/相似/同义/近义的 应该是 part(s) of B 吧。
MDX 没有区分词条的可查询“词头”与可引用“地址”,重定向/跳转只能整个显示目标词条。垃圾设计。
那应该做个超链接see also,而不是简单粗暴的@@@LINK
Vim
19
那也可以这样理解:简单粗暴的@@@LINK设计,关键是看词典软件如何处理@@@LINK,与MDX设计无关,现有的词典软件设计是全部一次性展现,完全可以变更为将其作为词条的一个正文补充,See also。
因为从词典制作者的角度来看,这种需求就是很正常,也很常见的,你不能期待词典制作者去解决这种技术问题,这是词典软件的解决任务。除非有更好的方案,目前还没看到。
@@@LINK太粗暴了,软件没法进一步处理。比较好的是跳转到词条ID#锚点。但用词条ID,你们文本处理会增加难度。
很多词典本身内部跳转是精确的,做成MDX后都没法精确跳转了,就是缺少词条ID的原因。