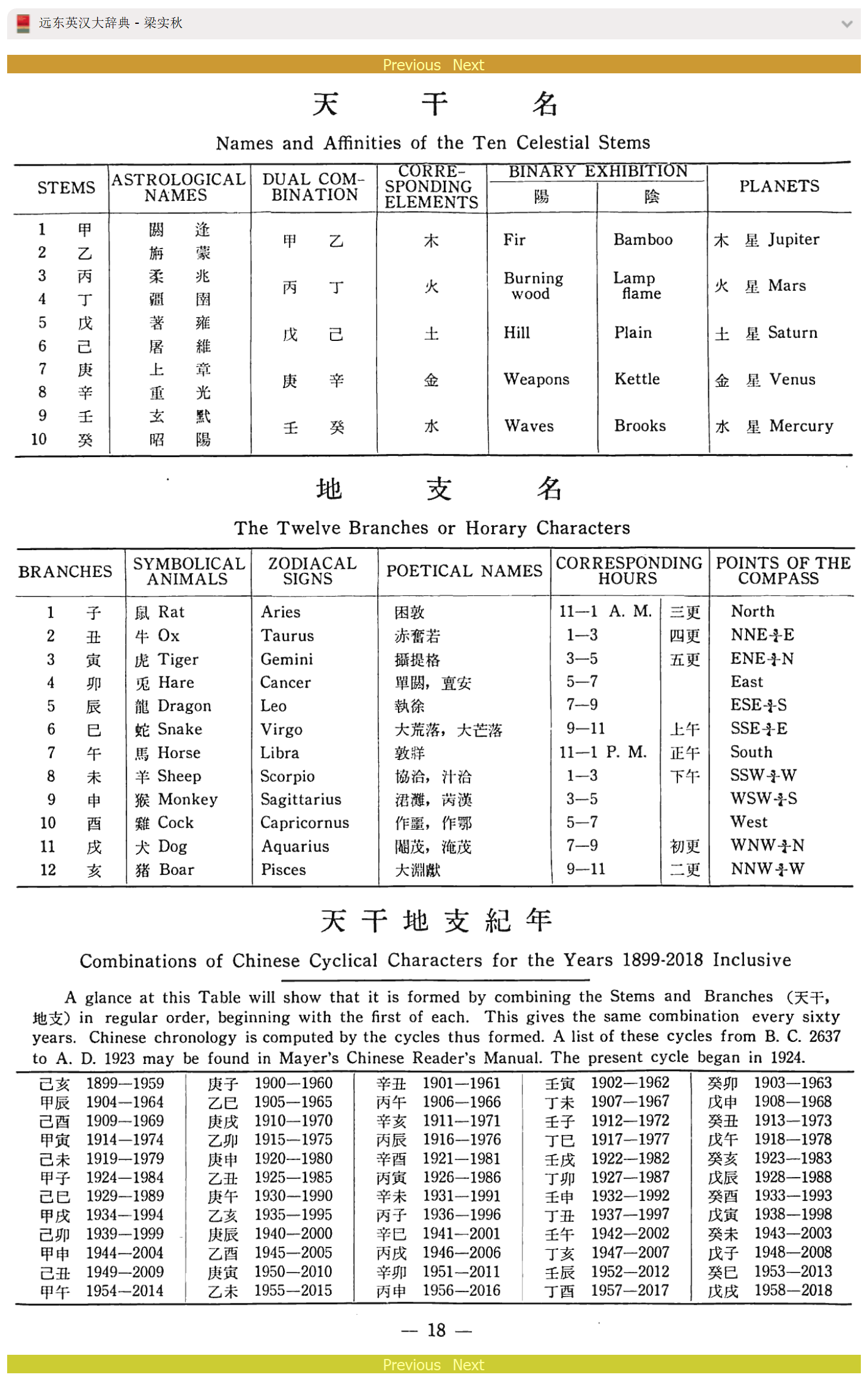
图片词典的制作规范与开源工具
背景
时常遇到好资料,怎奈只有PDF扫描版,辛苦制作好词条,但成品的导航却不够理想,梳理
一下现有获知的工具,提出图片词典应有的标准,希望各路高手能够借鉴打造理想的工
具,造福广大词典爱好者。
现有图片词典制作技术点评
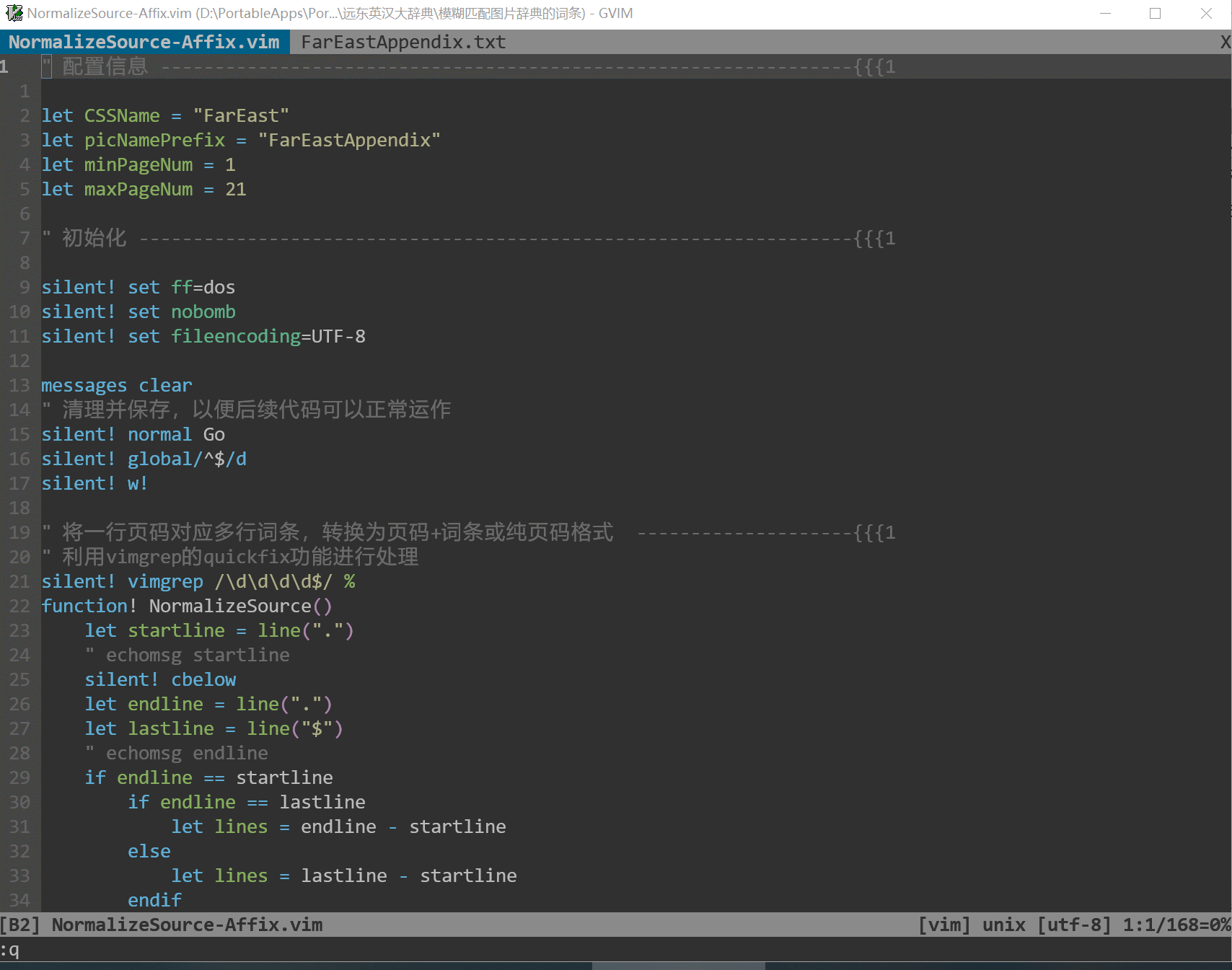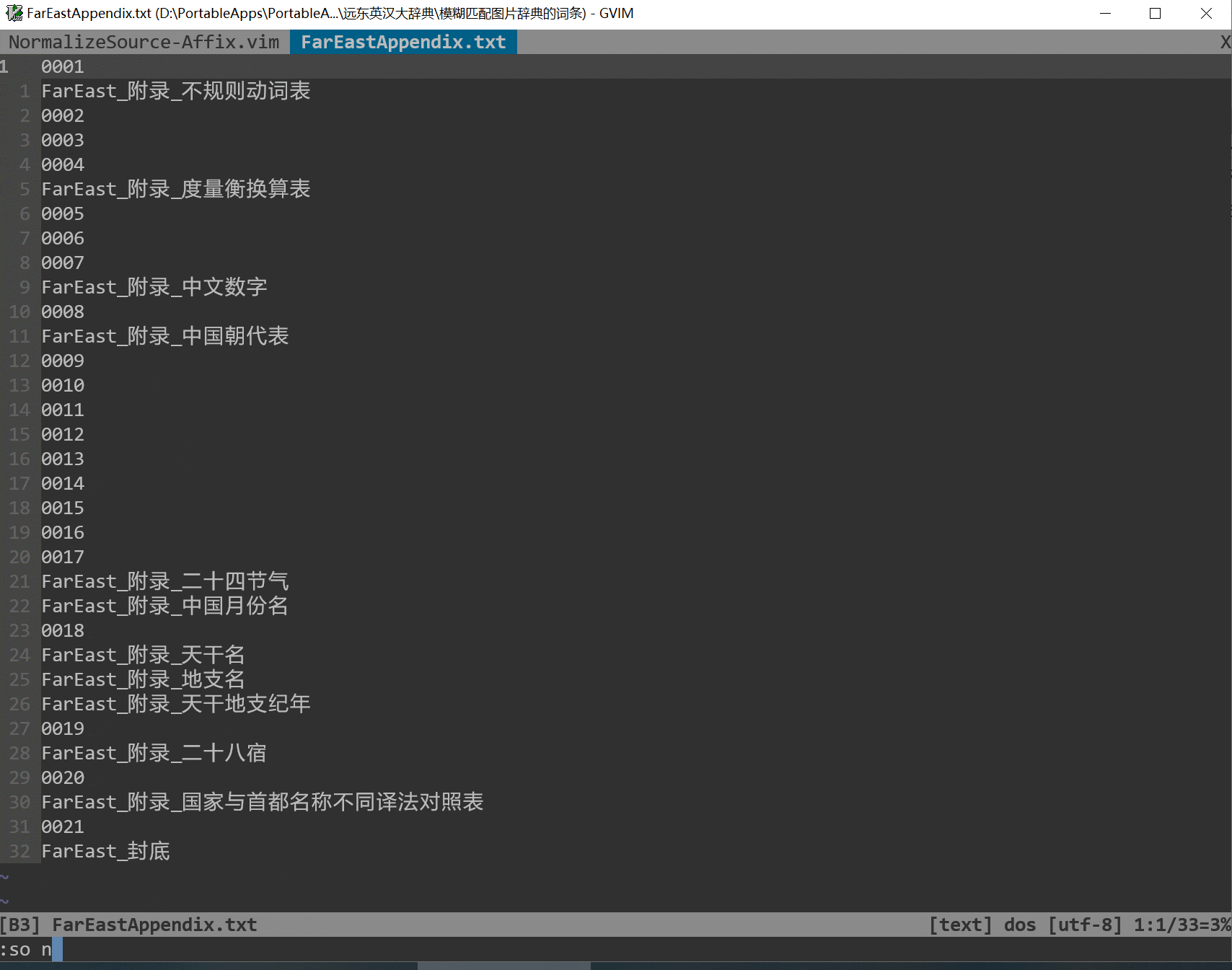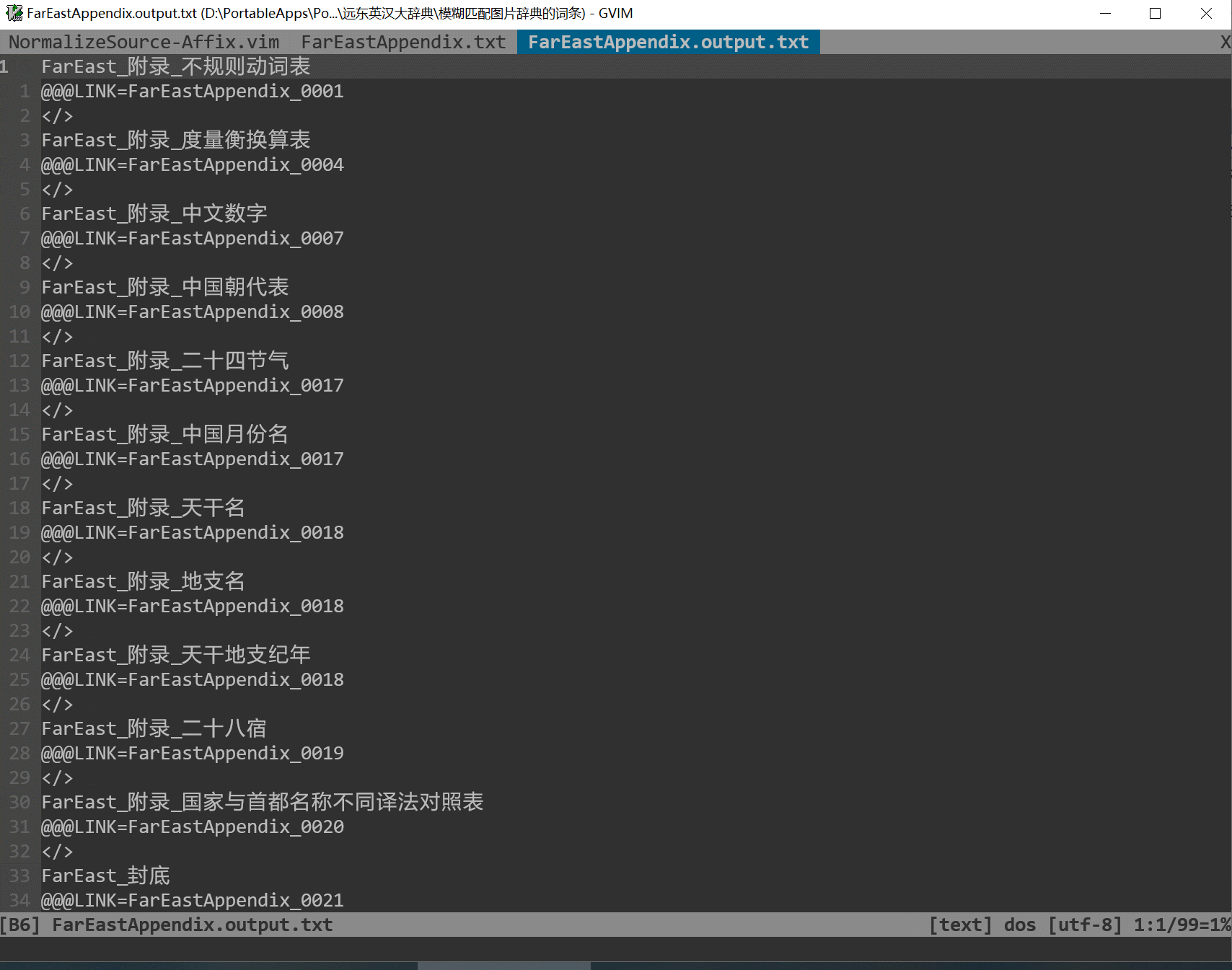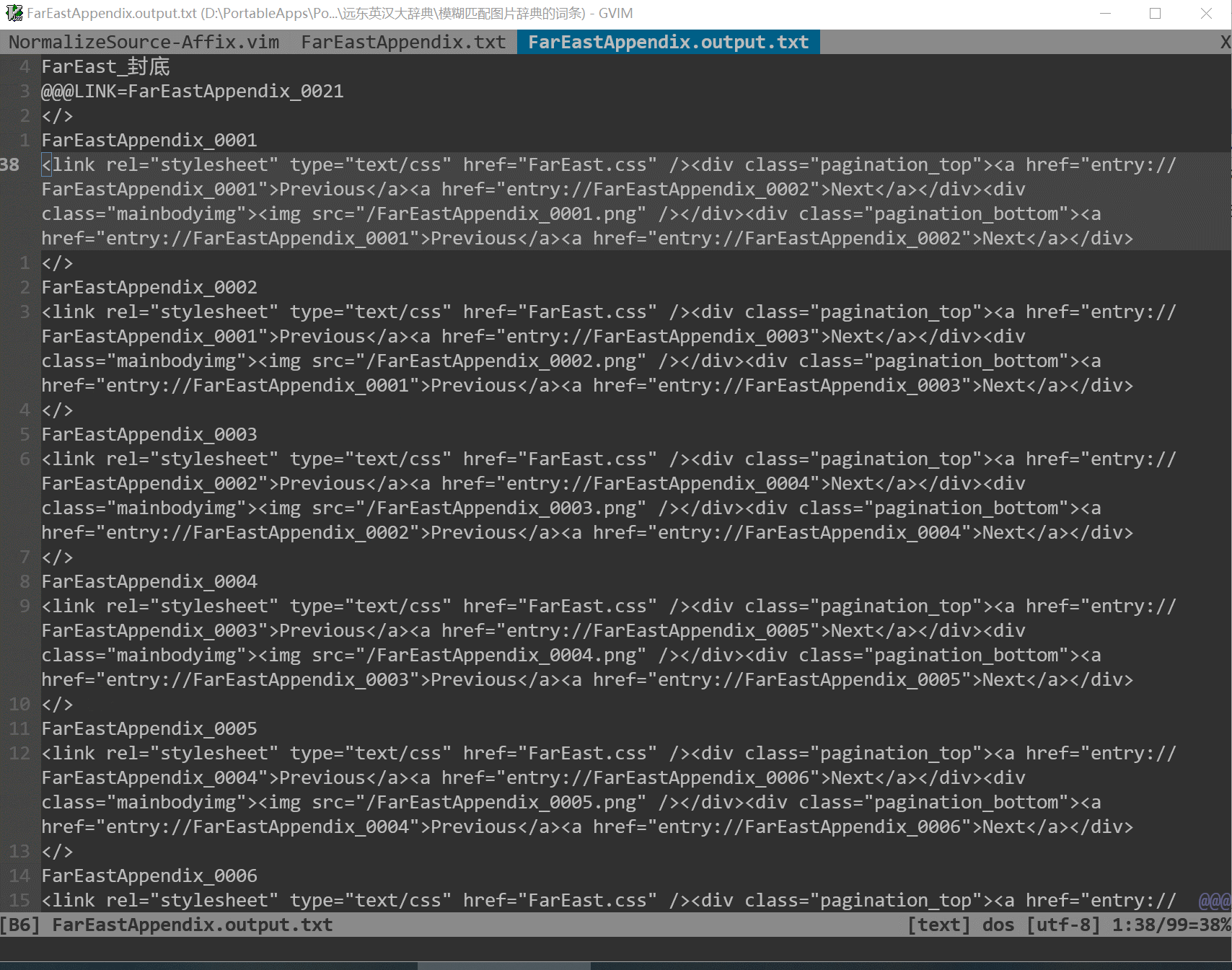
* 图像版mdict字典制作方法 by tsiank
- src: https://www.pdawiki.com/forum/thread-13451-1-1.html
- 这是最优秀的原创教程了,入门必修
- 优点:理解图片词典的基本原理
- 问题:导航简陋,难以在页面中定位具体词条
* 图片版mdx源文件生成工具 by tsiank
- src: https://www.pdawiki.com/forum/thread-33574-1-1.html
- 这是上述教程的升级版,带工具了!
- 优点:导航体验大大提升;技术门槛极低,小白都可以使用
- 问题1:不能自动处理多部分构成的书籍,目前主要处理正文部分
- 问题2:生成的mdx源文件有很多细节问题需要进一步处理,如CSS缺文件名、多
个标签属性之间缺空格、nobomb格式等
- 问题3:鉴于使用Excel,无法与其他工具链结合,从修订原始词条文件到生成
mdx源文件无法一步到位
- 问题4:导航依然有改进空间,VBA不熟悉,改造困难
* 以Picture Capture为代表的切图版词典制作软件 by chigre3 等
- src: https://www.pdawiki.com/forum/thread-19040-1-1.html
- 这是对终端词典用户体验最好的工具
- 优点:直接定位到具体词条、导航丰富
- 缺点1:工具非开源、偶尔开放下载、遇到问题没有反馈处理机制
- 缺点2:对于普通词典制作者来说极其复杂、体验糟糕
* 使用CSS精确定位Visual词典 by 孤影 等
- src: https://www.pdawiki.com/forum/thread-20350-1-1.html
- 对于Visual Dictionary词典用户来说,体验很不错
- 优点:关键词加亮、可直接在图片上点击关键词链接
- 缺点:具体技术细节不开放,仅可观摩案例Chinese-English Bilingual
Visual Dictionary (https://www.pdawiki.com/forum/thread-35929-1-1.html ),
大致是先OCR图片,并通过类似Picture Capture工具切片获取每个关键词的相
对定位,最后使用CSS隐藏文字层并定位关键词,太复杂了
优秀的图片词典工具链标准
* 词典成品的导航体验要足够好:核心是有助于快速定位具体词条位置
* 词典要能够适应不同尺寸的屏幕:阅读体验好,字体太大或太小都不可取
* 图片处理要足够简单:使用扫描的整页图片即可,不要切片等复杂操作
* 词条的录入、校对要足够简单:要一目了然,不容易出错,技术门槛降至最低
* 词典修订要快捷:修订原始词头文件后,通过工具可一步到位生成最终的mdx源文件
为了实现上述目标,拟根据自己制作十来个图片词典的实践经验,提出如下制作规范,大
家可将其看作是开发相应图片制作工具的用户需求文档。
成品图片词典的导航构想
* 在页面顶部显示Pages导航 和 Keywords导航(或有)
- Pages:Previous Next Cover Preface Content Index etc.
- Keywords:A B C D E F G
* 在页面底部显示Pages导航
- Pages:Previous Next Cover Preface Content Index etc.
* 在Pages导航中:
- 上下页,可自动处理first和last页面
- 上下页,可自动处理多个部分的页码体系为一个连续整体,如:
- 正文前123(封面、目录等)、正文123、正文后123(索引、封底等)
- 除了上下页外,可自定义添加封面、前言、目录、索引等固定链接。
* 在Keywords导航中:
- 若没有关键词,则不显示Keywords导航,适配封面、前言、目录、索引等页面
- 若某个关键词作为mdx的keywords,即使用Keywords导航中的某个关键词进行查
询,则在Keywords导航中加亮该关键词。
- 若页面作为mdx的keywords,即使用Pages导航中的页码等进行查询,则在
Keywords导航中的关键词不做加亮处理。
源文件格式规范
* 图片文件命名格式:
- 根据页码编排需要,可将书籍分为多个部分,如:正文前123(封面、目录
等)、正文 123、正文后123(索引、封底等)
- 对于不同部分的图片,相应文件名命名规范为“前缀名+页码+后缀名”:
- 前导名可自定义,中英文均可,建议采用书籍英文名或拼音缩写等个性化
名称,避免多词典之间命名冲突
- 页码位数可自定义,默认4位,可根据需要设为3位或5位等
- 需要正确识别图片后缀名,如jpg、png等
- 图片文件名案例:某书前0001.jpg…某书正文0001.jpg…某书后0001.jpg
* Keywords源文件格式:
- 对应书籍的多个部分,将keywords源文件分为多个部分,如:正文前123.txt(封
面、目录等)、正文123.txt、正文后123.txt(索引、封底等)
- 具体内容格式(极大化方便用户输入词头、校对和修订):
* 第1行页码:0001
* 第2行关键词:A
* 第3行关键词:B
* 第n行关键词:N
* 第n+1行页码:0002
* 第n+2行关键词:X
* 第n+3行关键词:Y
* 第n+4行关键词:Z
* ……
- 页码之后,可以没有关键词
- 若有关键词,则同时生成相应的Pages导航和Keywords导航
- 若没有关键词,则仅生成Pages导航,而没有Keywords导航
处理程序及配置文件规范
* 建议使用Python3,毕竟用户多,大家有能力按需改造
* 程序作适当配置后,应可一键生成最终的mdx源文件和css
* 主要配置包括:
- 书籍多个部分对应的Keywords源文件和图片文件
- Keywords源文件名称
- 对应的图片文件名:前缀名 + 页码位数 + 后缀名
- Pages导航中的自定义固定链接:
- 固定链接名称(如封面目录) + 对应图片文件名
- mdx目标文件名
- CSS文件名
- 导航的中英文
- 简中:页面、上一页、下一页、关键词
- 繁中:頁面、上一頁、下一頁、關鍵詞
- 英文:Pages、Previous、Next、Keywords
目标文件格式规范
* mdx源文件txt需要满足mdx源文件的格式标准:dos,nobomb,UTF-8
* 生成的CSS可进一步配置:
- Pages导航样式
- Keywords导航样式
- 加亮Keyword样式
- 图片宽度:百分比(默认100%)或固定大小(px或em)
扩展1:整页版和多栏切片版二合一
为适应手机等移动设备的查阅,需要将整页版适度分栏切片
* 词条需要分栏处理
* 图片文件名需要分栏处理
* CSS要能够自适应不同屏幕尺寸的设备
具体改造略
扩展2:多层次词头优化
为优化类似Longman Language Activator、朗文多功能分类词典、现代汉语词典等词头有
多个层次的词典,可在原有标准基础上,进一步将Keywords区分为多个层次,如字、词:
* 在页面顶部显示Pages导航 和 字词导航(或有)
- 页面:Previous Next Cover Preface Content Index etc.
- 字:A B C D E F G
- 词: WordA1 WordA2 WordA3 WordA4
* 在页面底部显示Pages导航
- 页面:Previous Next Cover Preface Content Index etc.
* 当查询页码(并未查询具体的字或词)时,仅显示页列表
* 当查询某个字或某个词时,不仅显示字列表,还显示这个字所包含的词列表
具体改造略
诚邀Python等高人打造开源的图片词典制作工具
若能够制作符合上述标准的工具(先有标准版的即可,扩展版再逐步优化),必将造福广
大词典爱好者,无论是字典制作者,还是字典使用者。
若有需要,我可提供相关案例词典:包括完整的图片、词条等。