W2K
1
本贴非拉人头帖子,会把我OCR后校对的文本发上来,有同好的一起讨论的帖子。
目前的进度是全部OCR完了往回装,逐行、逐列校对。
逐行装回去保证不落行,不丢字。校对起来方便(装回去了800了)。
校对到了91页,校对起来过程还算行吧
最终能弄到哪里算哪里,通过前期的过程感觉到这货要消耗的工作量少不了,但怎么说也要有个开始。
本想一百页一发,刚开始慢还累就先弄到这了。
前期还是试着弄,是把OCR完的全装回去完事了校对,还是一边装回一边校对,都没想好呢。
0001–0091
0001–0091.txt (1.3 MB)
接着填坑
2024.12.10
这种也有、随手录
2024.12.13
回填一个月7-8百頁左右的量(利用空闲时间)。
2024.12.18
偶尔发现,OCR拿过来的编码点下保存再取消,基本区外的都是高亮红显示。
2024.12.20
2024.12.21
笿
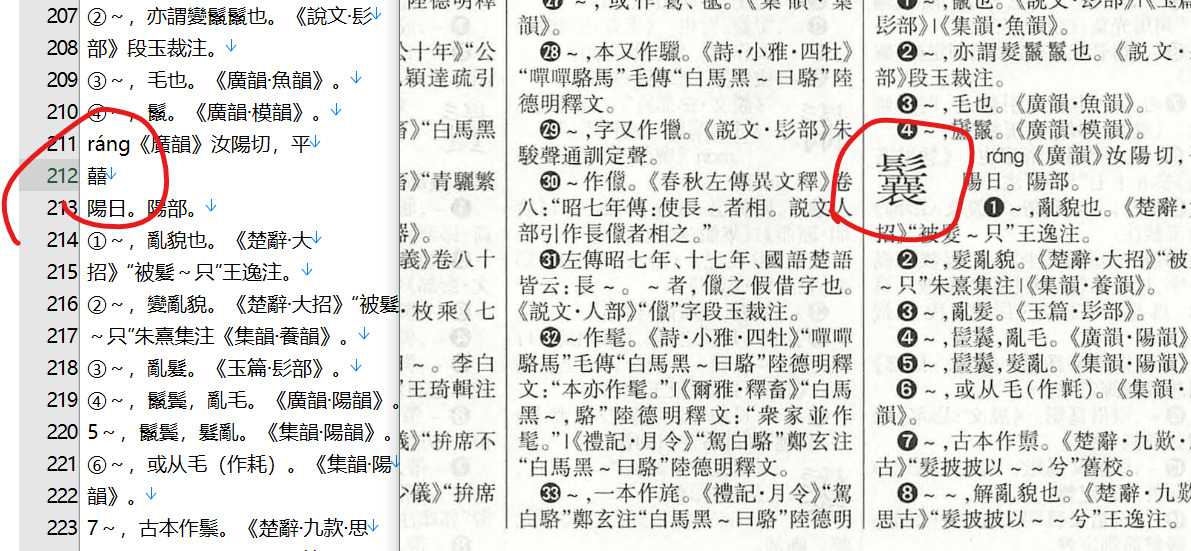
1500頁过后大批量这种,基本区脸盘大的反而都错的,字里行间的却一切正常。
2024.12.25
短11项
2024.12.26
P:1792 第2列中上
都是这样对对错错,速度快不起来啊!合合也呵呵呵啊

,MLGT的,绝对当班喝酒上岗干的。
2024.12.29
怎么闹,既然文本电子化了,应该统一下好。新旧也就算了,这种混排乱乱的
2024.12.31
这种撸一撸应相当的板扎
2025.01.02
今年的任务完成啦、可以下班啦!!!哈哈哈
2025.01.05
八百多、一千多填入时看后面还要一堆要回填(慢慢来,债多了不愁)。可过了2000页后看就剩下600多了,这小半个1000页也没多少。就不墨迹啦弄完进行下一步校对,离当初的想法又近了一步。
2025.01.09
怎么弄啊???
2025.01.12
2025.01.13
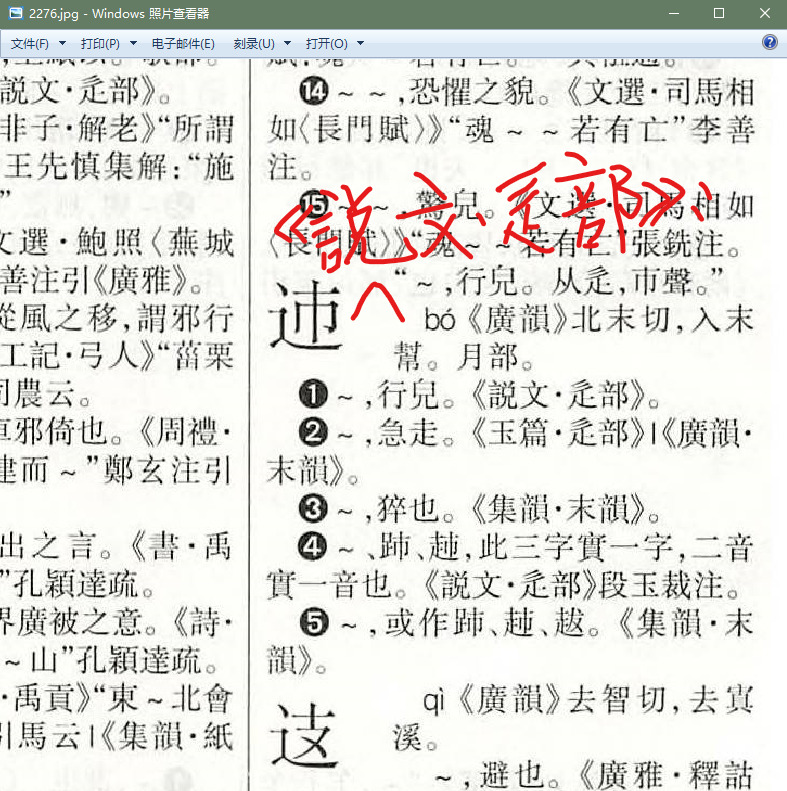
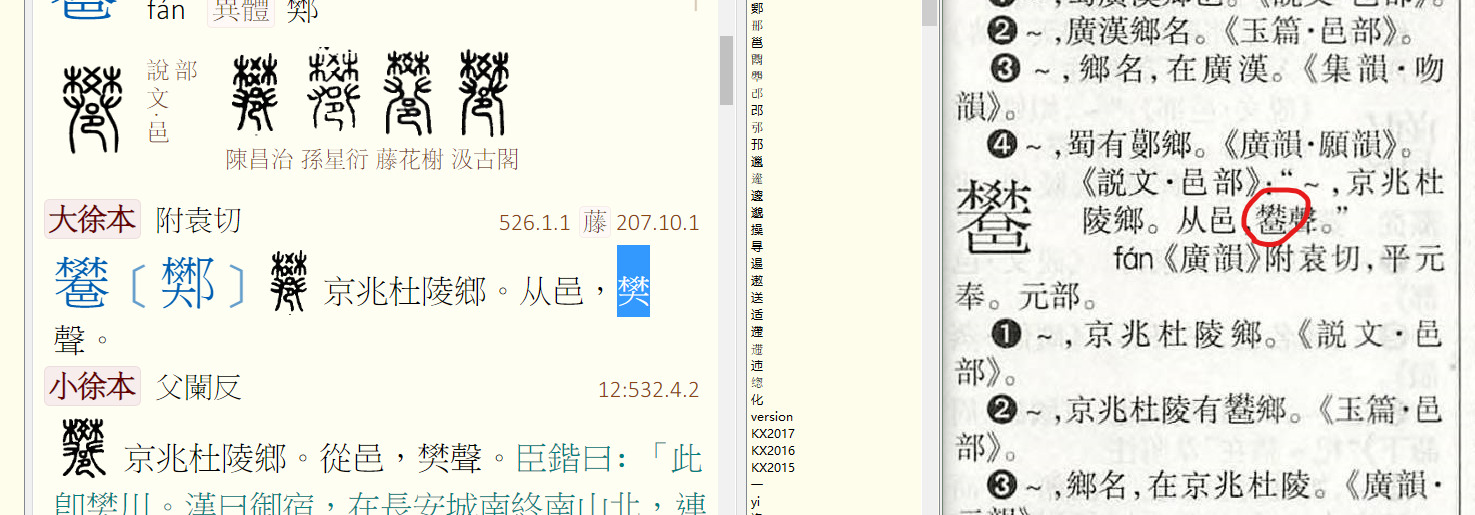
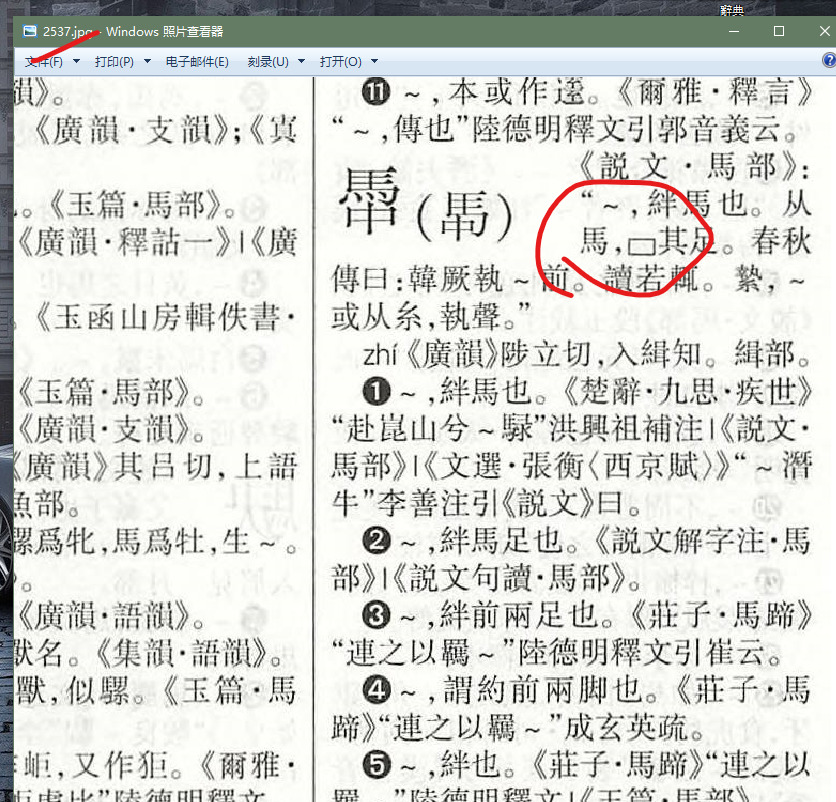
查不到这个字(足刃刃止止)。
发现个安装字体的app(iOS)
不用拆开字体直接装,我一开始只装拆开的
还是有部分显示方块。
今天用了最新的部件檢索,索性把字体也重新装了,
用了下完美。也是试出来的东西。手机上有显示不出来的(iOS)可以试试。
2025.01.16
P:2165左下 应该是 「犭艹」𤡞吧???
2025.01.21
此处应该落了字!!!
2025.01.23
P;2340
2025.01.26
P:2456三列卦噗先记录
2025.01.28
留印后处理
这块按排版的体系应该干掉序号才对吧
什么节奏???要走桃花运了么?弗晓得
2025.01.30
此处应为171下页(4列有172项)
2025.01.31
开始打标签、校对。记录印刷错误部分。留印待处理。
2025.01.31
2025.02.01
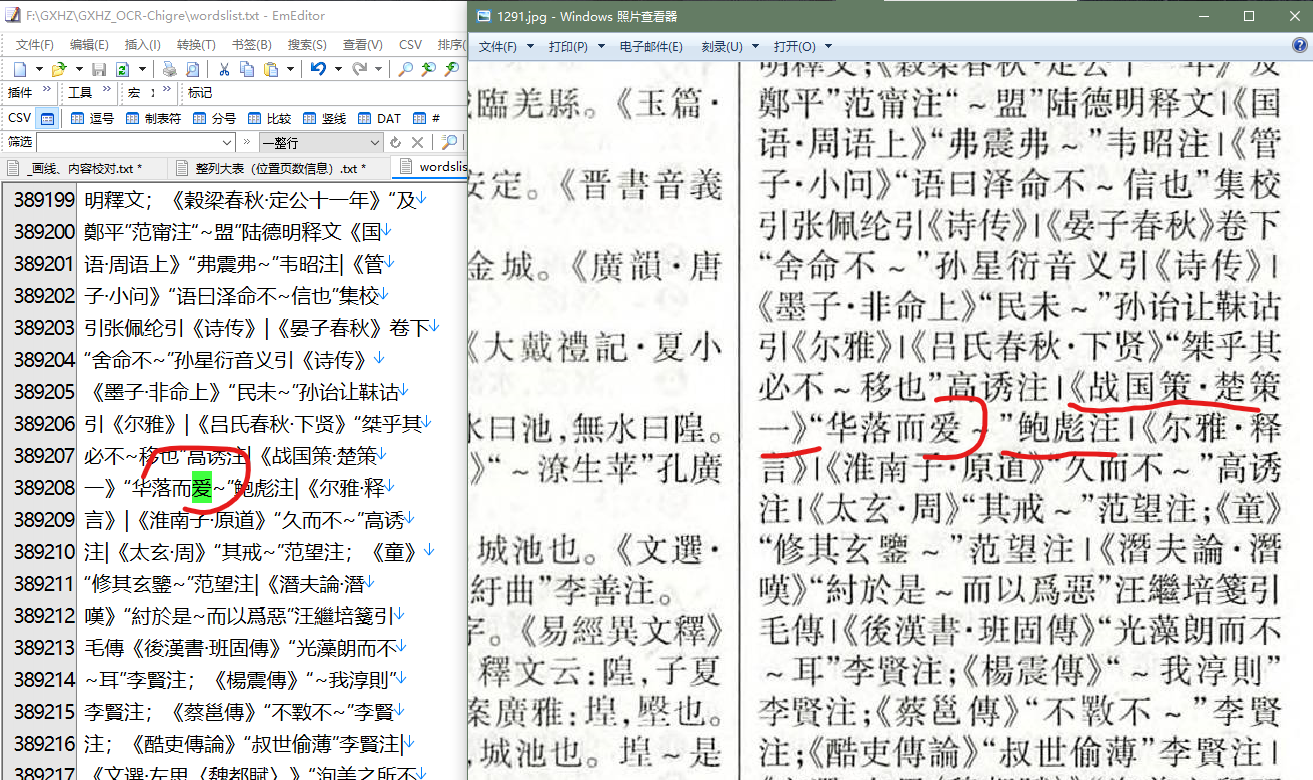
确定是爱而不是愛么?????????????
14 个赞
hjtoh
4
不知道楼主用什么ocr的,我刚才用百度高精度试了一下,基本上没有错字,校对的话只需要看看序号和符号,这样如果参与的人多,工作起来也挺快的。
W2K
5
裁条、整页和1/4页分开都试过了,整体感觉选对提供服务平台比用啥姿势要重要。百度小打小闹还行,批量用它我没那勇气。
截图里不是有吗!合合(开始不限高度、现在限制了)、有道(这货现在要登陆了就不用了),除了个别丢行没其它的问题,都出现在首字为波浪线 ~ 的时候多,个别的也有丢行的但很少可以忽略不计。
免费试用的通道(除了每天有次数限制)要好于付费的通道。
分栏切开 OCR,整理文本也方便吧。用百度识别挺好的,我问过有道的客服,他们没有专门训练过繁体字的识别。
W2K
7
感觉大家对几栏几栏的有个误区,认为栏数多相对要做的就多。我都是用看图软件用按键精灵之类的软件上图上抓过去调用然后拿回文本的,单栏多栏一回事。
我猜整理文本应该都方便吧,目前费事的都是必须要手敲部分和{皃 兒 日 曰}之类的。其它的还真没啥。
1 个赞
cool project.
mdx字頭索引有無用OCR索引來校訂?我早期作了個圖像版,臨時修了些字頭、加了異體跳轉,但沒有系統化地校訂索引。

1 个赞
W2K
9
还没弄到那步,但逢词头都用部件檢索查过,不在基本区的都做了标记(OCR不出来的几乎都是基本区外的),除了301–405间的当时测试哪个平台的OCR位置信息好用所以抹去了图片上的词头外(那段为了快速按位置信息往回装回校对方便)。
到时可以拿过来那真的太好了。
目前先保证不落行,不丢失图片上的内容,把完整的内容都弄下来。
我記得當初的索引有錯形,例如不當有的簡體字,不記得有沒有錯字。字頭索引有排次信息,這點挺好。anyway,我可以幫忙校訂,只需要數據來比對。
W2K
11
1–860页。
1–860.txt (10.5 MB)
搜@就出来了。
1 个赞
wsht12
14
楼主确实牛,但识别软件好像太好准。
识别可以免费的用Umi-OCR,有一些字会不准
收费的用 天诺 然后选有道智云 接口识别 有100元免费额度。准确度很高。
Syzygy
18
楼主可否导出一个引用书目表?(书中附的自称是不全的)之后我再逐一选择善本,方便核对原书。
W2K
19
文本挂着页码、位置信息,都按图片书的格式错行放着呢,像on \r\n R
打直或on 《([^ 》《]+?)》 《\1》 R 我的电脑整不动,目前拿不出来你要的引用书目。
Syzygy
20
不知用 sed 之类的命令行工具转换如何呢。不过我也不会弄。