feiwu
21
W2K
22
你说的一会装下字体看下
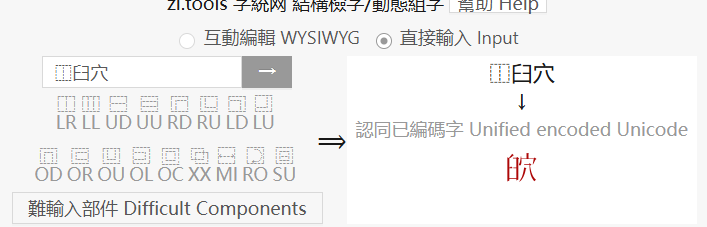
现在好多东西还叫不准。就拿词头来说,一开始觉得非基本区的拆开可以查到就行了,所以录入是就简单按自己理解的
再加个这东西就完事了。
可有的字根本不是那回事,所以现在正翻回头按这个网站的在录入一遍,可是这个网站也不是都拆开的,没有的按(字統网)拆字录入呢。
有些还是叫不准该用哪个(着手弄这个就发现了,挠脑袋也不行)
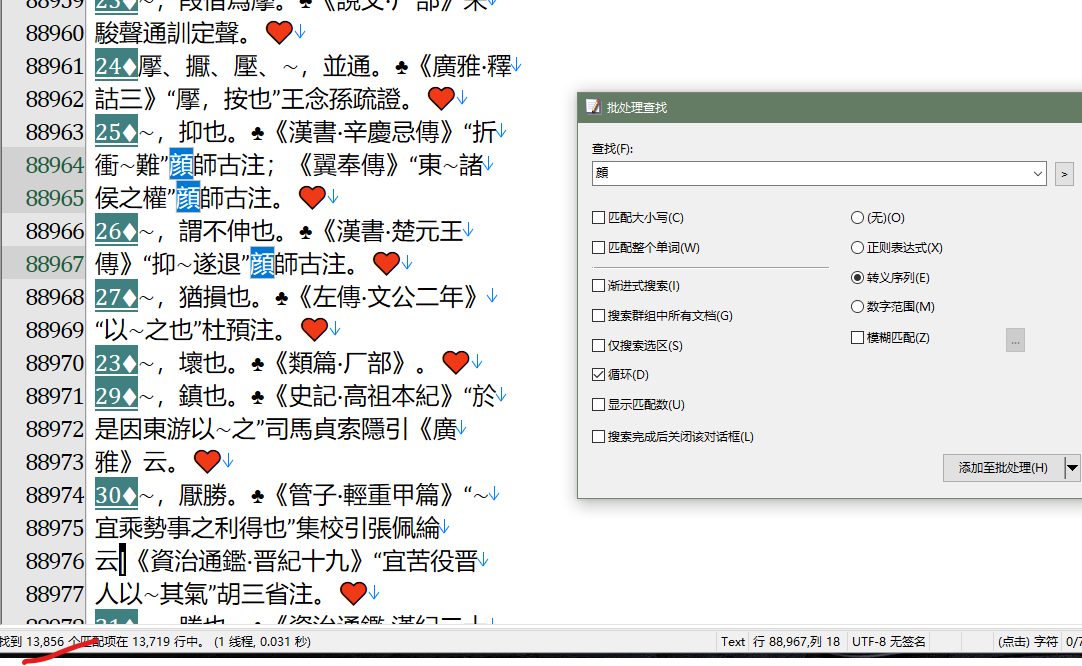
顔 顏
顔
U+9854
UTF-8: 0xE9 0xA1 0x94
CJK Unified Ideographs
Unicode 脚本: Hani (Han)
Unicode 的一般类别: Lo (Other Letter)
文件位置:168 字节
顏
U+984F
UTF-8: 0xE9 0xA1 0x8F
CJK Unified Ideographs
Unicode 脚本: Hani (Han)
Unicode 的一般类别: Lo (Other Letter)
文件位置:171 字节
“上”字头的119项
而我这觉得靠谱信息查了下
凡例里写的
我咋保证啊???我也没看到原书,按纸书印刷那可简单了(像这样得按纸书印的绝对不是最好的选择,但也是目前唯一的办法)
你楼上那朋友也说要看下引用书目表
就还拿“颜”字来说我这块都没法下手。
我理解的不是简单的一替换的事,反正没想好咋弄。
不想由于个人的主观二次引入错误。
哈哈哈,先玩词头吧(弄错了也好改  )。
)。
W2K
25
校对、补标签,今年过年没弄。总共这些
平时没时间,你有时间就拿去。最好能保持我这样的然后返回我一份我做个比对(也不是必须的)
要的话圈我下我私给你
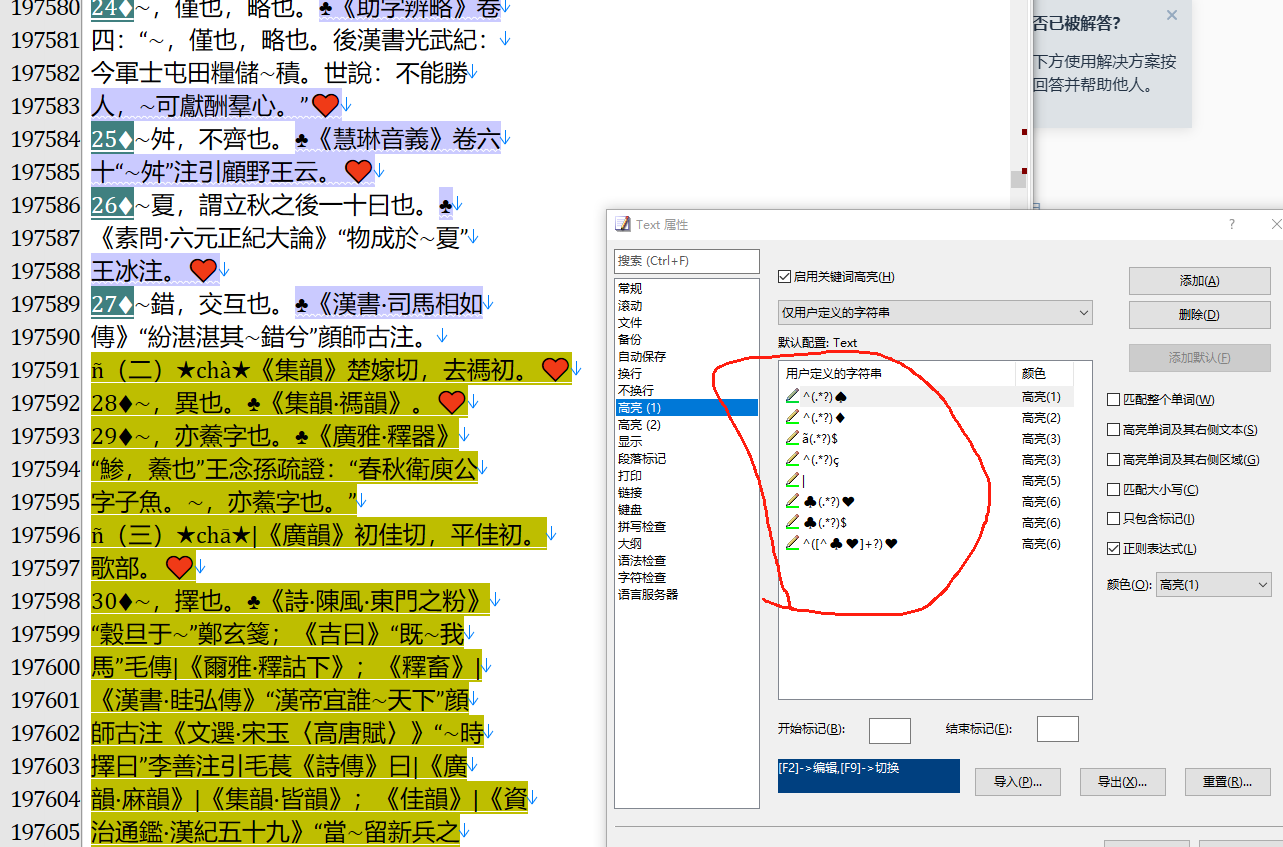
还用Em的有知道跨行高亮的多个的么?我就会这一种。
其余的我都这样配着弄的
feiwu
27
你的标签弄得好复杂,其实只要换行对,剩下的都可以用正则来处理。
出处匹配到句号和书名号之间,^(\d+♦.+?。)(《.+)$替换为\1♣\2♠,即使有错,也不会太多。
W2K
28
那个就是为了高亮糊弄人的玩意、别当真
我弄的:
^\1 头
头
ã\1ç说
ñ\1õ音
^\1 序
序
\1 意
意
\1 例
例
就这点东西。
保持和排版一致我就没弄直再按标签打断,反正从头开自己始弄的都清楚,再装回去每个字就连标点都是对位的。
后来慢下来就是一边校对一边看,感觉缺好多应该有的东西为了排版和体量人为的删减了不少,反正就是不过瘾的那种。(我记着好像在哪看过过报道,出版社都着手出版了中间又提出要求原作者做了内容缩减)
这本真的挺不错
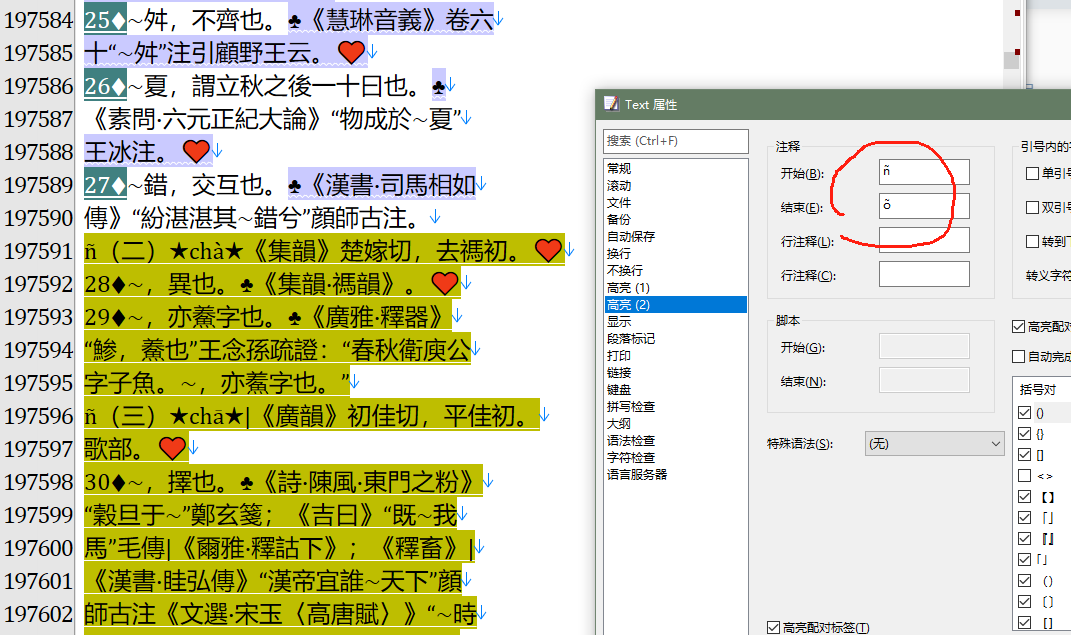
标签是手动补的吗,感觉非常容易出错,现在有新模型了,文字可以多ocr几个版本让ai来预处理,标签也可以让ai写程序解析。
W2K
31
那个已知的小问题了,有ocr时错误、也有最初正则弄错的。
大体定下后除了查找就很少批处理了。
像这种靠正则啥的根本不靠谱,只能靠肉搏,有的释义真的好多行才是例。还有兒↔皃(大面积)、囗↔口(小面积)的大小圈的事都得靠手翻才是真问题,那个i 、|问题有,但顺手改了就行了。
觉得这本只有下手去弄才最靠谱,什么AI啥的也就是印刷不清楚的地方按前后左右信息能查出它是个嘛。使不上啥劲