mdx, slob, ZIM 三个格式大同小异,都是压缩 html 和一些资源文件到一个文件里面,然后可能包含用来获取内容的索引表之类的东西。(压缩方面 mdx 的用的是 zlib or LZO,新的 zim 用的是 zstd)
ZIM 本身格式开放,且相关工具都是开源的。开发者是 kiwix 项目。虽然是开源软件,但是背后有金主 Wikipedia 每年打一波钱,可能会比一般的开源软件更可靠一些 :)
https://wikimediafoundation.org/news/2023/04/13/first-grants-announced-from-the-wikimedia-endowment/

ZIM 并不是为词典设计的,而是为了压缩像维基百科那样的整个网站,每个网页都有一个 Titile,GoldenDict 用这个 Title 当作词条,实际上和词典并没有太大区别。
操作这个格式的核心库是 libzim。基于它有好几个工具
- zim-tools → 几个命令行工具
- python-zim → 用 python 读 和 写 zim 文件
-
wget-2-zim → 通过 wget 的
--recursive来下载整个网站 - mwoffliner → 从 mediawiki 网站上抓内容
- …
目前:
- GoldenDict-ng 直接用 libzim 来解析 zim 文件
- 原版 GoldenDict 用的是自己的代码来解析 zim
- Kiwix 有 Android & IOS 和桌面软件可以用
这是一个用 zim-tools 中 zimwriterfs 的例子,包含一张图片,一个音频,css & js 的加载,一个词头跳转 以及 生成的 zim 文件:
zim_demo.zip (4.4 MB)
Sadly,目前 ZIM 制作的相关工具在 Windows 上支持并不好,需要 Linux 或者 WSL 安装 zim-tools (ubuntu 22.04) or zimwriterfs (ubuntu20.04) ![]()
按照 词典制作:从一个简单的图片词典开始 的说法,MdxBuilder 应该需要把内容汇成一个 txt → 转换成 html → 合并成 mdx
zimwriterfs 只做其中 html -> 合并 的步骤,不需要 emeditor 那样的特大文件编辑器。
因为 ZIM 本身是用来储存网站的格式,只要把页面做成类似网站的结构就可以。生成这个”网站“的方法可以随心所欲。
例子的文件结构如下:
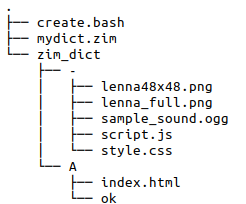
在 . 目录里,执行这串命令就可以生成 mydict.zim
#create.bash
zimwriterfs \
--welcome A/index.html \ # 主页,实际上 gd 不需要
--illustration=-/lenna48x48.png \ # 必须是 48x48 的 png 文件
--language=eng \
--title=zimdict \
--name=zimdict \
--description="This is just a demo" \
--longDescription="This shuold be longer than Description" \ #另外的描述,gd 暂时不用,旧版的 zimwriterfs 没有这个命令?
--creator=slbtty --publisher=slbtty \
./zim_dict/ \ # 内容目录
./mydict.zim
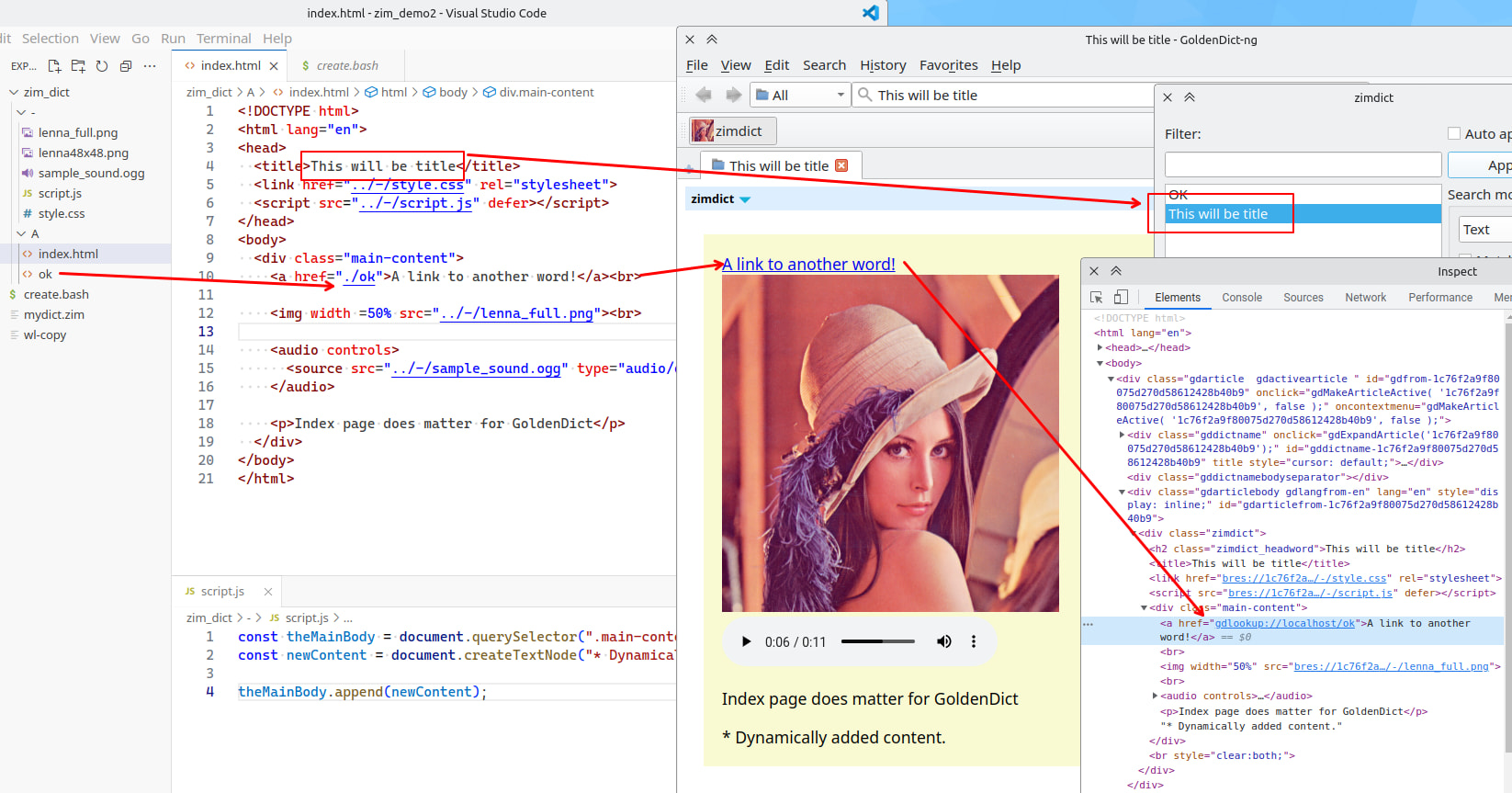
“index.html” aka “This will be title” 的内容
<!DOCTYPE html>
<html lang="en">
<head>
<title>This will be title</title>
<link href="../-/style.css" rel="stylesheet">
<script src="../-/script.js" defer></script>
</head>
<body>
<div class="main-content">
<a href="./ok">A link to another word!</a><br>
<img width =50% src="../-/lenna_full.png"><br>
<audio controls>
<source src="../-/sample_sound.ogg" type="audio/ogg">
</audio>
<p>Index page does matter for GoldenDict</p>
</div>
</body>
</html>
GD-ng 的效果: