
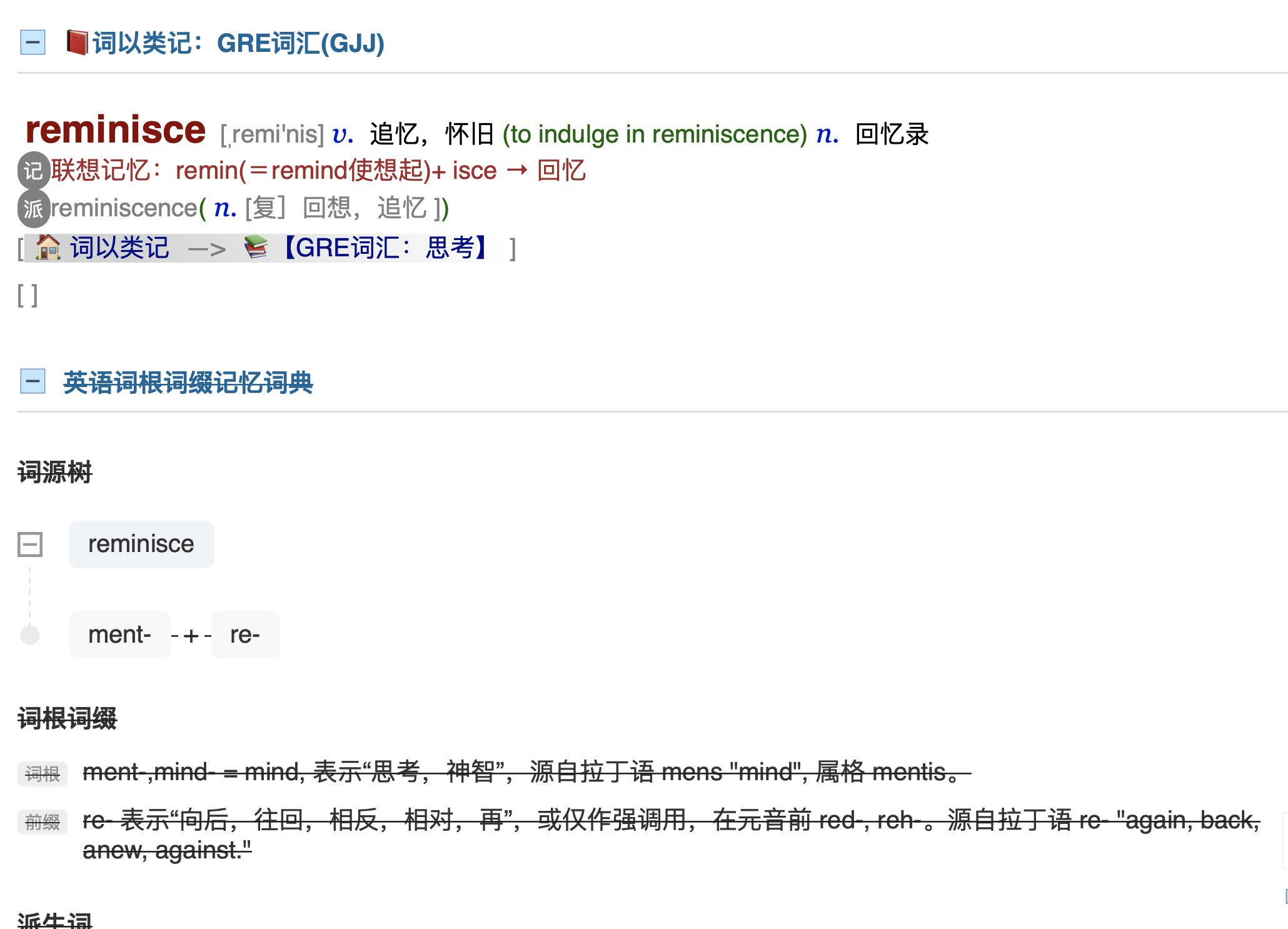
偶然发现查reminisce这个词后面所有词典都会出现删除线, 很是不解
跟作者guo兄联系他说正在忙, 后面也没有回复了, 可能觉得我可以自己搞定吧, 但是本人对于词典修改确实不通, 可否有人愿意点拨一二
另外, 还有一个bug有人提出, 我看也确实存在, “等了一周到新年了,楼主还没有更新这个BUG: 有个叫“生活杂物”的类别貌似是整体遗漏了吧?查wick试试。希望能纠正哦。
望眼欲穿哦。”
这个生活杂物一项确实漏掉了, 不过我看了下, 这一项里面的单词好像都在, 不知这个问题应该怎么修, 如果原作者实在是忙, 我可以理解, 希望有人教一下我, 我把这个bug改了再分享出来, 也算是替原作者分担工作了 ![]()

https://forum.freemdict.com/uploads/short-url/m5zJIZQW23rR8HF6E7SWDalwYbu.css
https://forum.freemdict.com/uploads/short-url/kE9Wg3d4wcD355x9eHMYPRP48OL.mdx
解开发现,reminisce 词条多了一个未闭合 S 标签:
<S>复]回想,追忆
不只一处,你如果会正则表达式,可以替换去除。
如果不会正则,可以取个巧,作如下替换:
<S> ==> <SA>
</S> ==> </SA>
最后提醒原作者,不要随意使用 S 标签。
1 个赞
多谢大侠! 还有一个问题, 那个标签的问题, 可以一起看下~
2 个赞
<H><a href="entry://目录">🏠</a><a href="entry://交通">👈 上一页</a> <a href="entry://生活杂物">👉 下一页</a></H> 生活杂物<link href="gjj.css" rel="stylesheet" type="text/css" />
改成(注意换行):
生活杂物
<link href="gjj.css" rel="stylesheet" type="text/css" />
然后把 <H><a href="entry://目录">🏠</a><a href="entry://交通">👈 上一页</a> <a href="entry://生活杂物">👉 下一页</a></H> 粘贴到“乐器”词条末尾合适位置。
2 个赞
我在网上找不到Mac端的mdx文件编辑软件, 通过搜索了解到有mdx expert和mdx builder这两个软件的存在,
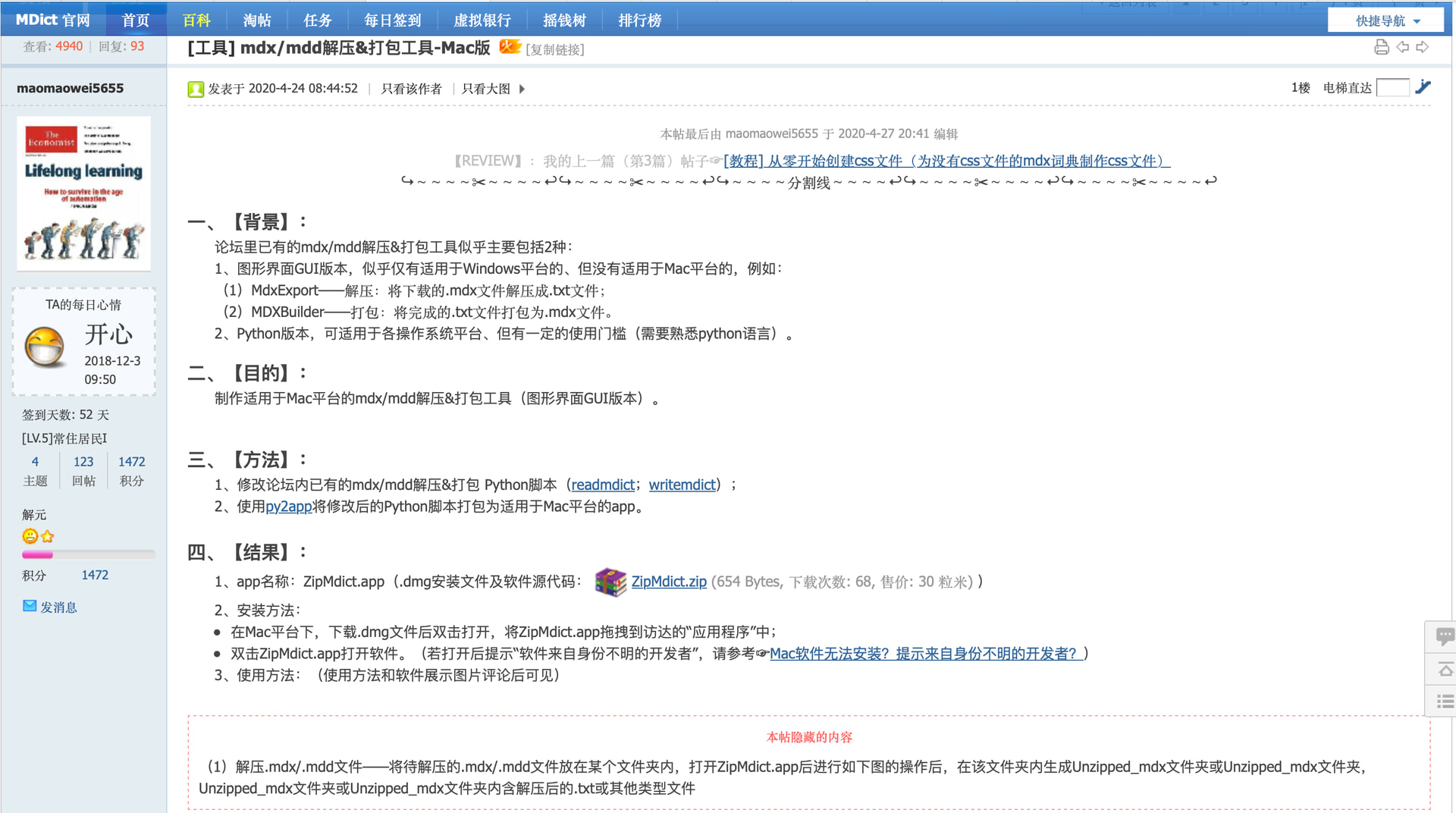
因搜索macOS上的相关工具始终无果, 最后实在不甘心在隔壁坛找到了这个, 无奈附件还下载不了……
我已回复了楼主, 不知何时能够得到回复, 本以为柳暗花明, 谁曾想又碰一壁, 总之这两个小时摸索算是颇为不顺啊!
1 个赞
100多处标签未闭合, <W></W>,<S></S>,<C></C>,<M></M>,<QT></QT>
还有两条没词头,应该是某词条落下的。
[错误列表.txt|attachment](330.5 KB)
2 个赞
不知道可以修吗, 弱弱问一下
使用这个库即可,制作和解压 mdx 都可以:GitHub - liuyug/mdict-utils: MDict pack/unpack/list/info tool
你得会使 Python 呀。
应该是超出我能力范围了, 好在问题都已经找出了
看了一下,
GJJ大概是想把 [ ]和( )
用样式代替。
S{color:gray;text-decoration:none;} S:before {content:"[";}S:after {content:"]";} /*声音 pron*/
W{color:darkgreen;} W:before {content:"(";} W:after {content:")";}/*括号*/
然后,碰到括号不完全匹配,就造成类似
['mɛə<W>r)</S>
<S>æb'siʒən</S><I>n.</I><S>医]
括号一半有,一半没有。
足下可以尝试一下处理, 不过不用有任何压力, 凭兴趣吧, 如果能解决最好, 不能解决同样感谢
推倒,从头重新制作!
1,非GJJ、webeyes版本。完全根据epub文件重新制作。
2,标签加了许多,想要多美好,自行修改。
3,单词有82个是重复的,我没有删除。保留。
4,拆分几个带有()的词头。
呃,实际上错误词条没有那么多,有一些,并没有错误。
像这些
<w>....<w>...</w>....</w>
正则没正确匹配上。提取时也就犯错了。
标签 S 改成SP,<w></w>直接替换成()。
修正了一个错误词头。
两条不是词条的合并到creed、fatalism
[gjj.css|attachment](5.9 KB)[/s]
[词以类记:GRE词汇.mdx|attachment] (1.4 MB)
17楼有更好的版本[/size]
1 个赞
非常感谢!!
如果你不在意的话, 我可以分享这个回复到郭兄原帖下面吗, 也提醒一下关心这个词典的伙伴, 当然如果他们够关心的话, 应该会搜到这里 哈哈
1 个赞
请到这里下载我的改版,大部分错误都已修复:
词典软件就象浏览器一样,对于有语法错误的HTML是有高度兼容性的,一般象缺少闭合标签这种问题都会自动补上(如果打开HTML调试器可以看到),即便不修改也不影响显示。但有罕见的时候可能会牵一发而动全身—— 某一个词库的HTML标签有问题或者CSS有问题,可能牵连到其他词库正常显示。具体怎么牵连,怎么影响,错误显示成什么样,由很多因素决定:如还加载了其他什么词库?这些加载词库的前后排列顺序?词典软件用的是什么是哪个版本,等等。而即便词库的HTML,CSS完美无误,词典软件仍可能显示出问题。词典软件是一个大型软件,和其他软件一样都有BUG,这些BUG往往只在某些特定且无法预知的时候才会显现。一切BUG源于一般用户都要同时打开好多词库,而这些词库的HTML,CSS,尤其是javascript之间要想彻底隔离开而不相互影响,非常难做到的。无论GoldenDict, 欧路还是MDICT,没有任何一个词典软件能做到100%隔离而不相互影响,即便从理论上看起来似乎“不难“。
1 个赞
Python成"标配"了?看起来我有必要学学了。我只会Java和C#,而且一直用C#做词库,个人感觉C#正则库在所有语言中最为强大没有之一吧,如果学习C#应该比Python更容易做词库的。
哈哈, 可能hua大是在跟我打趣, 都很厉害
不仅看语言本身的能力,也要看语言周围的生态。还有就是自己熟悉什么就用什么。正则还是有很多局限的。