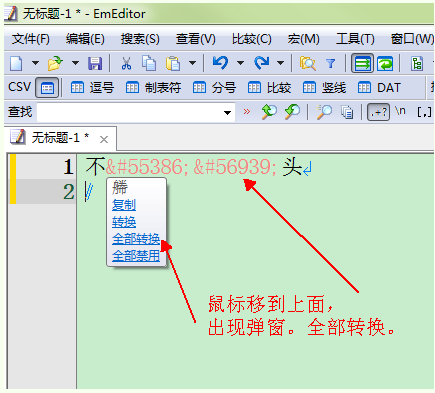
坛子里的汉语方言大词典的词头有很多生僻字都用的是&#打头的编码 (html?),没办法检索。粘贴到搜索引擎里试了一下,点击搜索后会自动转成Unicode. 比如不��头,搜索框里自动变成了不𦩫头。
有没有办法可以批量替换成Unicode啊?或者有&#到Unicode的列表也行。
搜了一圈,这个好像叫html entity,用的是UTF-16十进制编码
emeditor有个html/xml reference to Unicode可以批量转换,但是emeditor只有windows版,虚拟机太卡了。有没有不依赖于windows的解决办法?
emeditor 诚可贵,windows价更高,若为自由故,二者皆可抛?
lilysirius:
&#打头的编码
&#后是十进制u码 ,把它转换为十六进制就是标准的u码
研究了一下,html entity的编码是utf-16be十进制,先转化成了十六进制,再转化成bytes类型,最后decode就可以了
在python中,把html entity的编码放入string,用下面的函数就可以了。
def convHTML(string):
hexL = [hex(int(c.strip('&#;'))).replace('0x', '') for c in string.split(';&#')]
return bytes.fromhex(' '.join(hexL)).decode('utf-16be')
谢谢推荐!不过新版的那个还是有不少问题,我随便找了一个原版是PUA的词头,𰽫𬙒,第二个字写的是,不是unicode,我这边显示也不对
𬙒是扩展E的字,真可能还是继续PUA,只是没放在基本平面的PUA。Unicode最后两个平面(U+Fxxxx、U+10xxxx)也是PUA專区。
alexpeng收了这个新版吧?可以把mdx发出来供参考吗?只需要mdx,不需要mdd。
我把旧版导入过Access,不过有许多无法检索的词头很讨厌,得空想整一下。
找了一圈,您看看是不是这个。漢語方言大詞典.mdx (3.3 MB)
劳烦翻找文档和辛苦上载,非常感谢。
把mdx内的说明贴出来,供有兴趣的书友参考:
1、感谢klwo2制作的原词典。
评论:
1 “万一切掉部分内容”是可能的,所以本坛旧的K大原整页版,还是比较让人放心的版本。
2.拼音索引对方言词典大大有用。因为很多字只知其音,不知其字。
3.新版更改的词头未必全对,但是要改旧版的词头时,检索新版,再对图像,改起来肯定会比较快。
对哦,还有个字体 漢語方言大詞典.ttf (2.0 MB)
不过这个词典并不显示字词头,这个字体用来干嘛的呢?看了一下,里面有宋体也有楷体,仅有5100余字。
我也不知道。不过先收起来,得空再研究吧。
方言的生僻字字型,说不定有用?
26-6-2023补充:
求汉语方言大词典–许宝华(切图版)
《汉语方言大词典》知网版、mdx图像索引版都掉了“曱甴”这个词 。