舒服员
2022 年10 月 25 日 04:56
1
又开始搞词表了, 我想看看这些词表, 在实际作品中的覆盖情况. 随机找了10本书.
文本
.
|-- A Game of Thrones 5-Book Bundle - Martin George R.R.txt
|-- A Short History of Nearly Every - Bill Bryson.txt
|-- Animal Spirits - Shiller Robert J.txt
|-- Guns Germs and Steel - Jared Diamond.txt
|-- His Dark Materials The Complet - Philip Pullman.txt
|-- Surely You're Joking Mr. Feyn - Richard Phillips Feynman.txt
|-- Tender is the Night - Francis Scott Fitzgerald.txt
|-- The Economist Magazine the Worl - The Economist.txt
|-- The Great Gatsby - Francis Scott Key Fitzgerald.txt
|-- The Selfish Gene 30th Annivers - Richard Dawkins.txt
将其中的单词取出来, 要求能在词典里找到.
首字母大写的单词如果有小写的存在则作为普通单词计算, 如没有则不统计.
连字符单词如词典里有则作为普通单词, 如没有则拆开.
会尝试还原单词, 使用的是目前评测准确率最高的lemminflect,
会尝试切换英美拼法, 使用的词典
会尝试"还原->切换", "切换->还原"这种组合
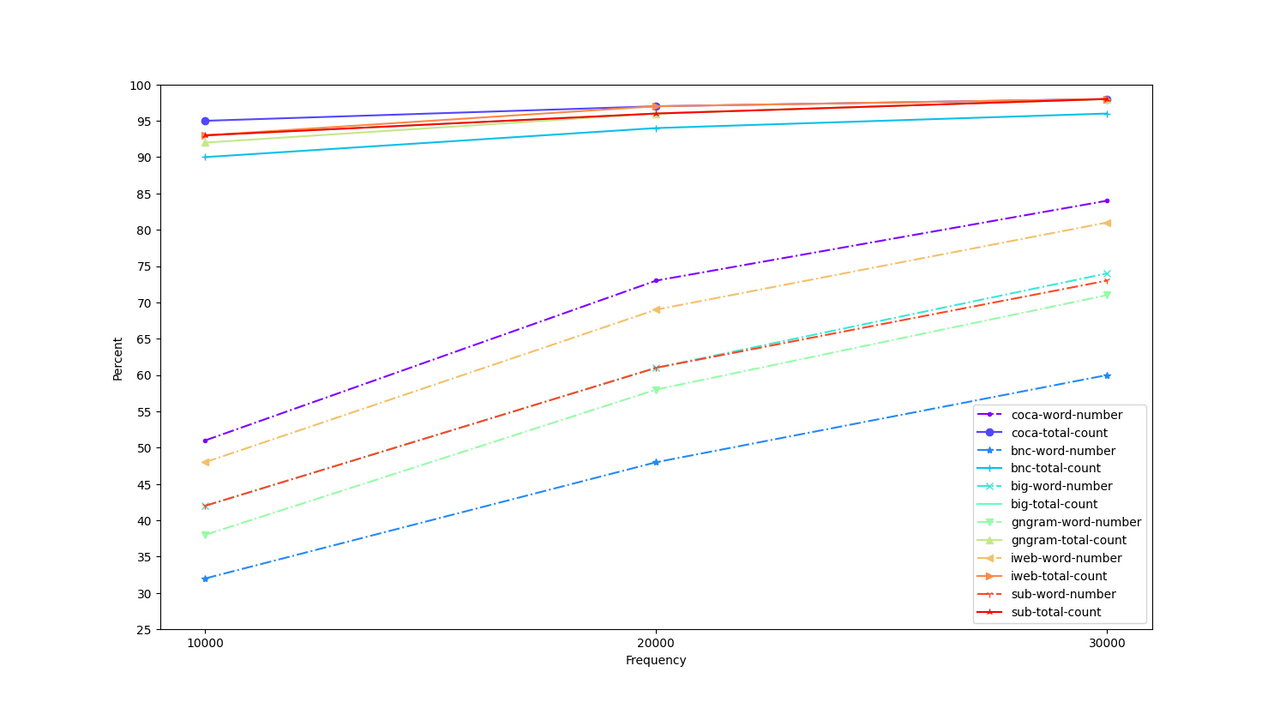
词频表
数量太大, 以1万开始, 每次加1万这样看. 其中的bigfreq是各个词频表合并的表.
Excel格式结果
ccald
bigfreq_527439,99,99,527439
bigfreq_520000,99,99,520000
bigfreq_510000,99,99,510000
bigfreq_500000,99,99,500000
bigfreq_490000,99,99,490000
bigfreq_480000,99,99,480000
bigfreq_470000,99,99,470000
bigfreq_460000,99,99,460000
gngram_458343,99,99...
这个应该是最终版本了.
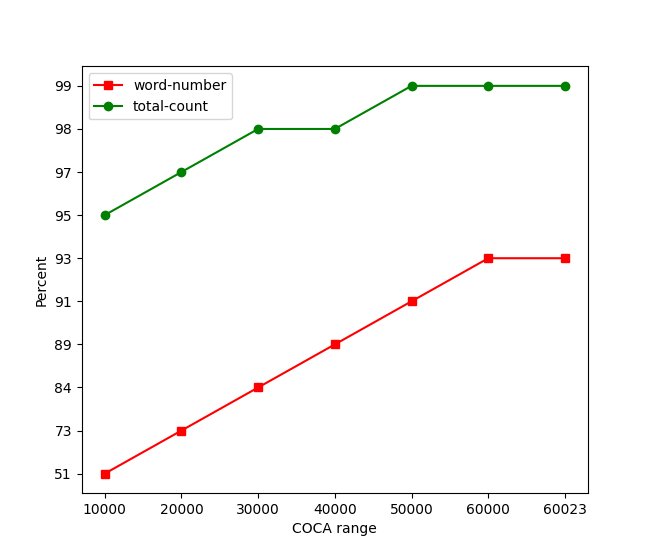
我挑了个效果最好的COCA做了一个图.
到3万时, 字数覆盖率停了…
前三万对比
词表下载
mdict6
2022 年10 月 25 日 04:57
2
牛批,这个特么不是词汇学课本上说的词典学的教授做的事情吗,神奇
说明参照词表的来源可靠性,结果发成电子表格更清楚,更有价值
舒服员
2022 年10 月 25 日 05:06
5
我当然记下了那些没有的词是什么, 文字太多, 超出一个帖子限制.
52万也没有的词
maester
这统计挺有意思的的。
舒服员
2022 年10 月 25 日 05:14
7
来源只能说是网络收集.
部分词表是这个帖子提到的: 分享若干词表:大学四级,六级,专四,专八,toefl,oald,gre,coca,
词频表的iweb是坛友分享给我的官网 下载的
后面数字是百分比吗?
舒服员
2022 年10 月 25 日 05:30
11
莫慌, 一开始我也震惊到了, 仔细看了一下, 问题不大.
这里是biglist 2万没有的词 FreeMdict Cloud
主要是专有名词, 形态变化词, 少量的错误词, 真正没覆盖的词是较少的.
一共是一万八左右, 我忘记统计这10本书的总单词数了, 我最开始统计出现5次以上的单词, 最后才改成统计出现2次以上的, 这其中我发现, 从4次到5次就能过滤掉一万左右的单词.
也就说这10本书38000的单词出现了2次以上, 其中有一万左右的单词只出现了5次以下.
嗯,我也发现大部分都是姓名啥的,应该想办法排除掉吧,比如干掉有大写的。你用重复次数是排除不掉的,因为一本书里往往姓名的重复次数反而是最高的。
matter
2022 年10 月 25 日 05:36
13
网上现有的词表,没有一个是根据学习者自己的情况做学习范围划分的。其实对学习者而言,更有意义的是学习者自己的“已记熟词表”和“不熟/生词表”,两个表范围根据自己的需要定,并在学习中不断动态调整。
推荐试试这个离线网页版的类蒙哥阅读器,可以动态调整自己的两个词表:
分级显示之前有一个思路,就是在用户自定义词表中汉语释义前显示所属考试/词表范围,就像欧陆那样会更直观一些,The Little Dict 里面都有这些数据。这样可以一个词表搞定。本来想做,闲麻烦又没啥空。
现在的方案也不错,就是需要用户记住分级词表对应的颜色。应该可以用 css的:after 方法实现文字范围显示,等我有空自己试试
舒服员
2022 年10 月 25 日 05:41
14
重复次数是为了排除干扰的非单词项目, 专有名词应该不需要过滤吧, 这些也能反应真实情况
专有名词是需要排除的,因为你的目的是为了测试掌握多少词汇量可以无障碍阅读。而词典里是会收录姓名的,但是我没背过这个姓名完全不影响我阅读。
专有名词(主要是姓名)在我看小说前用生词提取软件提取生词背诵时就发现了。基本上现有的生词提取器都会把所有单词转小写,然后提取,虽然有些软件考虑到了词形变化,但是基本上不考虑姓名,造成很大的干扰。比如我知道Harry Potter是个人名就行了,并不需要先背harry是掠夺、折磨的意思,也不需要知道potter是陶工,这两个词都是词频2万左右。虽然有的作者会在姓名上玩花活儿,但说实话为此背一些冷僻词性价比太低。
舒服员
2022 年10 月 25 日 06:10
18
可以重新写一个,这次再记录总单词数和真覆盖率,现在算是独立单词覆盖率吧。
误伤不可避免,但我觉得不会太多。比如一个词不是专有名词,因为句首大写被剔除了,如果该词是常用的,总会出现一次不在句首的情况从而被收录,极少有每次都是句首被误删的情况。
其实我觉得2次以上这个排除造成的误杀可能更多。。似乎没有必要,只出现1次也不能说就不是生词了。反正有词典验证在,干扰词不会造成大影响。