鸿雁输入法经过重大升级,在整句输入上做到物理上的极致优化。
首先是语料库的升级。目前的语料库有150GB,包含702亿个字符,有效汉字字符380亿个。
其中:
epubee整站电子书5.3万本,65.6GB
全网能找到的所有微博语料,38.6GB
百度百科500多万条,15.6GB
中文维基百科全部条目,10.1GB
各类新闻语料,12.6GB
微信公众号语料,2.9GB
联合国平行语料库中文部分,1.4GB
1946年-2003年人民日报全部数据纯文本,3.1GB
腾讯的自然语言处理研究开源了一个大规模中文词向量: 提供在300亿词的语料上训练的、包含8百万词汇的中文词向量数据,向量维度为200维。
以腾讯的大规模中文词向量作为比较:
腾讯的大规模中文词向量是在300亿词的语料上训练的;鸿雁输入法的语料包含702亿个字符,有效汉字字符380亿个。
腾讯的大规模中文词向量包含8百万词汇(最新版是1200万);鸿雁输入法包含的词汇量是2471万,而且这个数量刚好位于有序与无序的临界点。也就是超过2471万的词汇量对词语的质量没有太大提升,反而会浪费储存空间。
腾讯的大规模中文词向量依赖于结巴分词这样的分词软件,会出现分词不完全的情况;鸿雁输入法的分词采用的是机械分词,不会遗漏任何一个可能的词汇,并且从2-16个长度的词语全部进行统计。
腾讯的大规模中文词向量语料如果猜测的没错的话,主要是来源于网页抓取;鸿雁输入法同样大部分也是来源于网页抓取,不过数量更加庞大,选择的语料库是经过精心挑选的,具备典型性。
腾讯的大规模中文词向量底层采用word2vec技术,将分析的词语赋予一个多维空间的向量,依据向量的空间距离可以获得不同词语的相似度;
近距离语义分析,只有在切换输入法的情景才会有效,腾讯的语料库嵌入数据集,1200万的词条解压后,100维的版本有12GB,200维的版本有22GB,占用空间太大。而且需要相对复杂的余弦相似度运算。
如果要把腾讯的大规模中文词向量用于输入法,还需要调整算法,对一个已知词语的前面和后面的词语进行关联概率统计,概率模型是马尔可夫链。
鸿雁输入法基于词频统计的最大概率排序,同样可以对千万级的词汇进行统计。如果把2-4个字的词语前后组合排列,就构成一个更大的词语。在不考虑中文语法规则得情况下,把一个句子当作一个词语,和词语一样,按照语料库的出现概率大小进行排序,同样可以实现整句输入的效果。只要保证足够大、足够全面的语料样本,语句按照词语分割后,按照所有分词组合对应的概率排序,就可以获得质量相当高的整句输入法。鸿雁输入法在语料库分析的时候,最大的词语长度是16,这个长度已经足以覆盖绝大部分中文语句的使用场合。
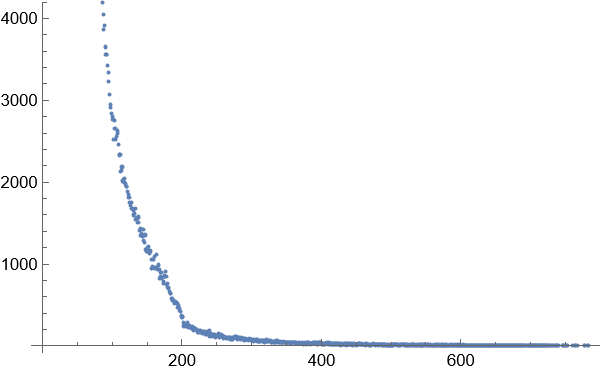
下图是不同长度的词语出现的数量横向对比图
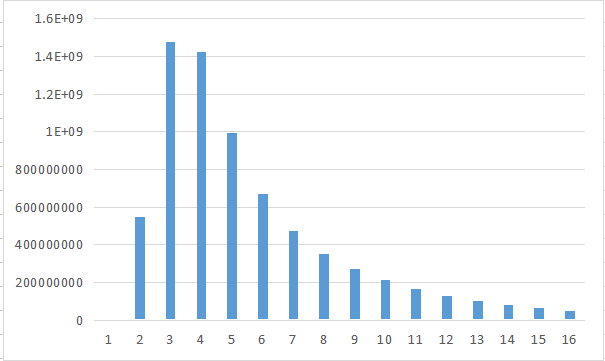
根据上图可以看出,中文词语在超过8个字的长度,比例大幅减少。中文词语的长度主要集中在2-6个字。
在对702亿个字符的语料库统计后,获得70亿个词语的数据,约为63GB。
下面就面临一个高频词语的选择问题。
一个输入法包含70亿个数据,显然这个数据过于庞大。
如果选择的高频词语数量过少,那么输入法的词语准确率就会偏低。
如果选择的高频词语数量太大,因为各种原因产生的错误的词语就会增多。
选择高频词,需要兼顾数据储存空间的效率和语义复杂度的涵盖率。
有一个简单的办法:
1.把702亿个字符的语料库分割成791个区块,统计出现同一个词语的区块数量。区块数是1-791,而最常见的词语数量数以亿计,最罕见的词语数量只有1。使用区块数代替词语数量数,可以将数值缩小在一个相对均匀的范围内。
2.把区块数目相同的词语看作一个集合,并统计这个集合的词语数量,这样就得到一个类似于直方图的统计图
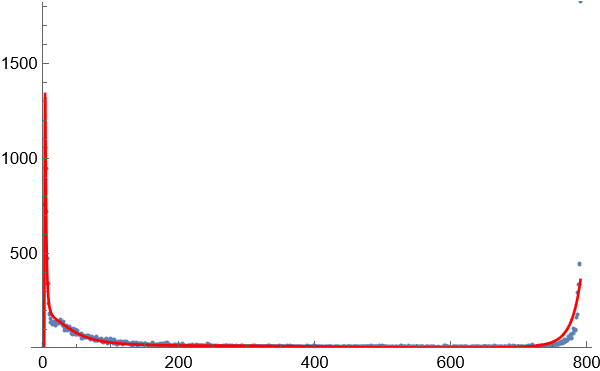
3.得到图像显示,在这种方式下的词频关系图并不是完全和长尾效应完全一致的,而是一种泊松分布和指数增长的结合体。这在2个字的词语统计分布图中尤为明显。随着词语长度的增加,高频词的出现次数和比例大幅度减小,低频词的出现次数和比例随着词语的长度增加而大幅增长。相对高频的词语位于这个与长尾效应类似的曲线尾部和中部。
1 单个字
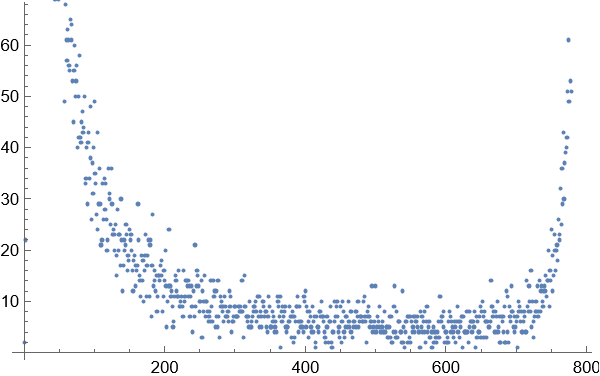
2 个字的词语
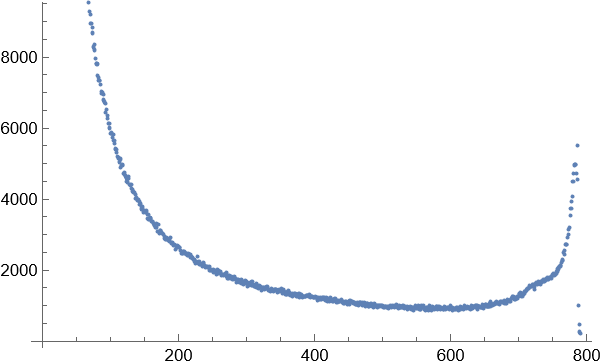
3个字的词语
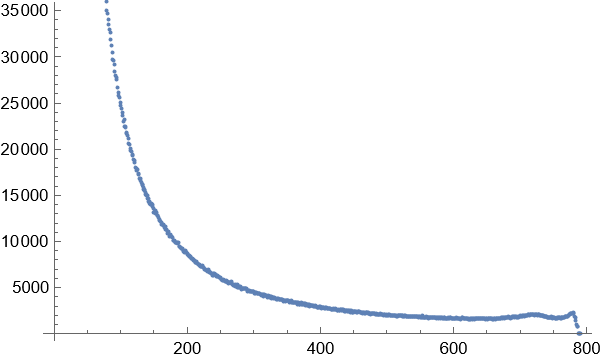
4个字的词语
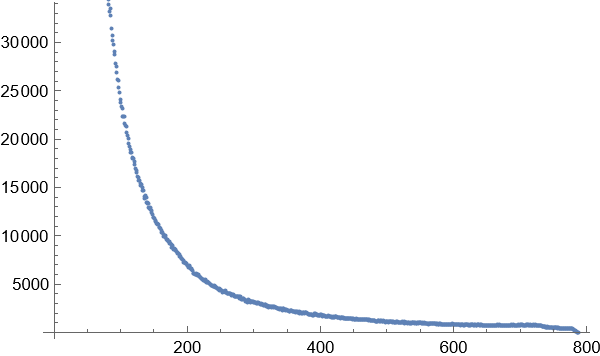
5个字的词语
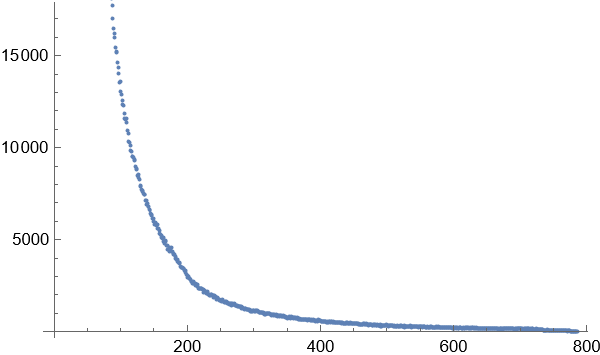
6个字的词语
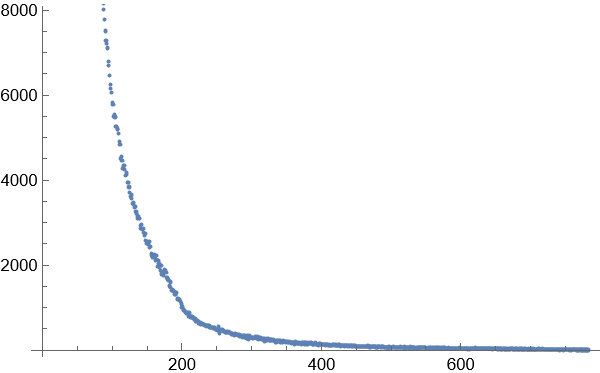
7个字的词语
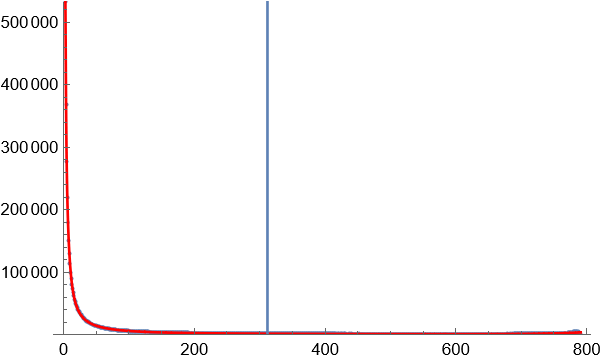
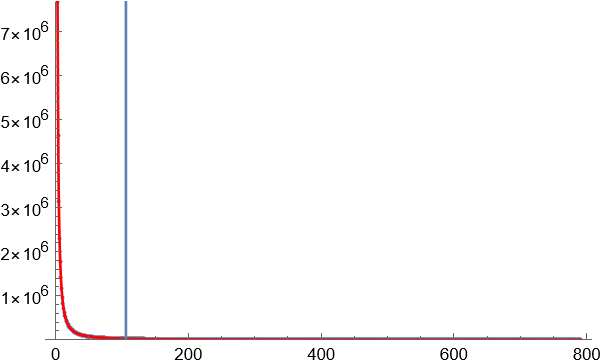
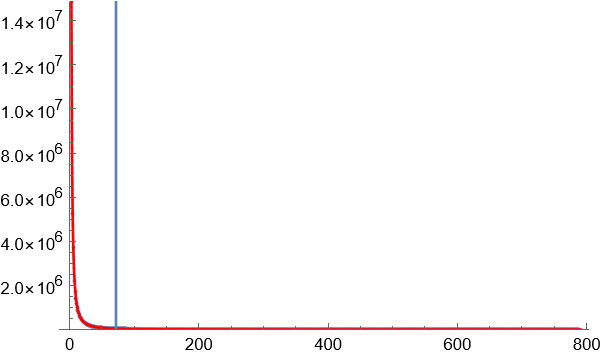
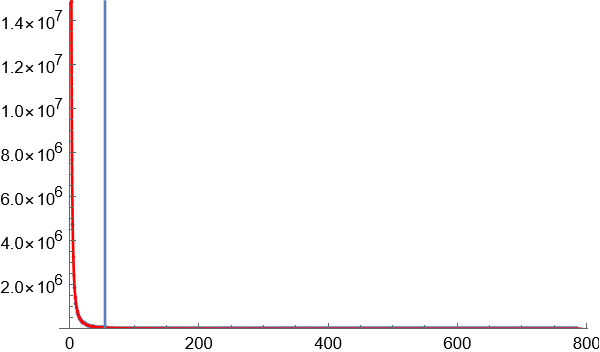
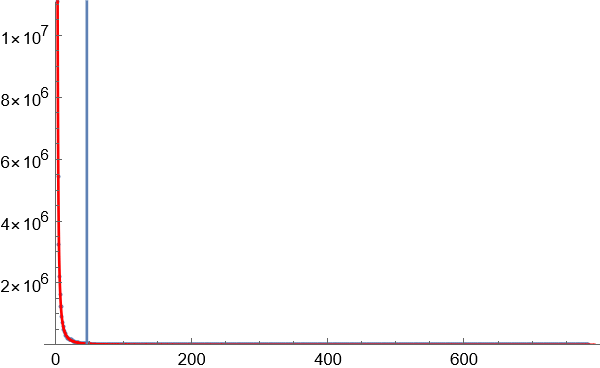
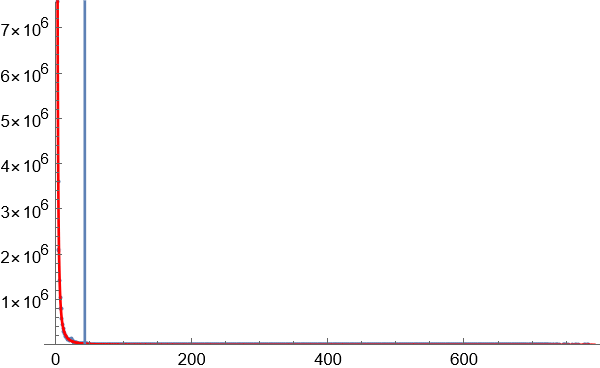
4.以区块数量的某一数值作为边界,对70亿个词语进行数据缩减,只保留相对高频的词语。大部分图像显示为长尾图,横轴代表区块数量,竖轴代表同一区块数量对应的词语数量。横轴越小,斜率越大,说明因为词语对应字的排列组合导致无序效应在罕见的词语中越来越明显。为了覆盖足够高的语义复杂度,只需要计算曲线斜率最大值按照一定比例缩小后对应的点,就是无序与有序的临界点。
临界点的斜率是曲线最大斜率的固定比例的关系,如果选择比较合适的临界点处,语义复杂度正在增长,还没到无序到不受控制的增长程度。
临界点选择,使用暴力穷举法,试用不同的比例参数,可以看到,在选择某个参数附近后,分割获得的高频词语数量增长趋于稳定。这个参数就是理想的分割参数。
下图显示通过实验获得的理想参数下的临界点位置:
1 单个字
2 个字的词语
3 个字的词语
4 个字的词语
5 个字的词语
6 个字的词语
7 个字的词语
15 个字的词语
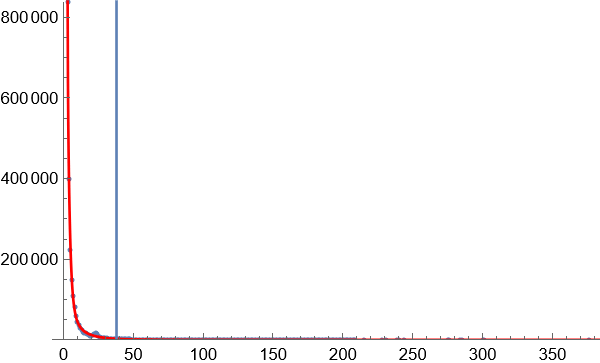
16 个字的词语
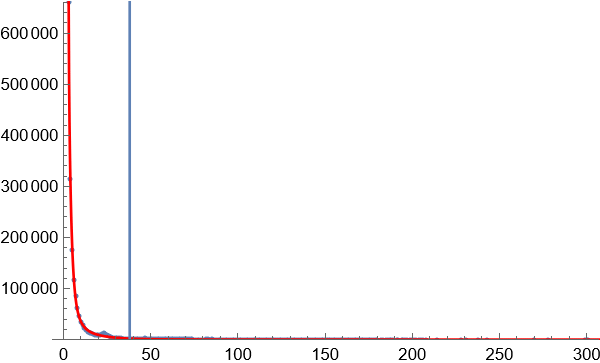
使用临界算法初步获得约为2400万的词语。
加入其他高权词库,合计2471万。
这个数量级别的词库,到底整句输入法准确率怎么样呢?
上图
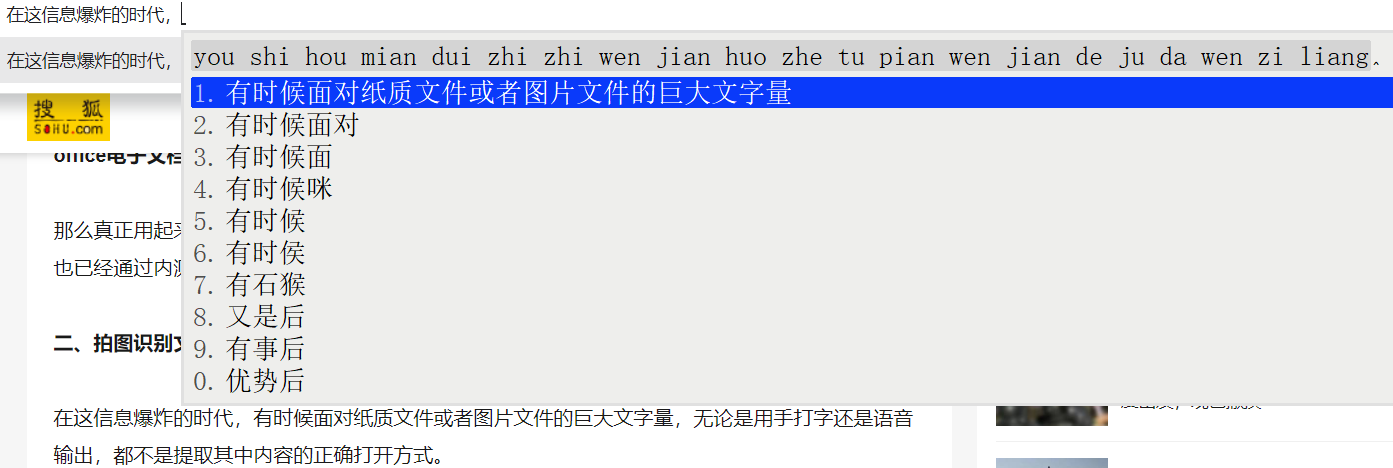
使用搜狗拼音,同样可以打出正确的语句。
值得注意的是,搜狗输入法是经过高度算法优化的,一定包含中文语法逻辑。
而鸿雁输入法仅仅是采用rime输入法的整句引擎和1-16个字长度的词语概率统计。rime输入法的整句引擎的算法没有仔细看,应该是基于拼音不同拆分,对应的语句组合相应的概率进行优先级排序。
对于底层细节的了解,作者就没有进行更多的整句测试。有兴趣的可以打开中央电视台,按照电视台播音打出语句,测试准确度怎么样。
包含2471万词语的鸿雁输入法并没有采用中文语法算法的引擎,仅仅依靠庞大的词语频率统计,在整句输入功能上已经和搜狗输入法不相上下(这只是个人的看法,是否真实需要广大网友的验证)。
在鸿雁输入法之前的描述,可以得知,鸿雁输入法自带的单字拼音库,是目前互联网上公开的最为准确的拼音库。
原来词语的拼音采用暴力穷举的方法,正确的拼音一定有,但是还存在大量的字的拼音是正确的,词语的拼音确是错误的情况。最近,使用现代汉语词典的数据对词语拼音大幅优化,这种情况大大改善。
同时优化了国家拼音标准移植到rime输入法后存在的缺陷。
更改特殊拼音
㕶 n ng 呒 fu m 呣 m mou 哏 gen hen n 哼 heng hng 哽 geng ng ying 唔 m n ng wu 嗯 n ng 嘸 fu m wu 噷 hen hm xin 姆 m mu
n → en
m → mu
hng → heng
ng → en
hm → hen
在单个字的拼音存在多个声母后,使用rime输入法相关的拼音输入会出现优先级被这些特殊的拼音占用的情况。
在从底层消除这些特殊的拼音后,这种情况将彻底消失。
以前输入ng,“那个”这样的词语将不会出现在候选列表,除非输入“nge”或者其他组合。
“n”“m”作为拼音的首字母输入的时候,以前不能显示“你”“们”这样的词语,现在这种情况将不复存在。
鸿雁输入法同时优化了rime输入法另外一个缺陷。
rime输入法有两个拼音输入引擎,一个是基于词语的,另外一个是基于语句的。
词语引擎不能支持整句输入,整句输入引擎使用空格作为分词的按键,这个设计并不合理。
一般用户都习惯使用空格键作为上屏的按键,因为这个按键尺寸最大,而且可以说是跟手距离最近的按键。使用空格分词对词语输入转确率提升不大,使用空格上屏需要按两次,这会影响输入舒适度的设计。一般拼音分词,如果前面的词语出现错误,可以使用TAB键或者退格键进行词语重新选择。
稍微修改了一些rime输入法的源代码,空格键去除分词功能,改为上屏键。
鸿雁输入法包含五笔、全拼、双拼方案。理论上五笔方案应该重码率更低,也支持整句输入,输入体验更为流畅,作者不懂五笔,有待广大网友的测试。
下图是搜狗输入法和鸿雁输入法语义复杂度的对比,以拼音“jidong”为例:
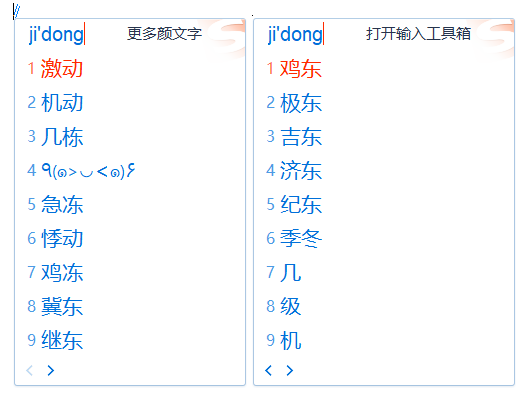
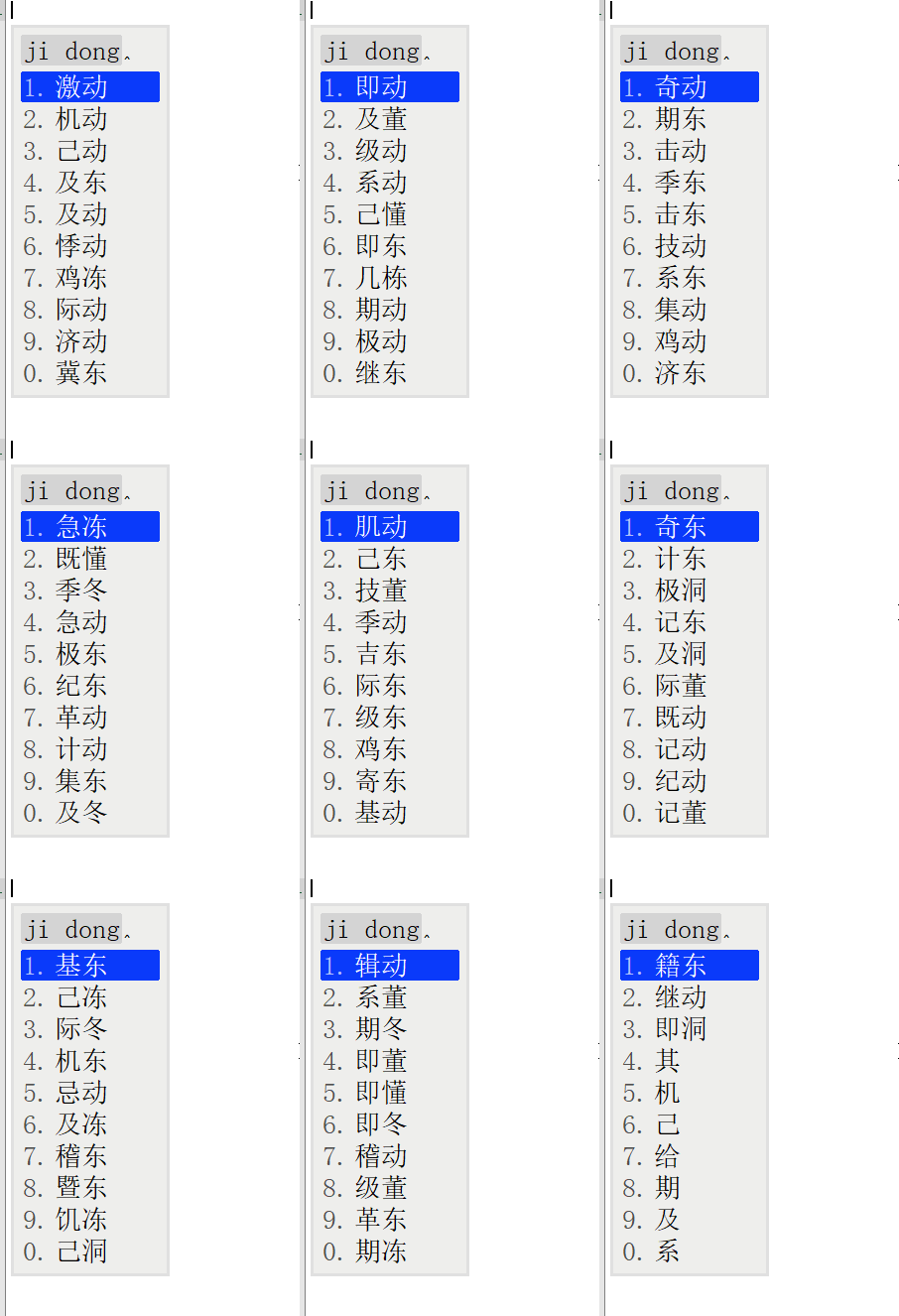
搜狗输入法仅有14个候选词语;鸿雁输入法有83个候选词语。
这只是随机抽取的词语,如果遇到罕见的拼音,那么一定会出现搜狗输入法不能打出的拼音,而鸿雁输入法可以打出的词语。
候选词语数量,上面的例子约为六倍,候选词语倍数是十倍,二十倍的应该是存在的。
输入安装包仅仅包含262万的一个轻量版的词语,这是因为windows平台的rime输入法支持最大数据量有限,超过一定数据量将无法生成索引。
在linux平台可以成功生成2471万的索引,这个索引拿到windows平台和安卓平台都可以使用。
用户需要注意,如果轻量级的词库不能满足实际输入中的准确度需求,需要安装另外一个“预编译词库索引(拼音、五笔)_2471万词语增强包”。
在linux平台生成词库索引需要22.2GB的内存
输入法安装包自带262万轻量级词库生成的词库索引
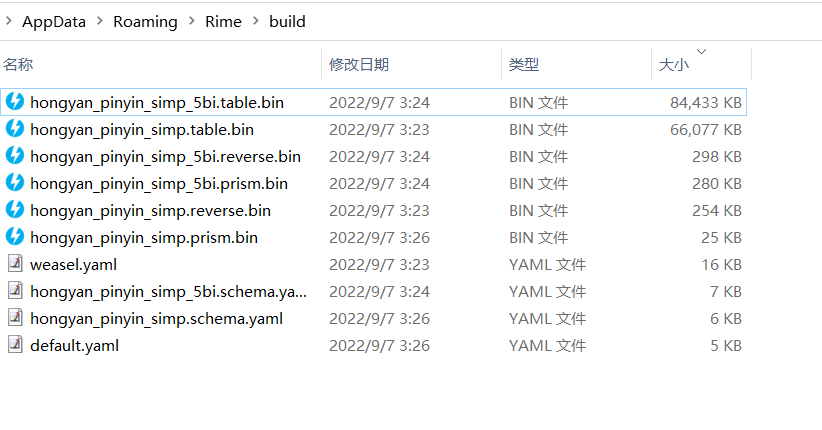
安装“预编译词库索引(拼音、五笔)_2471万词语增强包”后的词库索引
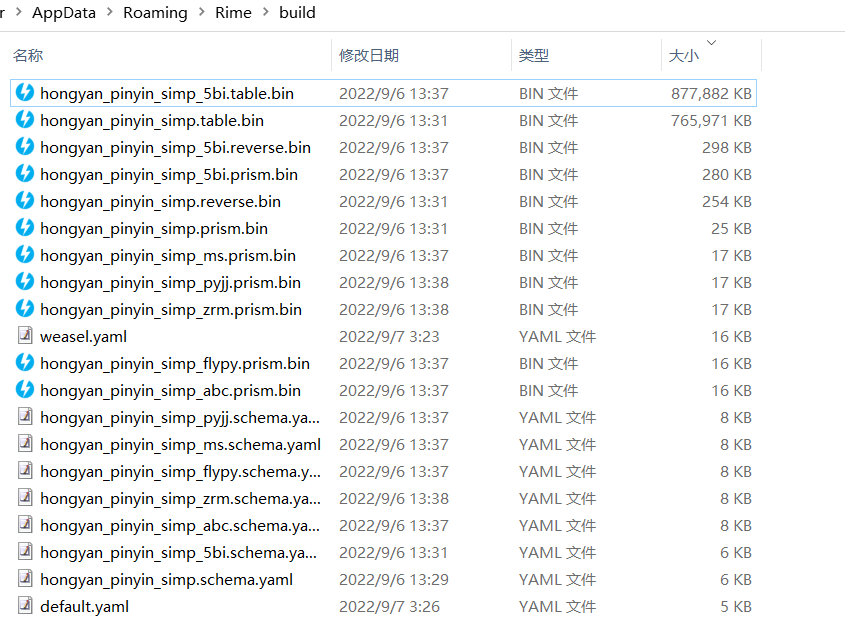
可以看到词库索引从80多兆上升到800多兆
希望鸿雁输入法能够成为文字工作者、学生、老师、社会各界人士常用的输入法软件。
以上,从技术细节和理论上说明了鸿雁输入法更懂中文,具体实际使用中的体验是否能够达到预期,还需要广大网友的亲身体验。
下载链接:
https://hong-yan.lanzouw.com/b00vvkivc
密码:1234
腾讯词库+鸿雁词库的交集 鸿雁拼音腾迅测试版·全拼 见118楼